
В прошлый раз мы говорили о блокировках на уровне объектов, в частности — о блокировках отношений. Сегодня посмотрим, как в PostgreSQL устроены блокировки строк и как они используются вместе с блокировками объектов, поговорим про очереди ожидания и про тех, кто лезет без очереди.
Напомню несколько важных выводов из прошлой статьи.
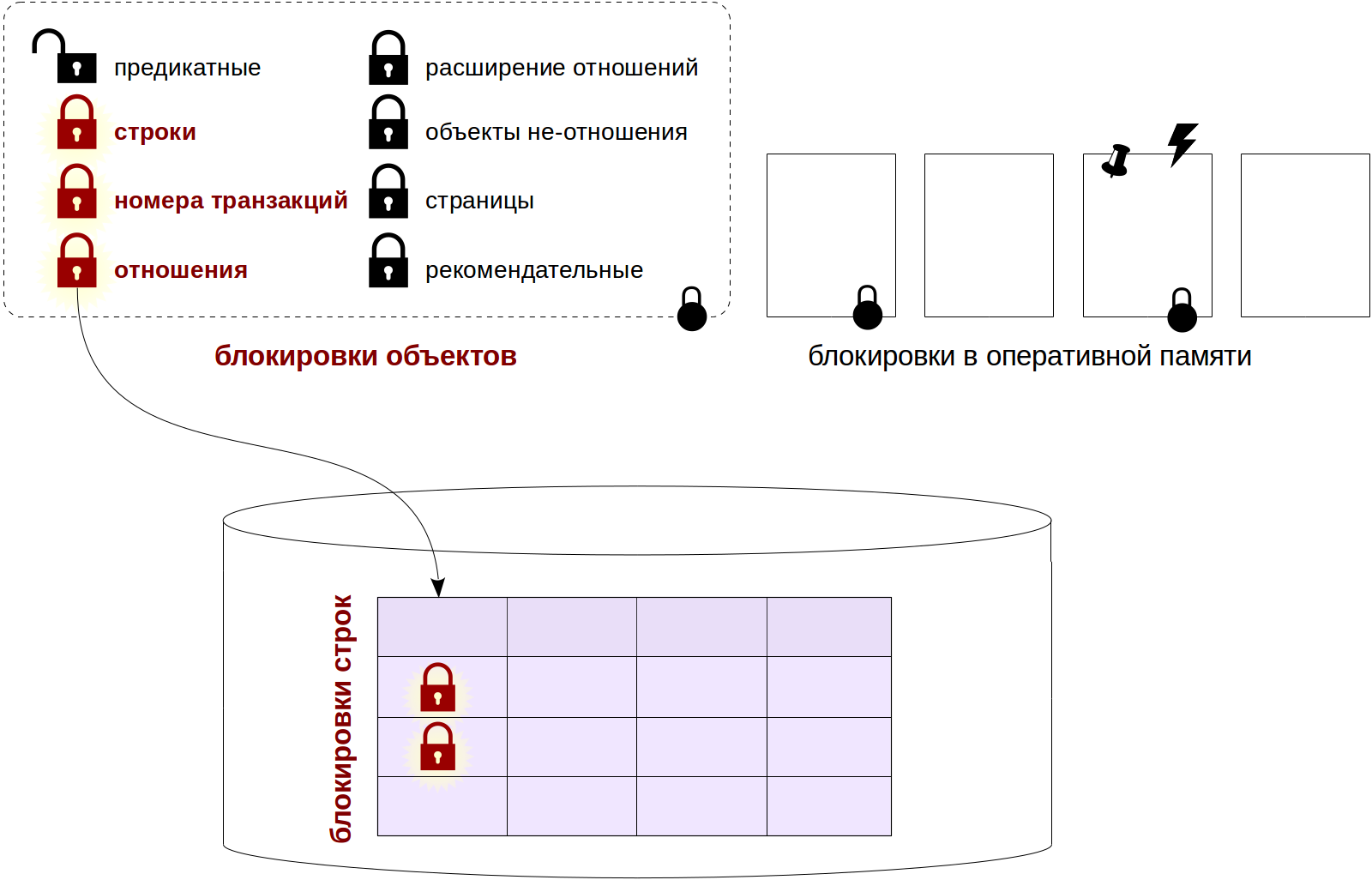
Нам безусловно хочется, чтобы изменение одной строки не приводило к блокировке других строк той же таблицы. Но и заводить на каждую строку по собственной блокировке мы не можем себе позволить.
Есть разные пути решения этой проблемы. В некоторых СУБД происходит повышение уровня блокировки: если блокировок уровня строк становится слишком много, они заменяются одной более общей блокировкой (например, уровня страницы или всей таблицы).
Как мы увидим позже, в PostgreSQL такой механизм тоже применяется, но только для предикатных блокировок. С блокировками строк дело обстоит иначе.
Блокировки строк
Устройство
Напомню несколько важных выводов из прошлой статьи.
- Блокировка должна существовать где-то в разделяемой памяти сервера.
- Чем выше гранулярность блокировок, тем меньше конкуренция (contention) среди одновременно работающих процессов.
- С другой стороны, чем выше гранулярность, тем больше места в памяти занимают блокировки.
Нам безусловно хочется, чтобы изменение одной строки не приводило к блокировке других строк той же таблицы. Но и заводить на каждую строку по собственной блокировке мы не можем себе позволить.
Есть разные пути решения этой проблемы. В некоторых СУБД происходит повышение уровня блокировки: если блокировок уровня строк становится слишком много, они заменяются одной более общей блокировкой (например, уровня страницы или всей таблицы).
Как мы увидим позже, в PostgreSQL такой механизм тоже применяется, но только для предикатных блокировок. С блокировками строк дело обстоит иначе.







 В этой статье я хотел бы рассказать о том, как выглядит процесс разработки PostgreSQL глазами одного из контрибьютеров в этот самый PostgreSQL. Заниматься разработкой этой СУБД я начал в декабре 2015 года, когда устроился работать в компанию Postgres Professional. То есть, не так уж давно. А значит, еще свежи воспоминания о моментах, которые поначалу казались мне не вполне очевидными. Хотелось бы их законспектировать, чтобы новым людям, приходящим в нашу команду, а также всем тем, кто желает попробовать себя в роли разработчика открытой реляционной СУБД, было легче. Я расскажу о том, как выглядит процесс разработки PostgreSQL, какие инструменты я использую в своей повседневной работе, как следует оформлять патчи, и так далее. Заинтересовавшихся прошу проследовать под кат.
В этой статье я хотел бы рассказать о том, как выглядит процесс разработки PostgreSQL глазами одного из контрибьютеров в этот самый PostgreSQL. Заниматься разработкой этой СУБД я начал в декабре 2015 года, когда устроился работать в компанию Postgres Professional. То есть, не так уж давно. А значит, еще свежи воспоминания о моментах, которые поначалу казались мне не вполне очевидными. Хотелось бы их законспектировать, чтобы новым людям, приходящим в нашу команду, а также всем тем, кто желает попробовать себя в роли разработчика открытой реляционной СУБД, было легче. Я расскажу о том, как выглядит процесс разработки PostgreSQL, какие инструменты я использую в своей повседневной работе, как следует оформлять патчи, и так далее. Заинтересовавшихся прошу проследовать под кат.