Что такое умные контракты, как они работают и почему будущее именно за ними.

Блокчейн представляет собой децентрализованную систему, существующую благодаря множеству объединенных в сеть компьютеров. Поэтому одно из его главных достоинств — то, что вы можете не платить посредникам и экономить свое время и нервы.
У блокчейна есть свои недостатки, но он быстрее, надежнее и безопаснее традиционных систем, и поэтому банки и правительственные организации все чаще используют эту технологию для своих нужд.
Блокчейн представляет собой децентрализованную систему, существующую благодаря множеству объединенных в сеть компьютеров. Поэтому одно из его главных достоинств — то, что вы можете не платить посредникам и экономить свое время и нервы.
У блокчейна есть свои недостатки, но он быстрее, надежнее и безопаснее традиционных систем, и поэтому банки и правительственные организации все чаще используют эту технологию для своих нужд.


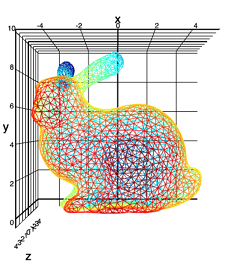
 Статистика приходит к нам на помощь при решении многих задач, например: когда нет возможности построить детерминированную модель, когда слишком много факторов или когда нам необходимо оценить правдоподобие построенной модели с учётом имеющихся данных. Отношение к статистике неоднозначное. Есть мнение, что существует три вида лжи: ложь, наглая ложь и статистика. С другой стороны, многие «пользователи» статистики слишком ей верят, не понимая до конца, как она работает: применяя, например, тест
Статистика приходит к нам на помощь при решении многих задач, например: когда нет возможности построить детерминированную модель, когда слишком много факторов или когда нам необходимо оценить правдоподобие построенной модели с учётом имеющихся данных. Отношение к статистике неоднозначное. Есть мнение, что существует три вида лжи: ложь, наглая ложь и статистика. С другой стороны, многие «пользователи» статистики слишком ей верят, не понимая до конца, как она работает: применяя, например, тест  +
+  =?
=? 
 Эта статья послужит практическим руководством по сборке, начальной настройке и тестированию работоспособности Hadoop начинающим администраторам. Мы разберем, как собрать Hadoop из исходников, сконфигурировать, запустить и проверить, что все работает, как надо. В статье вы не найдете теоретической части. Если вы раньше не сталкивались с Hadoop, не знаете из каких частей он состоит и как они взаимодействуют, вот пара полезных ссылок на официальную документацию:
Эта статья послужит практическим руководством по сборке, начальной настройке и тестированию работоспособности Hadoop начинающим администраторам. Мы разберем, как собрать Hadoop из исходников, сконфигурировать, запустить и проверить, что все работает, как надо. В статье вы не найдете теоретической части. Если вы раньше не сталкивались с Hadoop, не знаете из каких частей он состоит и как они взаимодействуют, вот пара полезных ссылок на официальную документацию:
 Итак, в
Итак, в