Как известно, службы Windows представляют собой одно из наиболее излюбленных мест для атак на операционную систему. В худшем (для нас, конечно) случае атакующий получает возможность действовать на атакованном компьютере в контексте учетной записи, от имени которой запущена взломанная служба. И если эта учетная запись обладает административными правами, то фактически злоумышленник получает полный контроль над компьютером. От версии к версии в Windows появляются новые механизмы, обеспечивающие дополнительную изоляцию служб и, как следствие, усиливающие безопасность системы в целом. Я хотел бы вкратце рассмотреть, что принципиально изменилось в этом направлении за последние несколько лет.

Даниил Солопов @dan_sw
Software Engineer, Bachelor of Computer Science
Каков C++ в gamedev'e?
Easy
11 min

Хотел написать продолжение к статье Что почитать игровому программисту? про использование С++ в игровых движках, но размышления свернули куда-то не туда.
Завороженно смотрю как и какими темпами идет развитие языка в последние годы, и понимаю, что получить и особенно применить возможности С++20/3 в разработке игр и движков получится хорошо, если с опозданием лет эдак в пять, как раз на следующее поколение консолей, если вообще получится. Сейчас плюсы в игрострое зависли где-то между 14 и 17 стандартом, Сони только-только выкатила свою версию компилятора с полной поддержкой 17 стандарта, а учитывая реактивность игровых студий в изменении кор пайплайнов, что-то новое начнут только в новых проектах. Менять коня, т.е. компилятор посреди разработки игры равносильно стрельбе не только по ногам себе, но и соседям программистам: работает - не чини.
Если смена компилятора и стандарта не даст гарантированного прироста скорости работы больше 5%, то бюджет и людей я не одобрю. (с)
Знакомство с кодовой базой больших движков дает понимание уровня и объёмов кода в продакшене и в тулзах, и ситуация вырисовывается такая, что эти объемы стали в индустрии, что называется "too big to fall", т.е. написать что-то новое, уровня движков вроде Unity/Unreal/Dagor на другом языке, будь он хоть в тысячу раз безопаснее и в десять раз быстрее не получится, но попытки конечно делаются. И чем дальше продолжается поддержка существующих проектов на плюсах, тем меньше возможности выбора остается.
Все попытки прикрутить сбоку скрипты, виртуальную машину второго языка, визуальные редакторы скриптов, блупринты и т.д. лишь показывает насколько громоздким стал основной механизм. А игры прекрасно продаются на текущем стеке технологий, и обосновать переезд на новый стек мифическим рефакторингом, техдолгом и новыми технологиями не удаётся, поэтому мышки продолжают плакать и потреблять кактус++.
Семь каверзных вопросов от преподавателей школы аналитиков данных МТС
6 min

