Предисловие
Когда я начал изучать Хаскель, я был почти сразу поражён. Для начала, нырнув с головой в актуальные рабочие проекты, открыл, что большинство настоящих библиотек используют языковые расширения, присутствующие только в GHC (Glasgow Haskell Compiler). Это меня покоробило слегка, прежде всего потому, кто захочет использовать язык настолько немощный, что будет необходимо использовать расширения, присутствующие лишь у одного поставщика. Ведь так?
Хорошо, я решился снова это осилить и узнать всё об этих расширениях, и я вывел три горячих топика для общества Хаскеля, которые решали похожие проблемы: Обобщённые Алгебраические Типы Данных, Семьи Типов и Функциональные Зависимости. Пытаясь найти ресурсы, которые обучают о них, я смог найти только статьи, описывающие, что это такое, и как их использовать. Но никто, на самом деле, не объяснял зачем они нужны!.. Поэтому я решил написать эту статью, используя дружественный пример, пытаясь объяснить зачем всё-таки нужны Семьи Типов.

Вы когда-нибудь слышали про Покемонов? Это замечательные существа, которые населяют Мир Покемонов. Вы можете считать, что они как животные с экстраординарными способностями. Все покемоны владеют стихией, и все их возможности зависят от этой стихии. Например, покемон Огненной стихии может дышать огнём, в то время как покемон Водной стихии может брызгать струями воды.
Покемоны принадлежат людям, и их специальные способности могут быть использованы во благо для продуктивной деятельности, но некоторые люди всего лишь используют своих покемонов для борьбы с другими покемонами других людей. Эти люди называют себя Тренерами Покемонов. Это может сначала звучать как жестокое обращение с животными, но это очень даже весело и все, похоже, рады, включая покемонов. Имейте в виду, что в мире покемонов, кажется, всё в порядке, даже если 10-летние покидают дом, дабы рисковать своими жизнями ради того, чтобы стать самыми лучшими Тренерами Покемонов, как будто никто и никогда таковыми не становился.
Мы собираемся использовать Хаскель для того, что бы представить ограниченную (и даже несколько упрощённую, да простят меня фанаты) часть мира покемонов.





 1. Введение
1. Введение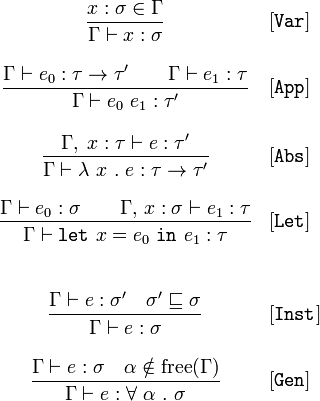






 На этой неделе мы выкладывали
На этой неделе мы выкладывали 
 Некоторое время назад зам.главы московского офиса разработки Badoo Алексей Рыбак и ведущие IT-Компот записали выпуск подкаста «Архитектура высоконагруженных приложений. Масштабирование распределенных систем".
Некоторое время назад зам.главы московского офиса разработки Badoo Алексей Рыбак и ведущие IT-Компот записали выпуск подкаста «Архитектура высоконагруженных приложений. Масштабирование распределенных систем".