Существующие подходы к решению задачи факторизации больших чисел (ЗФБЧ), интенсивно используемые в мире математики последние 20-30 лет свидетельствуют, что для них эта задача достаточно сложная, она упорно сопротивляется внешнему натиску специалистов и позиций не сдает. Вместе с тем, не могу упомянуть работ, авторы которых предложили бы глубокий анализ проблемы, состояния вопроса или выступили бы с критикой используемого подхода. Основной принцип в подходе — просеивание множества чисел (принцип решета) доминирует в этой области, но думается это не единственный путь и возможно не лучший. Большие надежды исследователями ЗФБЧ возлагаются на вычислительные средства новых типов, на новых физических принципах (квантовые, молекулярные и др.), но о смене подхода речь не идет. Тем не менее, некоторые выводы уже сегодня как бы напрашиваются сами собой. В атаках на RSA-подобные шифры ЗФБЧ является основной задачей.

Андрей @andreypaa
User
Заставьте сайт работать на сенсорных устройствах
8 min

Сенсорные экраны на мобильных телефонах, планшетах, ноутбуках и настольных компьютерах открыли веб-разработчикам целый ряд новых взаимодействий. В переведенном руководстве Патрик Локи рассматривает основы работы с сенсорными событиями в JavaScript. Все рассматриваемые далее примеры есть в архиве.
Вероятностные модели: сэмплирование
10 min
Tutorial
И снова здравствуйте! Сегодня я продолжаю серию статей в блоге Surfingbird, посвящённую разным методам рекомендаций, а также иногда и просто разного рода вероятностным моделям. Давным-давно, кажется, в прошлую пятницу летом прошлого года, я написал небольшой цикл о графических вероятностных моделях: первая часть вводила основы графических вероятностных моделей, во второй части было несколько примеров, часть 3 рассказывала об алгоритме передачи сообщений, а в четвёртой части мы кратко поговорили о вариационных приближениях. Цикл заканчивался обещанием поговорить о сэмплировании — ну что ж, не прошло и года. Вообще говоря, в этом мини-цикле я поведу речь более предметно о модели LDA и о том, как она помогает нам делать рекомендации текстового контента. Но сегодня начну с того, что выполню давнее обещание и расскажу о сэмплировании в вероятностных моделях — одном из основных методов приближённого вывода.

Изучаем PHP изнутри. Zval
10 min
Эта статья базируется на главе Zvals книги PHP Internals Book, переводом которой на русский язык я сейчас занимаюсь [1]. Книга ориентирована в первую очередь на C-программистов, желающих писать свои расширения для PHP, но, я уверен, что она окажется полезной и для PHP-разработчиков, так как описывает внутреннюю логику работы интерпретатора. В статье я оставил только базовую теорию, которая должна быть понятна всем разработчикам (даже не знакомым с PHP или C). За более полным изложением материала обратитесь к книге.
Задачка для привлечения внимания. Каким будет результат выполнения следующего кода?
Если вы точно определили ответ и можете объяснить почему он будет именно таким, то, наверное, вы не узнаете из этой статьи ничего нового, иначе — вам определенно стоит прочитать эту статью, чтобы углубить свои знания.
Задачка для привлечения внимания. Каким будет результат выполнения следующего кода?
$obj1 = new StdClass();
$obj2 = new StdClass();
$obj1->value = 1;
$obj2->value = 1;
function f1($o) {
$o = 100;
}
function f2($o) {
$o->value = 100;
}
f1($obj1);
f2($obj2);
var_dump($obj1);
var_dump($obj2);
Ответ
object(stdClass)#1 (1) { [«value»]=> int(1) }
object(stdClass)#2 (1) { [«value»]=> int(100) }
object(stdClass)#2 (1) { [«value»]=> int(100) }
Если вы точно определили ответ и можете объяснить почему он будет именно таким, то, наверное, вы не узнаете из этой статьи ничего нового, иначе — вам определенно стоит прочитать эту статью, чтобы углубить свои знания.
Обзор наиболее интересных материалов по анализу данных и машинному обучению №1 (9 — 16 июня 2014)
3 min