Привет, Хабр! Меня зовут Максим Шаланкин, я вместе со своими коллегами — преподавателями в Школе аналитиков данных от МТС — подготовил семь каверзных вопросов, с которыми могут столкнуться начинающие специалисты в области Data Science, ML и Big Data. Ну что, поехали!
Допечатываем ту самую «Математику в машинном обучении»
1 min
Друзья, рады сообщить, что скоро выйдет очередная допечатка замечательной книги «Математика в машинном обучении». Мы получили на нее массу положительных отзывов (средняя оценка 4.9 на Озоне, 5.0 на Wildberries).
К сожалению, не обошлось без огрехов, в таком сложном тексте это практически невозможно.
Во время создания русской версии Mathematics for Machine Learning от Cambridge University Press помимо эрраты мы дополнительно учли и исправили более 500 замечаний и ляпов, найденных зарубежными читателями в англоязычной книге (issues на github), плюс десятки нашли самостоятельно.
К сожалению, не обошлось без огрехов, в таком сложном тексте это практически невозможно.
Во время создания русской версии Mathematics for Machine Learning от Cambridge University Press помимо эрраты мы дополнительно учли и исправили более 500 замечаний и ляпов, найденных зарубежными читателями в англоязычной книге (issues на github), плюс десятки нашли самостоятельно.
Кто такие LLM-агенты и что они умеют?
Medium
24 min
Review
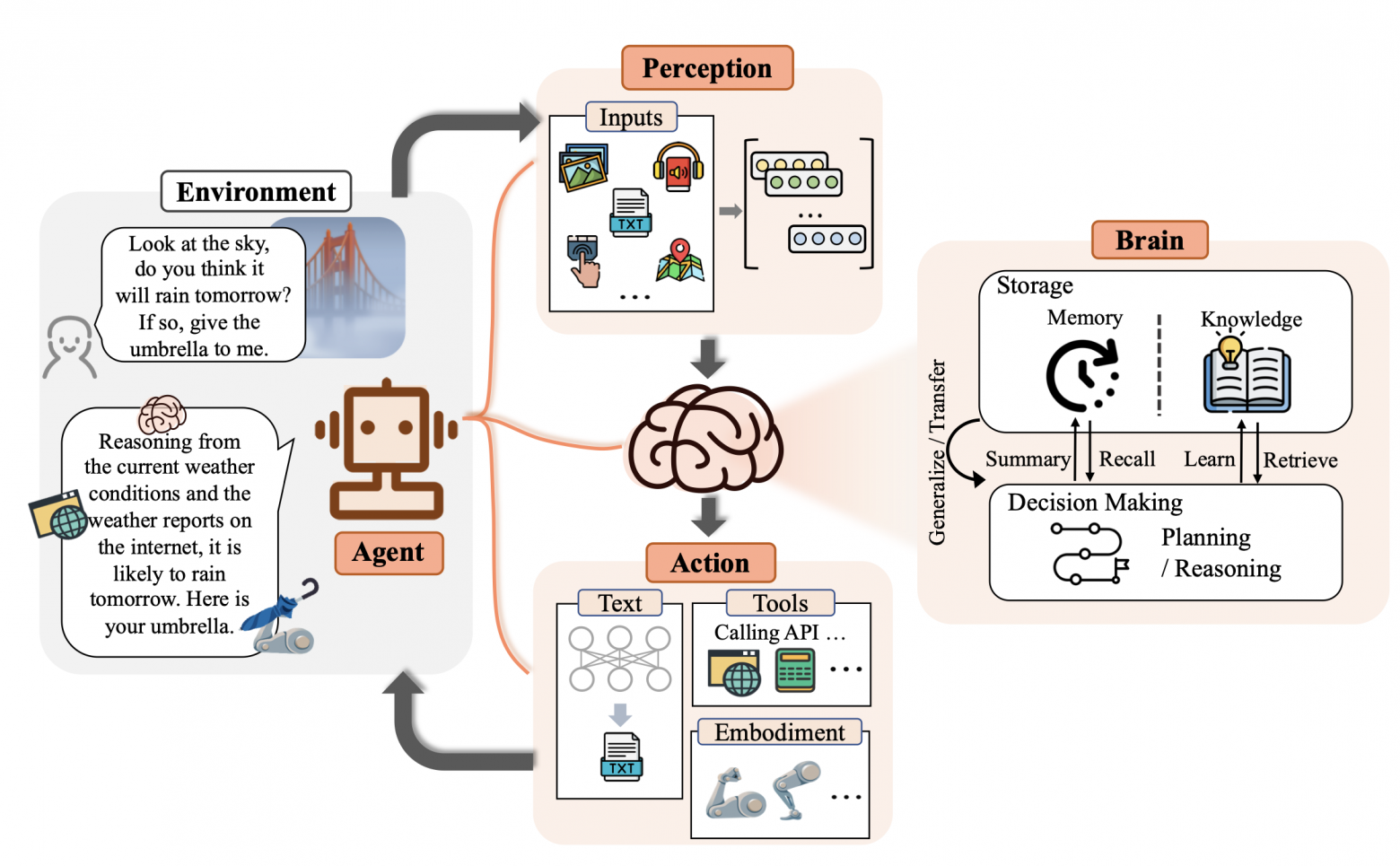
В последнее время большие языковые модели (Large Language Models, LLM) стали невероятно популярными — кажется, их обсуждают везде, от школьных коридоров до Сената США. Сфера LLM растёт бурными темпами, привлекая внимание не только специалистов в области машинного обучения, но и обычных пользователей. Кто-то высказывает массу опасений насчет их дальнейшего развития, а кто-то и вовсе предлагает бомбить дата-центры — и даже в Белом Доме обсуждают будущее моделей. Но неужели текстом можно кому-то навредить? А что если такая модель приобрела бы агентность, смогла создать себе физическую оболочку и полностью ей управлять? Ну, это какая-то фантастика из (не)далёкого будущего, а про агентов нашего времени я расскажу в этой статье. И не переживайте — знание машинного обучения вам не понадобится!
SVM. Подробный разбор метода опорных векторов, реализация на python
15 min
Привет всем, кто выбрал путь ML-самурая!
Введение:
В данной статье рассмотрим метод опорных векторов (англ. SVM, Support Vector Machine) для задачи классификации. Будет представлена основная идея алгоритма, вывод настройки его весов и разобрана простая реализация своими руками. На примере датасета будет продемонстрирована работа написанного алгоритма с линейно разделимыми/неразделимыми данными в пространстве и визуализация обучения/прогноза. Дополнительно будут озвучены плюсы и минусы алгоритма, его модификации.

