C++20. Coroutines
33 min
Tutorial
В этой статье мы подробно разберем понятие сопрограмм (coroutines), их классификацию, детально рассмотрим реализацию, допущения и компромиссы, предлагаемые новым стандартом C++20.


Разработка электроники
В этой статье мы подробно разберем понятие сопрограмм (coroutines), их классификацию, детально рассмотрим реализацию, допущения и компромиссы, предлагаемые новым стандартом C++20.

Функциональное программирование может отпугивать сложностью и непрактичностью: «Я далек от всех этих монад, пишу на обычном C#, в докладе про функциональщину ничего не пойму. А если даже напрягусь и пойму, где мне потом это применять?»
Но когда объясняет Скотт Влашин, все совершенно не так: его доклад о композиции с конференции DotNext 2019 Moscow — пример того, как можно доносить функциональные идеи простыми словами. Он за час перешел от бананов к монадам так, что второе кажется немногим сложнее первого. А в конце объяснил, почему осмыслить композицию полезно даже тем, кто не собирается покидать мир ООП. Примеры кода в докладе как на F#, так и на C#.
Уже завтра начнется новый DotNext, где я помогу Скотту выступить с другим докладом, а пока что публикую перевод его выступления про композицию. Далее повествование будет от лица Скотта.

История непримиримой борьбы за повышение безопасности написанного на языке С++ микропрограммного обеспечения, против динамического выделения памяти, за пробуждение исследовательского духа в разработке, против избыточной сложности кода, за здоровую критику на ревью и здоровую самокритику, за оптимизацию потребления всех видов памяти, за образцовое содержание документации и против недооценки собственных сил и ресурсов небольших устройств на базе STM32.
В первых двух статьях цикла мы рассмотрели четыре способа упорядочить доступ к памяти: load-acquire и store-release операции в первой части, барьеры чтения и записи в память — во второй. Теперь пришла очередь познакомиться с полными барьерами памяти, их влиянием на производительность, и примерами использования полных барьеров в ядре Linux.
Рассмотренные ранее примитивы ограничивают возможный порядок исполнения операций с памятью четырьмя различными способами:
Внимательный читатель заметил, что одна из возможных комбинаций в этом списке отсутствует:
| Чтение выполняется... | Запись выполняется... | |
| … после чтения | smp_load_acquire(), smp_rmb() | smp_load_acquire(), smp_store_release() |
| … после записи | ??? | smp_store_release(), smp_wmb() |

Появившиеся в C++11 лямбды стали одной из самых крутых фич нового стандарта языка, позволив сделать обобщённый код более простым и читабельным. Каждая новая версия стандарта C++ добавляет новые возможности лямбдам, делая обобщённый код ещё проще и читабельнее. Вы заметили, что слово «обобщённый» повторилось дважды? Это неспроста – лямбды действительно хорошо работают с кодом, построенным на шаблонах. Но при попытке использовать их в необобщённом, построенном на конкретных типах коде, мы сталкиваемся с рядом проблем. Статья о причинах и путях решения этих проблем.
Git имеет репутацию запутывающего инструмента. Пользователи натыкаются на терминологию и формулировки, которые вводят в заблуждение. Это более всего проявляется в "перезаписывающих" историю командах, таких как git cherry-pick или git rebase. По моему опыту, первопричина путаницы — интерпретация коммитов как различий, которые можно перетасовать. Однако коммиты — это не различия, а снимки! Я считаю, что Git станет понятным, если поднять занавес и посмотреть, как он хранит данные репозитория. Изучив модель хранения данных мы посмотрим, как новый взгляд помогает понять команды, такие как git cherry-pick и git rebase.


Разработчики часто сталкиваются с необходимостью разработки многопоточных приложений, поэтому вопросы многопоточности требуют детального изучения. Давайте познакомимся с основными терминами, используемыми в источниках информации о многопоточности, рассмотрим задачи и проблемы многопоточности и изучим средства стандартной библиотеки C++, которые помогут создавать многопоточные приложения.

Интерфейсные классы весьма широко используются в программах на C++. Но, к сожалению, при реализации решений на основе интерфейсных классов часто допускаются ошибки. В статье описано, как правильно проектировать интерфейсные классы, рассмотрено несколько вариантов. Подробно описано использование интеллектуальных указателей. Приведен пример реализации класса исключения и шаблона класса коллекции на основе интерфейсных классов.