Данный выпуск дайджеста наиболее интересных материалов, посвященных теме анализа данных содержит достаточно много статей, которые рассматривают теоретические аспекты вопросов, связанных с Data Science. Есть несколько статей, которые будут интересны новичкам. Также представлены ссылки на серию интересных статей о работе со схемами данных в MongoDb. Есть несколько ссылок на материалы, в которых рассматривается важная проблема переобучения (overfitting) в процессе машинного обучения. Некоторые статьи посвящены литературе, рекомендуемой к прочтению для тех кому интересна тема анализа данных.
Лучшие свободные моноширинные шрифты с поддержкой кириллицы
2 min
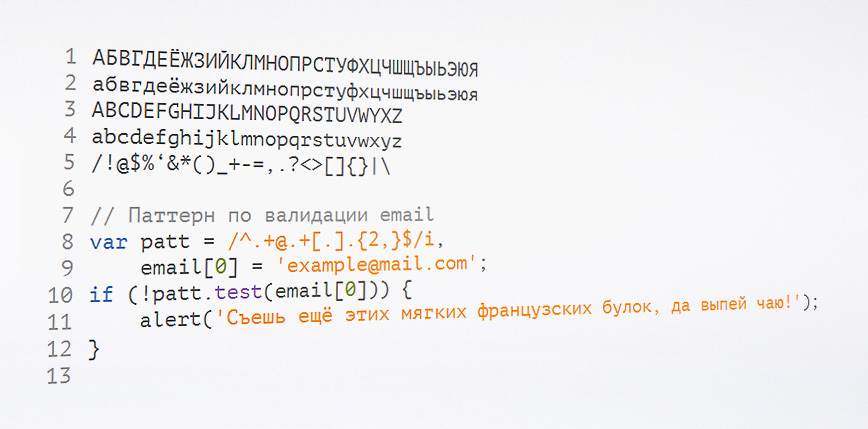
В 2011 году была переведена хорошая статья „Лучшие шрифты для программирования“. Теперь представляется список самых удачных шрифтов для кода на момент июня 2014 года.
Хотя я и уверен, что многих устраивает Courier New, используемый по умолчанию в Windows во многих редакторах. Но, как человек любящий типографику, настаиваю обратить внимание на одну из гарнитур из этой статьи. Хороший шрифт — это прекрасно!
Проверка SSD на выносливость: запись 1 петабайта
2 min

Компьютерное издание The Tech Report в августе прошлого года начало тестирование SSD-накопителей. Цель — проверить, сколько циклов перезаписи выдержит каждый из шести экземпляров. Эксперимент продолжается до сих пор: после записи 1 петабайта в живых остались три накопителя.
Вводная по сложным запросам в SQLAlchemy
7 min

Во время посещения PyConRu 2014 я, с удивлением, узнал, что достаточно большая аудитория python-разработчиков не использует SQLAlchemy в качестве основного инструмента для работы с базой данных. Порассуждав на данную тему после Light Talks с коллегами было принято решение — во чтобы то ни стало написать статью о том, что же можно делать со всей мощью SQLAlchemy.
Обычно в написании сайтов не требуется чего-нибудь этакого от штатного ORM. А если и требуется, то хватает замены на нештатный или прочтения основной части документации. И, как правило, голову ломать над сложными запросами не приходится. Достаточно много различных ORM предлагают классические схемы One-2-Many, One-2-One, Many-2-Many, и т.д. Для обычных запросов и связей этого вполне достаточно. К сожалению, в больших проектах не обходится без частных случаев и программисты при сложных запросах пишут либо raw sql, либо полагаются на то, что им предлагает базовый функционал ORM. Это выглядит не совсем красиво или создает достаточно большую нагрузку на базу данных.
Понятно, что в погоне за скоростью выполнения сценариев, можно пожертвовать красотой кода, но что если скоростью можно пренебречь, а вот кроссплатформенностью — нет? Да и не хочется в python коде видеть что-то кроме python кода. А что если хочется на полную катушку использовать любимый ORM (для меня SQLAlchemy) и не писать raw sql запросы?
Простой способ сделать из обычного текста продающий
3 min

Чтобы клиент оценил все прелести вашего предложения, он должен прочитать об этом на вашем сайте. Проблема в том, что тексты в вебе пользователи игнорируют все чаще — избалованный графикой взгляд предпочитает цепляться за красивые картинки и пиктограммы, все большее значение приобретает форма подачи. Если посетитель сайта дочитал текст, вероятность заказа возрастает в несколько раз. Как привлечь посетителя к тексту и помочь прочитать? Нужно сконцентрироваться на самом важном, правильно расставить акценты, красиво оформить и пригласить к действию. Почему если это все понимают, никто (или почти никто) не уделяет этому внимания?
Многим сложно сформировать у себя в голове четкую и красивую структуру текста и воплотить ее на сайте средствами панели управления. Именно для них мы сформировали простой шаблон. Вставляете его в WYSIWYG-редактор, заменяете текст, картинки — и вуаля!
Безопасность покупателя в рознице: что надо знать лично вам
6 min