Рисунок 1. Фото цветка ириса из открытых источников
Линейная регрессия. Основная идея, модификации и реализация с нуля на Python
Hard
16 min
Tutorial
В машинном и глубоком обучении линейная регрессия занимает особое место, являясь не просто статистическим инструментом, но а также фундаментальным компонентом для многих более сложных концепций. В данной статье рассмотрен не только принцип работы линейной регрессии с реализацией с нуля на Python, но а также описаны её модификации и проведён небольшой сравнительный анализ основных методов регуляризации. Помимо этого, в конце указаны дополнительные источники для более глубокого ознакомления.
C++ и копирование перекрывающихся областей памяти
3 min
Tutorial
Программируя на Си многие сталкивались с такими функциями как
В мире С++ никто не запрещает пользоваться этими функциями (часто эти функции используют различные механизмы оптимизации и могут статься быстрее своих собратьев из мира C++), но есть и более родное средство, работающее через итераторы:
memcpy() и memmove(), по сути, функции делают одно и тоже, но вторая корректно отрабатывает ситуацию, когда области памяти перекрываются (на что появляются дополнительные накладные расходы).В мире С++ никто не запрещает пользоваться этими функциями (часто эти функции используют различные механизмы оптимизации и могут статься быстрее своих собратьев из мира C++), но есть и более родное средство, работающее через итераторы:
std::copy. Это средство применимо не только к POD типам, а к любым сущностям, поддерживающим итераторы. О деталях реализации в стандарте ничего не сказано, но можно предположить, что разработчики библиотеки не настолько глупы, что бы не использовать, оптимизированные memcpy()/memmove() когда это возможно. «Boost.Asio C++ Network Programming». Глава 1: Приступая к работе с Boost.Asio
15 min
Tutorial
Привет Хабралюди!
Это мой первый пост, поэтому не судите строго. Я хочу начать вольный перевод книги John Torjo «Boost.Asio C++ Network Programming» вот ссылка на нее.
Содержание:
Во-первых разберем что есть Boost.Asio, как его собрать, а так же несколько примеров. Вы узнаете, что Boost.Asio больше, чем сетевая библиотека. Так же вы узнаете о самом важном классе, который находится в самом сердце Boost.Asio —
Это мой первый пост, поэтому не судите строго. Я хочу начать вольный перевод книги John Torjo «Boost.Asio C++ Network Programming» вот ссылка на нее.
Содержание:
- Глава 1: Приступая к работе с Boost.Asio
- Глава 2: Основы Boost.Asio
- Глава 3: Echo Сервер/Клиент
- Глава 4: Клиент и Сервер
- Глава 5: Синхронное против асинхронного
- Глава 6: Boost.Asio – другие особенности
- Глава 7: Boost.Asio – дополнительные темы
Во-первых разберем что есть Boost.Asio, как его собрать, а так же несколько примеров. Вы узнаете, что Boost.Asio больше, чем сетевая библиотека. Так же вы узнаете о самом важном классе, который находится в самом сердце Boost.Asio —
io_service.Разработка BIOS на языках высокого уровня
Hard
11 min
Tutorial