С кодами малой плотности проверок на чётность, которые дальше мы будем именовать коротко LDPC (Low-density parity-check codes), мне удалось познакомиться более или менее близко, работая над семестровым научным проектом в ТУ Ильменау (магистерская программа CSP). Моему научному руководителю направление было интересно в рамках педагогической деятельности (нужно было пополнить базу примеров, а также посмотреть в сторону недвоичных LDPC), а мне из-за того, что эти коды были плюс-минус на слуху на нашей кафедре. Не все удалось рассмотреть в том году, и поэтому исследование плавно перетекло в мое хобби… Так я набрал некоторое количество материала, которым сегодня и хочу поделиться!
Кому может быть интересна данная статья:
В общем, присоединяйтесь!
 Привет, Хаброжители! Ядро Windows таит в себе большую силу. Но как заставить ее работать? Павел Йосифович поможет вам справиться с этой сложной задачей: пояснения и примеры кода превратят концепции и сложные сценарии в пошаговые инструкции, доступные даже начинающим.
Привет, Хаброжители! Ядро Windows таит в себе большую силу. Но как заставить ее работать? Павел Йосифович поможет вам справиться с этой сложной задачей: пояснения и примеры кода превратят концепции и сложные сценарии в пошаговые инструкции, доступные даже начинающим.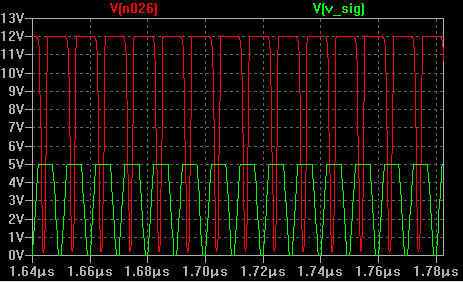
Если поискать в интернете схемы подключения оптронов, то можно обнаружить, что в подавляющем большинстве случаев предлагается просто добавить резистор. Это самая простая схема, она же и самая медленная. Когда скорость реакции не устраивает, предлагается ставить более быстрый оптрон, но быстрые оптроны - это дорого.
Для того, чтобы упростить написание и чтение кода, программисты периодически придумывают всякие техники. Об одной из таких техник я уже писал в публикации Долой циклы, или Неленивая композиция алгоритмов в C++.
Однако есть и классическая, более распространённая техника для борьбы с циклами — использование итераторов и диапазонов для ленивых операций над последовательностями. Всё это уже сто лет есть в Бусте и других сторонних библиотеках (к примеру, range-v3) и постепенно просачивается в стандартную библиотеку.
Хотя, в некотором смысле, и в стандартной библиотеке ленивые итераторы уже есть давно (см. std::reverse_iterator).Данная публикация — это краткий ликбез о том, что такое ленивые итераторы и диапазоны, зачем они нужны и как ими пользоваться.
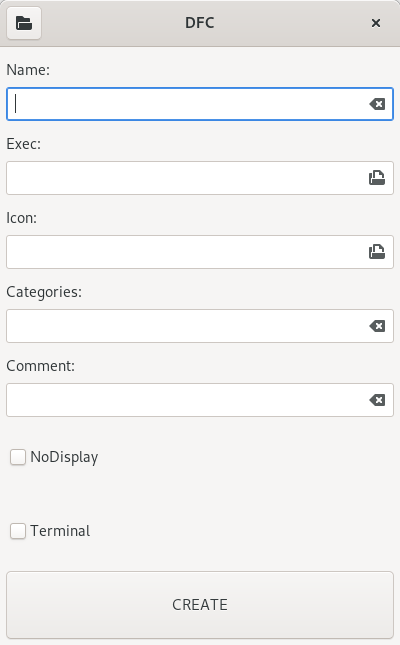
В дистрибутивах GNU/Linux значки приложений в меню описываются специальными текстовыми файлами. Эти файлы имеют расширение .desktop и при установке приложения создаются автоматически. Но иногда бывают ситуации когда нужно самому создать такой файл. Это может быть когда у вас на руках имеется только исполняемый файл приложения, то есть когда приложение не упаковано должным образом. В некоторых дистрибутивах из коробки имеются программы для создания значков запуска, а в некоторых их нет и нужно искать такие приложения в репозиториях. Я создал свой вариант такой программы и в этом посте расскажу, что она из себя представляет.
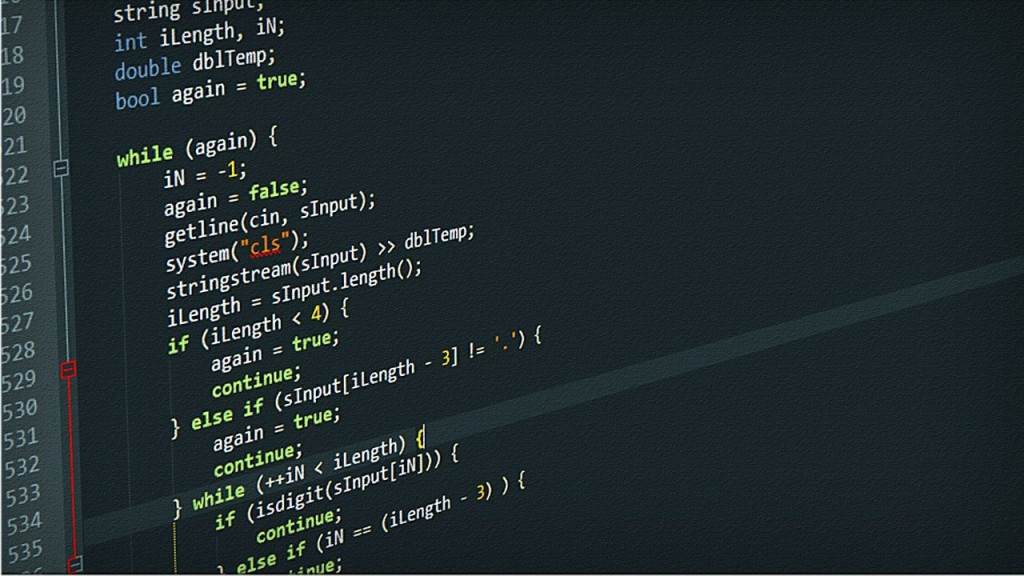
"Кто ни разу не ошибался в индексировании цикла, пусть первый бросит в деструкторе исключение."
— Древняя мудрость
Циклы ужасны. Циклы сложно читать — вместо того, чтобы сразу понять намерение автора, приходится сначала вникать в код, чтобы понять, что именно он делает. В цикле легко ошибиться с индексированием и переопределить индекс цикла во вложенном цикле. Циклы сложно поддерживать, исправлять в случае ошибок, сложно вносить текущие изменения, и т.д. и т.п.
В конце концов, это просто некрасиво.
Человечество издревле пытается упростить написание циклов. Вначале программисты подметили часто повторяющиеся циклы и выделили их в отдельные функции. Затем они придумали ленивые итераторы, а потом и диапазоны. И каждая из этих идей была прорывом. Но, несмотря на это, идеал до сих пор не достигнут, и люди продолжают искать способы улучшить свой код.
Данная работа ставит своей целью пролить свет на отнюдь не новую, но пока что не слишком распространённую идею, которая вполне способна произвести очередной прорыв в области написания программ на языке C++.
Так как же писать красивый, понятный, эффективный код, а также иметь возможность параллелить большие вычисления лёгким движением пальцев по клавиатуре?