Ценник должен быть с печатью или подписью. Он является документом и обязательно должен быть на товаре. Если вы видите что-то с ценником (неважно, где и как оно стоит), вы имеете право купить его по цене на нём.
Пример: вам говорят, что товар по акции кончился. Вы видите один в витрине в герметичном ящике под потолком, но с ценником. Вам не имеют права отказать в его продаже.
Второй пример: когда обновляются цены, в торговом зале может остаться ценник со старой ценой ниже. Цена в базе другая? Ну и что, вот ваш же документ. Если же вдруг ценник без печати-подписи, и на таком товаре нет правильного ценника — регистрируйте нарушение. Ценники обязательно должны быть хотя бы на одном товаре из пачки.
Про котиков, собак, машинное обучение и deep learning
15 min

«В 1997 году Deep Blue обыграл в шахматы Каспарова.
В 2011 Watson обставил чемпионов Jeopardy.
Сможет ли ваш алгоритм в 2013 году отличить Бобика от Пушистика?»
Эта картинка и предисловие — из челленджа на Kaggle, который проходил осенью прошлого года. Забегая вперед, на последний вопрос вполне можно ответить «да» — десятка лидеров справилась с заданием на 98.8%, что на удивление впечатляет.
И все-таки — откуда вообще берется такая постановка вопроса? Почему задачи на классификацию, которые легко решает четырехлетний ребенок, долгое время были (и до сих пор остаются) не по зубам программам? Почему распознавать предметы окружающего мира сложнее, чем играть в шахматы? Что такое deep learning и почему в публикациях о нем с пугающим постоянством фигурируют котики? Давайте поговорим об этом.
Обзор Windows-приложений для наведения порядка в фотоархивах
9 min
Задавшись вопросом найти все фотографии близкого человека, или разбирая фотки из похода, турпоездки и т.д. мы часто начинаем мониторить папки на компьютере. Однако, уже спустя час-другой многие бросают эту затею, пройдя меньше половины фотоархива и устав от поиска ненужных снимков среди сотен «Новых_папок_222» и десятков «DCIM».

Мы торопимся жить. Наши воспоминания складируются в папки, сливаются с флешек фотоаппаратов, синхронизируются cо смартфонов и… забываются. В этом обзоре постараюсь отметить сильные и слабые стороны приложений, доступных обычным людям с Windows, которые могут подарить нашим воспоминаниям вторую жизнь.
Мы торопимся жить. Наши воспоминания складируются в папки, сливаются с флешек фотоаппаратов, синхронизируются cо смартфонов и… забываются. В этом обзоре постараюсь отметить сильные и слабые стороны приложений, доступных обычным людям с Windows, которые могут подарить нашим воспоминаниям вторую жизнь.
Как научить игрока разобраться в вашем приложении, не сводя на нет работу художников, не обижая программистов и не считая игроков умственно отсталыми
8 min
Тут мне во дворе рассказали, что говорить “фри-ту-плэй” уже немодно. Если делаешь игру, в которой концепция монетизации “всё бесплатно, но за некоторые вещи я бы советовал вам заплатить”, то называй это “фримиум”.
Продолжая модный ликбез, скажу, что ещё сейчас делают немодно – туториалы (от английского tutorial – учебник) – то, как разработчики объясняют игроку, чем же ему можно заняться в приложении. К счастью, социальные и мобильные игры не сводятся исключительно к механике три-в-ряд, поэтому пользователю не всегда понятно, что же ему нужно делать для достижения нирваны. И сейчас большинство туториалов не выполняют своей роли.