Меня давно волнует вопрос, как подступиться к разработке на голом железе, на чистом си. Хотелось понять, каким же образом идёт запуск BIOS, u-boot, grub и прочих первичных загрузчиков. Ведь необходимо перейти от ассемблера к тёплому ламповому си и соблюсти условие, собрать всё это в линукс любимым компилятором gcc.
Хотя я и имею достаточный опыт BareMetal-разработки, тем не менее, всё это были чужие проекты со своим кодом. А мне хотелось понять, как начать свой проект с чистого листа, когда есть только чистая железка и идея. Толковых статей как подступится к этой задаче достаточно мало, при этом совершенно непонятно, с какого же края к ней подходить.
Здесь я хочу свести основные моменты разработки BIOS в одном месте и разобраться обо всех проблемах, которые я получил во время своих опытах в разработке (первая и вторая части).
Правильная работа с потоками в Qt
13 min
Qt — чрезвычайно мощный и удобный фреймворк для C++. Но у этого удобства есть и обратная сторона: довольно много вещей в Qt происходят скрыто от пользователя. В большинстве случаев соответствующая функциональность в Qt «магически» работает и это приучает пользователя просто принимать эту магию как данность. Однако когда магия все же ломается то распознать и решить неожиданно возникшую на ровном казалось бы месте проблему оказывается чрезвычайно сложно.
Эта статья — попытка систематизации того как в Qt «под капотом» реализована работа с потоками и о некотором количестве неочевидных подводных камней связанных с ограничениями этой модели.
Основы
Thread affinity, инициализация и их ограничения
Главный поток, QCoreApplication и GUI
Rendering thread
Заключение
Эта статья — попытка систематизации того как в Qt «под капотом» реализована работа с потоками и о некотором количестве неочевидных подводных камней связанных с ограничениями этой модели.
Основы
Thread affinity, инициализация и их ограничения
Главный поток, QCoreApplication и GUI
Rendering thread
Заключение
Руководство по CMake для разработчиков C++ библиотек
18 min
Tutorial

Данное руководство позволит читателю составить полную картину того, как организовать сборку C++ библиотек с использованием современных возможностей CMake. Предполагается, что читатель имеет представление о базовых понятиях из мира CMake и динамических/статических C++ библиотек, так как в руководстве они могут не объясняться.
Декодирование BPSK Модуляции из Звука (или передача данных по воздуху)
Easy
9 min
Tutorial

В этом тексте я реализовал возможность передачи бинарных данных звуком через BPSK модуляцию. Написал инструкцию как это можно делать.
Вся обработка происходит в post processing режиме на PC над записанным wav файлом.
Изучение ЦОС на примере работы со звуком - это доступная каждому возможность для экспериментов с различными алгоритмами DSP.
Параллельное программирование с CUDA. Часть 1: Введение
11 min
Tutorial
Еще одна статья о CUDA — зачем?
На Хабре было уже немало хороших статей по CUDA — раз, два и другие. Однако, поиск комбинации «CUDA scan» выдал всего 2 статьи никак не связанные с, собственно, алгоритмом scan на GPU — а это один из самых базовых алгоритмов. Поэтому, вдохновившись только что просмотренным курсом на Udacity — Intro to Parallel Programming, я и решился написать более полную серию статей о CUDA. Сразу скажу, что серия будет основываться именно на этом курсе, и если у вас есть время — намного полезнее будет пройти его.
Эффективный запуск и инференс LLM на своем сервере с нуля (часть 1)
Medium
10 min

Привет, Хабр! На связи CEO команды Compressa AI. Недавно обнаружил для себя крутой базовый курс по эффективному запуску и инференсу LLM моделей от легенды AI мира — Andrew NG и его платформы DeepLearning. Он полностью на английском языке в формате видео, поэтому я осмелился адаптировать его под формат Хабра на русском языке. Знания должны быть доступны всем и в удобной форме, так ведь?
Многие команды (включая и Compressa AI) начинали LLM проекты с использования облачных API. Но по мере развития все больше разработчиков хотят использовать open-source LLM, чтобы экономить на токенах, снижать latency, запускать fine-tuning на собственных данных и в целом меньше зависеть от внешних моделей.
Из этого курса вы узнаете детали эффективного обслуживания и дообучения open-source LLM, включая методы обработки множества запросов от нескольких пользователей. Используя несколько таких методов одновременно, вы можете улучшить как задержку (latency), так и пропускную способность (throughput). Например, благодаря применению последних open-source технологий в своем продукте, мы добились увеличения пропускной способности до 70x на 1 GPU в сравнении с дефолтными Hugging Face & PyTorch.
Курс слишком объемный даже для лонгрида, в нем много практического кода, поэтому сегодня начну с первых уроков и выпущу следующие части, если увижу живой интерес. Это адаптация, а не прямой копипаст, поэтому где-то немного расширю курс информацией от себя, а где-то сокращу. Также хочется отметить, что русифицирование терминов вокруг LLM — дело довольно неблагодарное, поэтому часть из них будет на английском.
Введение в CMake
7 min
Recovery Mode
 CMake — кроcсплатформенная утилита для автоматической сборки программы из исходного кода. При этом сама CMake непосредственно сборкой не занимается, а представляет из себя front-end. В качестве back-end`a могут выступать различные версии make и Ninja. Так же CMake позволяет создавать проекты для CodeBlocks, Eclipse, KDevelop3, MS VC++ и Xcode. Стоит отметить, что большинство проектов создаются не нативных, а всё с теми же back-end`ами.
CMake — кроcсплатформенная утилита для автоматической сборки программы из исходного кода. При этом сама CMake непосредственно сборкой не занимается, а представляет из себя front-end. В качестве back-end`a могут выступать различные версии make и Ninja. Так же CMake позволяет создавать проекты для CodeBlocks, Eclipse, KDevelop3, MS VC++ и Xcode. Стоит отметить, что большинство проектов создаются не нативных, а всё с теми же back-end`ами.Синглтон, размещающий объекты в ROM и статические переменные(С++ на примере микроконтроллера Cortex M4)
15 min