В прошлый раз показал один из способов распределение ресурсов между конечными точками, а именно регистров EPnR, памяти под дескрипторы буферов и под сами буферы. Предлагаю продолжить начатое и рассмотреть написанную библиотеку на примере создания простого HID-устройства, позволяющего управлять светодиодом.
Доброго времени суток!
Меня зовут Александр, я работаю программистом микроконтроллеров, и это история о Фрэнки.
. . .Фрэнки родился чуднЫм. Родителями были пионэрский задор вашего автора и требования заказчика.
Когда младенца скомпилировали и по его венам потекли животворные байты, мой коллега процедил:
- Вы слепили монстра, герр Франкейштейн, но он не лишен некоторого очарования. . .
В то время я писал прошивку для станка с ЧПУ, причем заказчик наложил ограничения - строго Си, никаких сторонних библиотек, допускался только HAL с открытыми исходниками от производителя МК.
Был предоставлен забугорный образец станка, который мы должны были воспроизвести на собственных схемотехнике и ПО.
Общую логику работы подопытного мы с электронщиками раскурили довольно быстро, но оставалось несколько лакун в понимании взаимодействий между узлами, которые ничем, кроме домыслов не заполнялись. В итоге решили начинать как есть, рассчитывая в ходе экспериментов на прототипе постичь финальный замысел самураев.
Ну хорошо, а какой тогда должна быть архитектура приложения, когда нет итогового ТЗ и при этом низзя(!) ни в какие сторонние РТОСы и диспетчеры? Как выстроить программу, чтобы не перелопачивать все исходники, если вдруг осознаешь в середине проекта, что логику нужно править?