— Это то, что видит игрок сразу после экранчиков загрузки, вступительного ролика и прочих неигровых элементов;
— Как следствие, плохой туториал – прямой путь к высокому проценту потери аудитории. Иными словами, бОльшая часть людей, запустивших игру уйдёт, так и не поняв, что же от них хотели;
— Если очевидные правила люди уловить способны (грядки нужно засаживать помидорами, замораживающий луч неэффективен против ледяных крокодилов), а туториал плох, то есть риск, что большая часть контента пройдёт мимо игроков. А это, с одной стороны, лишние трудозатраты, а с другой – весь выверенный баланс, кривая сложности и политика монетизации обрушивается. Например, игрок не понимает, где ему купить солдатиков, он вынужден убивать врагов, тратя золотые магические рубины – и в результате обиженно бросает игру с «зажравшимися разрабами, которые прямо со входа денег требует».
Теперь о том, какие туториалы знает современная геймдевелоперская наука:
К слову, я изучил туториалы верхних пяти игр в топах вконтакта и фейсбука, чтобы узнать типы туториалов, использующихся там и здесь. Ниже подробней рассмотрим перечисленные подходы.
Продолжая модный ликбез, скажу, что ещё сейчас делают немодно – туториалы (от английского tutorial – учебник) – то, как разработчики объясняют игроку, чем же ему можно заняться в приложении. К счастью, социальные и мобильные игры не сводятся исключительно к механике три-в-ряд, поэтому пользователю не всегда понятно, что же ему нужно делать для достижения нирваны. И сейчас большинство туториалов не выполняют своей роли.
Погодите, а почему туториал важен?
— Это то, что видит игрок сразу после экранчиков загрузки, вступительного ролика и прочих неигровых элементов;
— Как следствие, плохой туториал – прямой путь к высокому проценту потери аудитории. Иными словами, бОльшая часть людей, запустивших игру уйдёт, так и не поняв, что же от них хотели;
— Если очевидные правила люди уловить способны (грядки нужно засаживать помидорами, замораживающий луч неэффективен против ледяных крокодилов), а туториал плох, то есть риск, что большая часть контента пройдёт мимо игроков. А это, с одной стороны, лишние трудозатраты, а с другой – весь выверенный баланс, кривая сложности и политика монетизации обрушивается. Например, игрок не понимает, где ему купить солдатиков, он вынужден убивать врагов, тратя золотые магические рубины – и в результате обиженно бросает игру с «зажравшимися разрабами, которые прямо со входа денег требует».
Теперь о том, какие туториалы знает современная геймдевелоперская наука:
Виды туториалов:
- «Сами разберутся»
- «Мы умеем выдавать мессаджбокс»
- «Заблокированный экран и тайна затерянной стрелочки»
- «Чёрная амбразура ужасающей безысходности»
- «Мы можем всем объектам добавить ещё одну анимацию»
- «Направляющий луч»
К слову, я изучил туториалы верхних пяти игр в топах вконтакта и фейсбука, чтобы узнать типы туториалов, использующихся там и здесь. Ниже подробней рассмотрим перечисленные подходы.
Новая идея. Бешеная смесь Паука и 2048
1 min

Предлагаю Вашему вниманию новый пасьянс.
Для программистов и математиков.
Играю уже третью неделю, открываю все новые и новые комбинации.
Для тех кому лень читать — есть ссылка на 30-секундное видео игры.
Математика и игра 2048
7 min

Впервые игру 2048 представили на Хабрахабр здесь. Не прошло и пяти дней, как раскрыли тайну простой стратегии ее прохождения. Она действительно проста — нужно строить змейку из тайлов (как на картинке).
Однако понятная цель не всегда означает её легкое достижение. Мы с Mrrl по очереди делились своими успехами: слепили блоки 8, 16, 32 и 65 тыс. Теперь же мне удалось то, что я и сам не ожидал — собрать максимально возможный тайл в игре — 131 072 или 217, скопив свыше 2 млн очков.
Это вдохновило меня доработать и оформить в виде поста начатые ранее размышления об игре 2048. Речь идет не о стратегии и тактике прохождения, а о таких вопросах, как:
— действительно ли 217 является максимально возможным блоком?
— какое количество очков можно в принципе набрать по пути к неизбежному концу игры?
— сколько ходов позволяет сделать головоломка?
Чтобы разобраться понадобится немного математики…
Еще один 2048, теперь треугольный
3 min