В предыдущей статье Где хранятся ваши константы на микроконтроллере CortexM (на примере С++ IAR компилятора), был разобран вопрос о том, как расположить константные объекты в ROM. Теперь же я хочу рассказать, как можно использовать порождающий шаблон одиночка для создания объектов в ROM.
Модель Акторов и C++: что, зачем и как?
20 min
Данная статья является доработанной текстовой версией одноименного доклада с конференции C++ CoreHard Autumn 2016, которая проходила в Минске в октябре прошлого года. Желание сделать эту статью возникло под впечатлением о том, что в мире C++ разработчики как бы делятся на два больших и не пересекающихся лагеря. В первом лагере находятся матерые спецы, которые все видели, все знают и все умеют, за плечами у которых десятки собственноручно написанных реализаций Модели Акторов, внутрях у которых хитрые, конечно же самостоятельно сделанные, lock-free очереди и state-of-the-art механизмы обслуживания сообщений. Такие проффи сами часами могут рассказывать про тонкости многопоточного программирования (только почему-то редко это делают). Во втором лагере — зеленые новички, которых волею судьбы занесло в мир C++, которые пока слабо представляют себе различия между unique_ptr и shared_ptr, про шаблоны только слышали, а в области многопоточности имеют поверхностное впечатление только о std::thread, std::mutex и, может быть, std::condition_variable. Для людей из первого лагеря я вряд ли что-нибудь интересное расскажу, а вот разработчикам из второго лагеря попробую вкратце рассказать о том, что Модель Акторов в C++ — это нормально. И что есть ряд готовых инструментов, на примере которых можно увидеть, что же это такое.
Книга про разработку приложений для Firebird
3 min
 Читатели Хабра знают, что я (Денис Симонов) уже некоторое время работаю над серией статей и примеров, которые подробно раскрывают особенности разработки приложений для СУБД Firebird для популярных языков и фреймворков: уже написаны 3 статьи по ADO.NET desktop, ASP.NET MVC и Delphi, в работе для PHP, Java, Android. Также, c 2014 года я являюсь редактором русской документации языку Firebird и членом международной группы документации Firebird.
Читатели Хабра знают, что я (Денис Симонов) уже некоторое время работаю над серией статей и примеров, которые подробно раскрывают особенности разработки приложений для СУБД Firebird для популярных языков и фреймворков: уже написаны 3 статьи по ADO.NET desktop, ASP.NET MVC и Delphi, в работе для PHP, Java, Android. Также, c 2014 года я являюсь редактором русской документации языку Firebird и членом международной группы документации Firebird.В процессе работы над примерами я пришел к выводу, что нужно объединять эти статьи и логически дополнять до полноценной книги, посвященной разработке именно под Firebird. Хотя по разработке есть много материалов, и есть русская документация по языку SQL, книга, с последовательным изложением процесса создания приложений и описанием основных ошибок новичков, будет полезна.
Вы спросите – собственно, причем здесь Хабр?
Знакомство с SOCI — C++ библиотекой доступа к базам данных
7 min
Tutorial
Вступление
Сама библиотека довольно таки зрелая, — первый релиз на гитхабе датируется аж 2004-ым годом. Я был удивлён когда Хабр в поисковике не выдал мне ни одной ссылки на статьи, в которых бы упоминалось об этой замечательной библиотеке.
Произносится как: сОцы, с ударением на первый слог.
SOCI поддерживает ORM, через специализацию soci::type_conversion.
Поддержка баз данных (БД) (бэкенды):
Я не стану переводить мануалы или приводить здесь код из примеров, а постараюсь адаптировать (с изменением структуры таблицы, и других упрощений) код из своего прошлого проекта, чтобы было нагляднее и интереснее.