Несколько дней назад стала доступна версия Data ONTAP 8.3.2RC1. “RC” означает Release Candidate, а следовательно, в соответствии с принятыми в NetApp правилами именования версий, этот релиз уже прошел все внутренние тесты и может использоваться заказчиками не только для оценки новых возможностей, но и для продуктива, включая системы, на которых работают бизнес-критичные задачи. Поддержка вендора полностью распространяется на системы, работающие на “RC” версиях Data ONTAP.
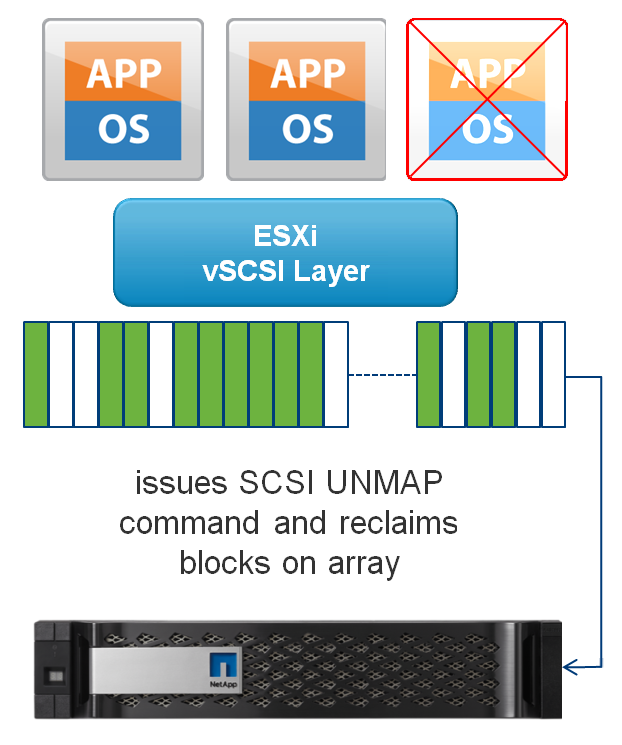
Продавцы NetApp (да, это и мы тоже ;) не устают напоминать (и делают это совершенно правильно), что высокая утилизация дисковых ресурсов в системах NetApp достигается за счет использования программных средств оптимизации — дедупликации и компрессии.
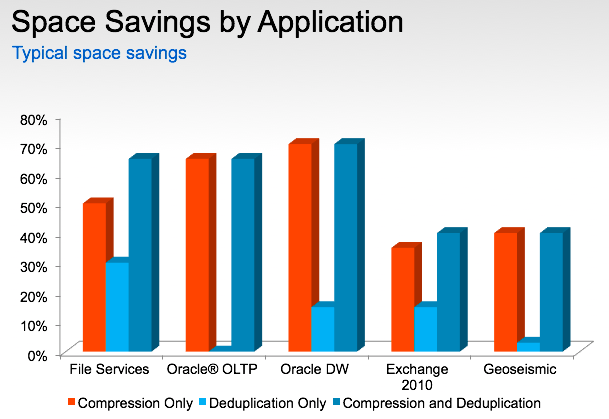
Продавцы NetApp (да, это и мы тоже ;) не устают напоминать (и делают это совершенно правильно), что высокая утилизация дисковых ресурсов в системах NetApp достигается за счет использования программных средств оптимизации — дедупликации и компрессии.

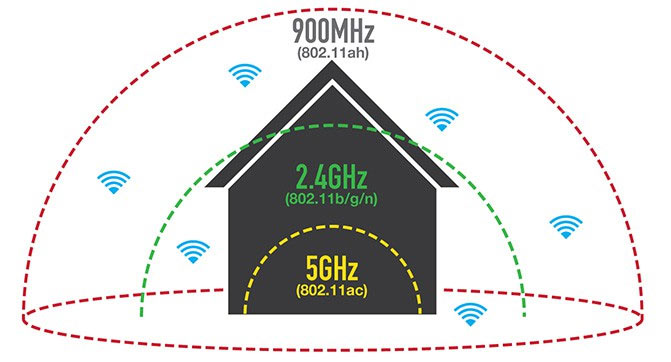




 В последние несколько лет MongoDB приобрела огромную популярность среди разработчиков. То и дело в интернете появляются всякие статьи, как очередной молодой популярный проект выкинул на свалку истории привычные РСУБД, взял в качестве основной базы данных MongoDB, выстроил инфраструктуру вокруг неё, и как все после этого стало прекрасно. Даже появляются новые фреймворки и библиотеки, которые строят свою архитектуру целиком на Mongo (
В последние несколько лет MongoDB приобрела огромную популярность среди разработчиков. То и дело в интернете появляются всякие статьи, как очередной молодой популярный проект выкинул на свалку истории привычные РСУБД, взял в качестве основной базы данных MongoDB, выстроил инфраструктуру вокруг неё, и как все после этого стало прекрасно. Даже появляются новые фреймворки и библиотеки, которые строят свою архитектуру целиком на Mongo (