Проведение конкурсов для IT-специалистов сейчас в моде: Kaggle с его задачами по Data Science, сплоченная тусовка олимпиадного программирования, набирающие популярность площадки для конкурсов по искусственному интеллекту, всевозможные хакатоны для мобильных разработчиков, олимпиады для админов, capture the flag для безопасников. Казалось бы, специалисту любой сферы несложно найти себе подходящую движуху, поучаствовать, прокачаться и что-нибудь выиграть.
Обделенными в этом плане остались лишь web-разработчики. Мы в Mail.Ru Group решили исправить это досадное недоразумение и теперь с радостью представляем вам HighLoadCup — конкурсную площадку на стыке backend-разработки и администрирования web-сервисов.
Если считаете себя хорошим web-разработчиком, умеете в deploy и highload — добро пожаловать!

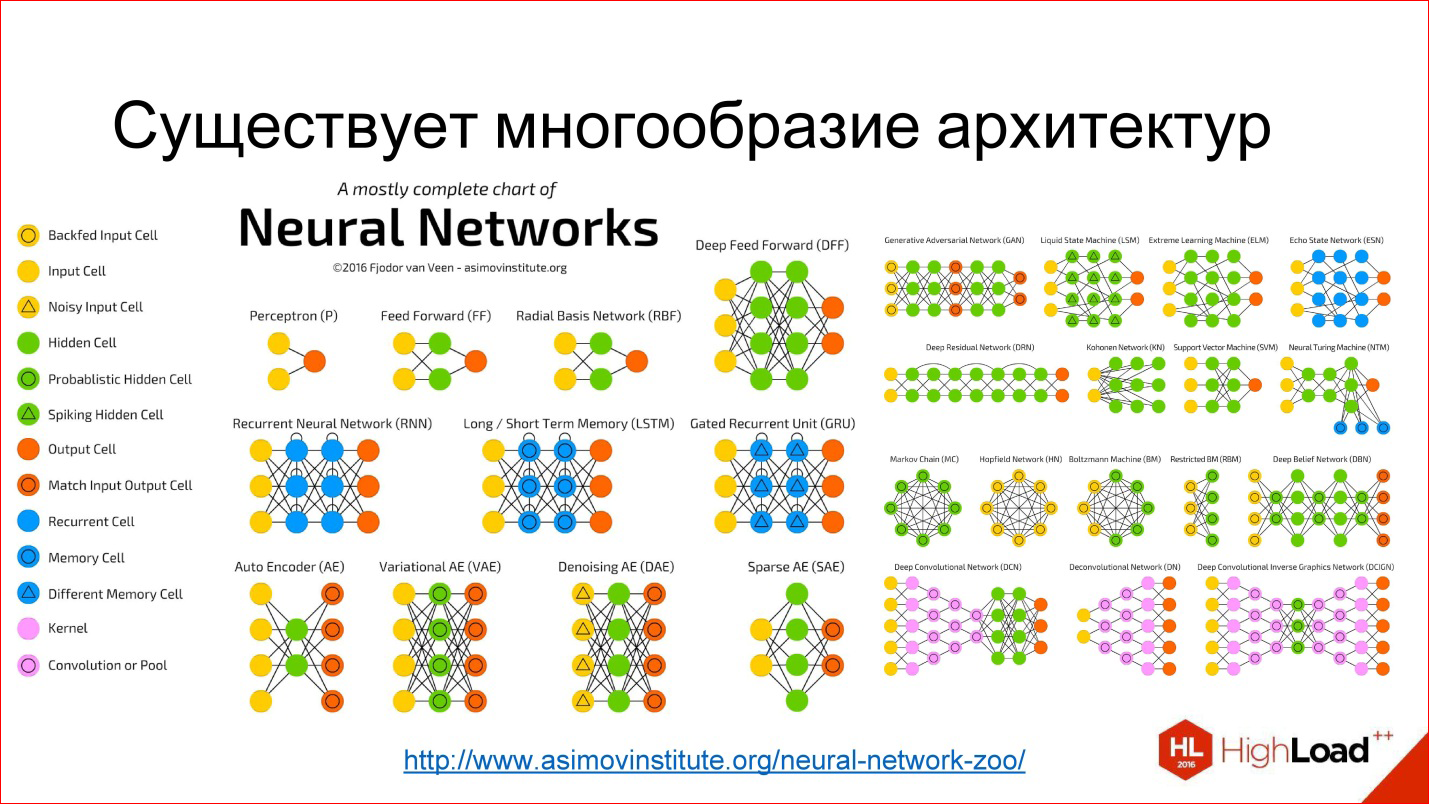
 Если ты на практике используешь ООП, то хорошо разбираешься в таких вещах, как
Если ты на практике используешь ООП, то хорошо разбираешься в таких вещах, как 






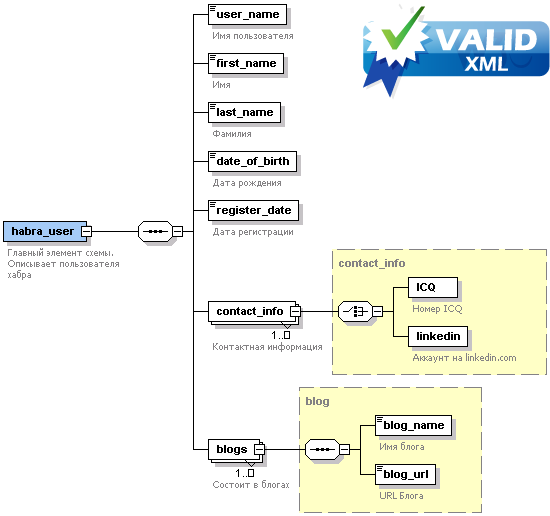

 [Обновление] Теперь я в каком-то списке спецслужб, потому что написал статью про некий вид «бомбы», так?
[Обновление] Теперь я в каком-то списке спецслужб, потому что написал статью про некий вид «бомбы», так?