В нашем клубе уже было описание игры 2048. Признаюсь, с первого раза игра мне не понравилась. Однако после прочтения следующей статьи, с подсказкой игровой стратегии, все изменилось. Я уверенно установил приложение 2048 на телефон и несколько раз сыграл. Родив через пару-тройку часов блок 8192, я затосковал и снес игру, решив сделать свой вариант. Вариант 1) нескучный и 2) для тупых.
Судя по отзывам приятелей и личному опыту, цель была достигнута. Приятелям мой вариант показался 1) нескучным, а для меня — 2) самый раз.
Срочно в номер. Только что review team одобрила игру. Как обещал, объявляю ее бесплатной с этой минуты на три дня, а там как кривая американской мечты вывезет.
.
Идеальная стратегия игры «2048»
1 min
Всем привет!
Как известно, математическую игру «2048», создал итальянский разработчик Gabriele Cirulli.
Игровое поле состоит из сетки 4х4.
Игра начинается. На сцене две плитки с номиналом 2.
Передвигая, нужно сложить плитки одного «номинала».
Движение возможно в 4 стороны.

Цель игры — собрать плитку с «номиналом» 2048.
Как известно, математическую игру «2048», создал итальянский разработчик Gabriele Cirulli.
Игровое поле состоит из сетки 4х4.
Игра начинается. На сцене две плитки с номиналом 2.
Передвигая, нужно сложить плитки одного «номинала».
Движение возможно в 4 стороны.
Цель игры — собрать плитку с «номиналом» 2048.
Изучаем Three.js.Глава 2: Работа с основными компонентами, из которых состоитThree.js-сцена
18 min
Tutorial
Translation
Всем привет!
В предыдущей главе мы познакомились с основами бибилиотекиThree.js. Увидели несколько примеров и создали свою первую полноценную Three.js сцену. В этой главе мы немного глубже углубимся в эту библиотеку и попробуем более подробно объяснить основные компоненты, составляющие Three.js сцену. В этой главе вы узнаете о следующем:
Начнем мы с того, что посмотрим, как же можно создать сцену и добавить на нее объекты.
В предыдущей главе мы познакомились с основами бибилиотекиThree.js. Увидели несколько примеров и создали свою первую полноценную Three.js сцену. В этой главе мы немного глубже углубимся в эту библиотеку и попробуем более подробно объяснить основные компоненты, составляющие Three.js сцену. В этой главе вы узнаете о следующем:
- какие компоненты используются в Three.js сцене
- что можно делать с объектом THREE.Scene()
- какая разница между ортогональной и перспективной камерами
Начнем мы с того, что посмотрим, как же можно создать сцену и добавить на нее объекты.
2048
1 min
19-летний итальянский разработчик Габриэле Чирулли (Gabriele Cirulli) создал чрезвычайно захватывающую игру 2048, скрестив тетрис и «пятнашки».

На каждом раунде в игре появляется две плитки с цифрой «2». Нажимая стрелки, нужно сбросить их в сторону, при этом плитки одного «номинала» складываются. Выигрыш засчитывается при достижении результата 2048.
На каждом раунде в игре появляется две плитки с цифрой «2». Нажимая стрелки, нужно сбросить их в сторону, при этом плитки одного «номинала» складываются. Выигрыш засчитывается при достижении результата 2048.
Простая стратегия игры 2048
1 min
Студентам физфака тоже было весело, поэтому мы придумали простую эвристическую выигрышную (по крайней мере, нам удалось набрать 2048 в 9 из 10 раз) стратегию этой игры.
Занумеруем идущие подряд столбцы (можно и строки, но в дальнейшем я буду говорить о столбцах) от 1 до 4 (последовательно слева направо или справа налево). Основополагающим принципом стратегии является расположение чисел, при котором мы полностью заполняем 1ый столбец наибольшими доступными числами. При этом, во 2ом столбце числа в среднем меньше, чем в 1ом, а в 3ем меньше, чем во 2ом. Причем, только на последних этапах игры в 3ем столбце возможно появление чисел среднего номинала (где-то до 32).
Из этого принципа следует, что при выборе хода предпочтение мы должны отдать такому, который увеличивает числа первых столбцов. Таким образом, мы всегда сохраняем градиент заполнения чисел и соответственно не отклоняемся от вышеизложенного принципа.
Например, используя в качестве 1ого столбца левый, мы никогда не будем использовать клавишу →, чтобы не отклоняться от принципа.
Существенный тонкий нюанс: при заполнении выбранных столбцов нужно избегать ситуации, когда новое появившееся число может полностью заполнить столбец так, что нам придется сделать ход →, что полностью сведет на нет возможность продолжать играть по нашей стратегии.
Для наглядности прилагается картинка и видео:
