Читать дальше →

ignar @ignarread-only
User
Rails: Хватит отмазываться, начинаем BDD-ить!
9 min
Кто здесь?
Когда речь заходит о тестировании существующего продукта, а тем более о разработке чего-то нового на основе изначального написания сценариев использования, различных спецификаций и тестов, то частенько можно слышать подобные вещи:
11:24:21 PM Michael: ну хз, надо пробовать 11:24:24 PM Michael: наверное так лучше 11:24:27 PM Michael: даже я думаю наверняка 11:24:36 PM Michael: но пока меня че-то останавливает 11:24:38 PM Michael: лень наверное :)
Знакомо? «Не хочется разбираться? Нет времени?» Тогда читаем дальше. В статье расскажу, как настроить свое любимое рельсовое окружении на разработку с подходом BDD и начать новую жизнь (опционально).
Алгоритмы поиска в строке
4 min
Постановка задачи поиска в строке
Часто приходится сталкиваться со специфическим поиском, так называемым поиском строки (поиском в строке). Пусть есть некоторый текст Т и слово (или образ) W. Необходимо найти первое вхождение этого слова в указанном тексте. Это действие типично для любых систем обработки текстов. (Элементы массивов Т и W – символы некоторого конечного алфавита – например, {0, 1}, или {a, …, z}, или {а, …, я}.)
Наиболее типичным приложением такой задачи является документальный поиск: задан фонд документов, состоящих из последовательности библиографических ссылок, каждая ссылка сопровождается «дескриптором», указывающим тему соответствующей ссылки. Надо найти некоторые ключевые слова, встречающиеся среди дескрипторов. Мог бы иметь место, например, запрос «Программирование» и «Java». Такой запрос можно трактовать следующим образом: существуют ли статьи, обладающие дескрипторами «Программирование» и «Java».
Поиск строки формально определяется следующим образом. Пусть задан массив Т из N элементов и массив W из M элементов, причем 0<M≤N. Поиск строки обнаруживает первое вхождение W в Т, результатом будем считать индекс i, указывающий на первое с начала строки (с начала массива Т) совпадение с образом (словом).
Пример. Требуется найти все вхождения образца W = abaa в текст T=abcabaabcabca.

Образец входит в текст только один раз, со сдвигом S=3, индекс i=4.
Избранное Хабра в PDF
3 min
Всех с наступившими!
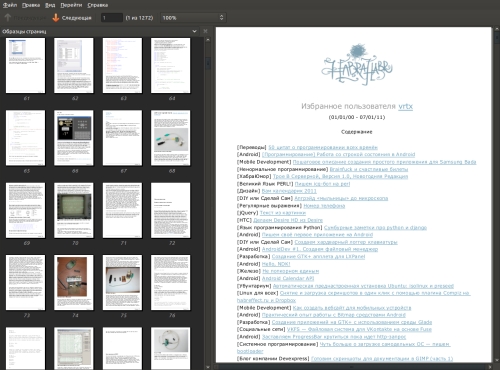
Так как я люблю все упорядочивать и каталогизировать, давно вертелась мысль завернуть избранные топики с хабра в PDF и отсортировать по датам.
Собственно выделилось немного свободного времени в праздники, решил задуманное осуществить и поделиться с хабром
UPD:
— Исправлена ошибка «too large on page» (подробнее на github) Спасибо Bifidokk и StreetAngel
— Авторы топиков сделаны ссылкой
— Добавлена возможность сохранять избранное только из указанных блогов

Так как я люблю все упорядочивать и каталогизировать, давно вертелась мысль завернуть избранные топики с хабра в PDF и отсортировать по датам.
Собственно выделилось немного свободного времени в праздники, решил задуманное осуществить и поделиться с хабром
UPD:
— Исправлена ошибка «too large on page» (подробнее на github) Спасибо Bifidokk и StreetAngel
— Авторы топиков сделаны ссылкой
— Добавлена возможность сохранять избранное только из указанных блогов
Проблема трех раскладок в Linux
2 min
Имея одновременно три раскладки (английскую, русскую, украинскую) всегда в них путался, так как отличить их не глядя на индикатор не просто, а при потребности украинской раскладки, добавлять её и убирать каждый раз неудобно. Решается очень просто, расширением русской раскладки четырьмя дополнительными украинскими буквами (є, ї, і, ґ) и апострофом (’). Способ не претендует на уникальность, но здесь никто вроде бы еще не описывал.
Видео с HighLoad++: Петр Зайцев — Диагностика и исправление проблем производительности MySQL
1 min
Добрый день,
Вот и последний обещанный видеодоклад с HighLoad:
Петр Зайцев — Диагностика и исправление проблем производительности MySQL
Часть 1 (30:56): video.mail.ru/corp/miftahetdinova/5/6.html
Часть 2 (28:35): video.mail.ru/corp/miftahetdinova/5/7.html
Часть 3 (28:33): video.mail.ru/corp/miftahetdinova/5/8.html
Часть 4 (28:29): video.mail.ru/corp/miftahetdinova/5/9.html
Часть 5 (28:13): video.mail.ru/corp/miftahetdinova/5/10.html
Часть 6 (28:10): video.mail.ru/corp/miftahetdinova/5/11.html
Часть 7 (28:13): video.mail.ru/corp/miftahetdinova/5/12.html
Часть 8 (22:50): video.mail.ru/corp/miftahetdinova/5/13.html
Часть 9 (16:01): video.mail.ru/corp/miftahetdinova/5/14.html
Часть 10 (15:02): video.mail.ru/corp/miftahetdinova/5/15.html
Также мы постараемся до конца года выложить доклады с HighLoad++ в Power Point.
Хорошего вам дня!
UPD. Уважаемые хабраюзеры! Мы хотим еще раз извиниться за невысокое качество видео, которое, тем не менее, решили выложить, т.к. знали, что темы HighLoad-a для вас крайне важны и интересны и наряду с негативным фидбеком получили очень много позитива, благодарностей и просьб продолжать выкладку докладов.
Завтра, 29 декабря, как мы уже обещали, на «Хабре» также будут выложены презентации всех докладов в PPT. В хорошем качестве ;)
Спасибо за терпение и фидбек!
Вот и последний обещанный видеодоклад с HighLoad:
Петр Зайцев — Диагностика и исправление проблем производительности MySQL
Часть 1 (30:56): video.mail.ru/corp/miftahetdinova/5/6.html
Часть 2 (28:35): video.mail.ru/corp/miftahetdinova/5/7.html
Часть 3 (28:33): video.mail.ru/corp/miftahetdinova/5/8.html
Часть 4 (28:29): video.mail.ru/corp/miftahetdinova/5/9.html
Часть 5 (28:13): video.mail.ru/corp/miftahetdinova/5/10.html
Часть 6 (28:10): video.mail.ru/corp/miftahetdinova/5/11.html
Часть 7 (28:13): video.mail.ru/corp/miftahetdinova/5/12.html
Часть 8 (22:50): video.mail.ru/corp/miftahetdinova/5/13.html
Часть 9 (16:01): video.mail.ru/corp/miftahetdinova/5/14.html
Часть 10 (15:02): video.mail.ru/corp/miftahetdinova/5/15.html
Также мы постараемся до конца года выложить доклады с HighLoad++ в Power Point.
Хорошего вам дня!
UPD. Уважаемые хабраюзеры! Мы хотим еще раз извиниться за невысокое качество видео, которое, тем не менее, решили выложить, т.к. знали, что темы HighLoad-a для вас крайне важны и интересны и наряду с негативным фидбеком получили очень много позитива, благодарностей и просьб продолжать выкладку докладов.
Завтра, 29 декабря, как мы уже обещали, на «Хабре» также будут выложены презентации всех докладов в PPT. В хорошем качестве ;)
Спасибо за терпение и фидбек!
Латентно-семантический анализ
4 min
Как находить тексты похожие по смыслу? Какие есть алгоритмы для поиска текстов одной тематики? – Вопросы регулярно возникающие на различных программистских форумах. Сегодня я расскажу об одном из подходов, которым активно пользуются поисковые гиганты и который звучит чем-то вроде мантры для SEO aka поисковых оптимизаторов. Этот подход называет латентно-семантический анализ (LSA), он же латентно-семантическое индексирование (LSI)

Алгоритм поведения привидений в игре Pac-Man
13 min
Translation
Попробовал сделать перевод вчерашнего топика-ссылки на хабре. Заранее извиняюсь, если формулировки покажутся вам кривыми, я с удовольствием приму конструктивную критику. Поехали…
Мне кажется правильным начать этот блог с темы, которая вдохновила меня в первую очередь. Не так давно я наткнулся на статью Jamey Pittman «Pac-Man Dossier», в которой приводилось очень детальное описание механики игры Pac-Man. Она показалась мне очень интересной, поэтому этот сайт — попытка собрать такую же детальную информацию об остальных играх. Но в дань уважения я все же начну с Pac-Man, а в частности, с описания алгоритма поведения привидений. Это очень интересная тема и, надеюсь, мое объяснение будет немного более понятным и доступным, чем у Джейми, потому что я сосредоточусь лишь на поведении.
Об игре:
Мне кажется правильным начать этот блог с темы, которая вдохновила меня в первую очередь. Не так давно я наткнулся на статью Jamey Pittman «Pac-Man Dossier», в которой приводилось очень детальное описание механики игры Pac-Man. Она показалась мне очень интересной, поэтому этот сайт — попытка собрать такую же детальную информацию об остальных играх. Но в дань уважения я все же начну с Pac-Man, а в частности, с описания алгоритма поведения привидений. Это очень интересная тема и, надеюсь, мое объяснение будет немного более понятным и доступным, чем у Джейми, потому что я сосредоточусь лишь на поведении.
Об игре:
«В то время все доступные игры были очень жестокими — игры о войне и космических захватчиках. Не было ни одной игры для всех сразу, а особенно, которые понравились бы девушкам. Я хотел придумать «комическую» игру, которой могли бы наслаждаться даже девушки»
— Toru Iwatani, создатель Pac-Man
Несколько фишек для изучающих английский язык
1 min
1. Анонимные чаты: omegle.com, chatroulette.com
2. Сайты-помощники: kwiz.me, kimir.org, englishtips.org
3. Подкастинг: eslpod.com, effortlessenglish.com, npr.podcast.com, businessenglishpod.com,
4. Качаем фильмы/сериалы, затем субтитры к ним. Просматривать можно с замедлением в VLC плеере чтобы лучше переваривать. Еще рекомендую комик шоу, например Important Things with Demetri Martin — не пожалеете.
5. В скайпе ищем каких нибудь индусов со статусом SkypeMe и не стенсняясь знакомимся.
6. При прочтении какой-то книги или просмотра фильма неплохо бы подготовится таким образом: берем текст, устанавливаем длину слова и частоту употребления в тексте и запускаем, например, этот скрипт (PHP): pastebin.com/m7672c2a9
В итоге имеем дайджест слов большинство из которых вы уже знаете но остальные стоит подучить. И когда вы будете смотреть фильм или читать книгу вы автоматом поймете это слово.
7. Произношение слов — ставим в Google.translate режим Русский->English и в поле текста пишем английское слово — оно без перевода встанет справа вместе с флэшкой которое произносит слово. Также forvo.com, howjsay.com
8. Социальные сервисы ответов:
answers.yahoo.com, vark.com
9. Социальные сети для изучения языка:
livemocha.com, lingq.com, italki.com
10. Остальное:
nytimes.com, ecenglish.com, urbandictionary.com
allengl.narod.ru/top/phvTOP170.htm
Надеюсь каждый нашел для себя что-то полезное:)
2. Сайты-помощники: kwiz.me, kimir.org, englishtips.org
3. Подкастинг: eslpod.com, effortlessenglish.com, npr.podcast.com, businessenglishpod.com,
4. Качаем фильмы/сериалы, затем субтитры к ним. Просматривать можно с замедлением в VLC плеере чтобы лучше переваривать. Еще рекомендую комик шоу, например Important Things with Demetri Martin — не пожалеете.
5. В скайпе ищем каких нибудь индусов со статусом SkypeMe и не стенсняясь знакомимся.
6. При прочтении какой-то книги или просмотра фильма неплохо бы подготовится таким образом: берем текст, устанавливаем длину слова и частоту употребления в тексте и запускаем, например, этот скрипт (PHP): pastebin.com/m7672c2a9
В итоге имеем дайджест слов большинство из которых вы уже знаете но остальные стоит подучить. И когда вы будете смотреть фильм или читать книгу вы автоматом поймете это слово.
7. Произношение слов — ставим в Google.translate режим Русский->English и в поле текста пишем английское слово — оно без перевода встанет справа вместе с флэшкой которое произносит слово. Также forvo.com, howjsay.com
8. Социальные сервисы ответов:
answers.yahoo.com, vark.com
9. Социальные сети для изучения языка:
livemocha.com, lingq.com, italki.com
10. Остальное:
nytimes.com, ecenglish.com, urbandictionary.com
allengl.narod.ru/top/phvTOP170.htm
Надеюсь каждый нашел для себя что-то полезное:)
Обзор свежих материалов, октябрь 2010
5 min
Этот материал продолжает серию ежемесячных обзоров свежих статей по теме интерфейсов, новых инструментов и коллекций паттернов, интересных кейсов и исторических рассказов. Из лент нескольких сотен тематических подписок отбирается примерно 5% стоящих публикаций, которыми интересно поделиться. Предыдущие материалы: апрель, май-июнь, июль, август, сентябрь.

Геттеры и сеттеры в Javascript
5 min
Javascript — очень изящный язык с кучей интересных возможностей. Большинство из этих возможностей скрыты одним неприятным фактором — Internet Explorer'ом и другим дерьмом, с которым нам приходится работать. Тем не менее, с приходом мобильных телефонов с актуальными браузерами и серверного JavaScript с нормальными движками эти возможности уже можно и нужно использовать прям сейчас. Но по привычке, даже при программировании для node.js мы стараемся писать так, чтобы оно работало в IE6+.
В этой статье я расскажу про интересный и не секретный способ указывать изящные геттеры и сеттеры и немножко покопаемся в исходниках Mootools. Частично это информация взята из статьи John Resig, частично лично мой опыт и эксперименты.
В этой статье я расскажу про интересный и не секретный способ указывать изящные геттеры и сеттеры и немножко покопаемся в исходниках Mootools. Частично это информация взята из статьи John Resig, частично лично мой опыт и эксперименты.
function Foo(bar){ this._bar = bar; } Foo.prototype = { get bar () { return this._bar; }, set bar (bar) { this._bar = bar; } };
Web Dogma. 10 правил создания сайтов для пользователей
2 min
 Сегодня мне случилось побывать на лекции Эрика Райса (Eric Reiss), специалиста по вопросам информационной архитектуры, юзабилити и user experience.
Сегодня мне случилось побывать на лекции Эрика Райса (Eric Reiss), специалиста по вопросам информационной архитектуры, юзабилити и user experience.И хоть термины эти звучат довольно страшно, а у последнего и вовсе нет перевода на русский язык, но описываемая ими предметная область важна для всех, работающих как со структурой и дизайном сайтов, так и их содержанием.
Лекция была посвящена набору правил (Эрик называет их догмой), следование которым позволит создавать сайты для пользователей, свободные от диктата технологий и моды.
Вот эти 10 правил.
Как создать вебсайт для мобильных устройств
3 min
Стили
User Agent
Один из способов включения стилей для мобильного устройства — это использование User Agent, которую получает сервер от клиента.
Этому может помочь набор скриптов: code.google.com/p/mobileesp, а также сервис от яндекса api.yandex.ru/detector
При работе с User Agent только одна проблема — это постоянно появляющиеся новые User Agent.
Бесплатный VPN от Amazon
2 min
Под хабракатом я расскажу вам, как при помощи нескольких простых действий получить себе практически бесплатный VPN в штатах:
Правило чтения по спирали
6 min
Translation
Техника, известная как «Чтение по спирали/по часовой стрелке» (“Clockwise/Spiral Rule”) позволяет любому программисту разобрать любое объявление языка Си.
Следуйте этим простым шагам:
Следуйте этим простым шагам:
Основы Linux от основателя Gentoo. Часть 2 (4/5): Обработка текста и перенаправления
6 min
Translation
В этом отрывке вы узнаете про множество интересных и полезных команд по работе с текстовыми данными в Linux. Также даны основы работы с потоками ввода-вывода в bash.
Навигация по основам Linux от основателя Gentoo:
Часть I
- BASH: основы навигации (вступление)
- Управление файлами и директориями
- Ссылки, а также удаление файлов и директорий
- Glob-подстановки (итоги и ссылки)
Часть II
- Регулярные выражения (вступление)
- Назначения папок, поиск файлов
- Управление процессами
- Обработка текста и перенаправления
- Модули ядра (итоги и ссылки)

Введение в org-mode emacs
4 min
Translation
По сути это даже не перевод, а свободное изложение моих мыслей на эту тему, после ознакомления с указанным источником. То есть — переработка. Некоторые, показавшиеся очевидными, вещи, были намеренно исключены из текста. Какие-то, показавшиеся полезными — добавлены.
Введение
Описано было довольно хорошо вот здесь.
Как его подключить
Если у Вас версия 22 и выше — он у Вас уже установлен. Если нет — установите новую версию. :)
Цвета в web-дизайне: Выбор правильного сочетания для вашего сайта
6 min
 Цвет, безусловно, является важным источником эмоции. Цвета могут устанавливать правильный тон и передавать необходимые эмоции посетителям, могут взволновать, вызвать множество чувств и стимулировать к действиям. Он является чрезвычайно мощным фактором воздействия на пользователей.
Цвет, безусловно, является важным источником эмоции. Цвета могут устанавливать правильный тон и передавать необходимые эмоции посетителям, могут взволновать, вызвать множество чувств и стимулировать к действиям. Он является чрезвычайно мощным фактором воздействия на пользователей.Псевдографика в консоли Unix/Linux. Немного больше User Friendly чем вы могли себе позволить
14 min
Привет! Бывает, хочется забыть о «скучной» консоли, разбавить ее хоть капелькой интерактива, особенно если часто приходиться делать одни и теже операции и тем более если вы пишите для облегчения своей участи скрипты. Итак, псевдографика. За мной читатель, я покажу тебе такую консоль!
Система непересекающихся множеств и её применения
10 min
Добрый день, Хабрахабр. Это еще один пост в рамках моей программы по обогащению базы данных крупнейшего IT-ресурса информацией по алгоритмам и структурам данных. Как показывает практика, этой информации многим не хватает, а необходимость встречается в самых разнообразных сферах программистской жизни.
Я продолжаю преимущественно выбирать те алгоритмы/структуры, которые легко понимаются и для которых не требуется много кода — а вот практическое значение сложно недооценить. В прошлый раз это было декартово дерево. В этот раз — система непересекающихся множеств. Она же известна под названиями disjoint set union (DSU) или Union-Find.
Поставим перед собой следующую задачу. Пускай мы оперируем элементами N видов (для простоты, здесь и далее — числами от 0 до N-1). Некоторые группы чисел объединены в множества. Также мы можем добавить в структуру новый элемент, он тем самым образует множество размера 1 из самого себя. И наконец, периодически некоторые два множества нам потребуется сливать в одно.
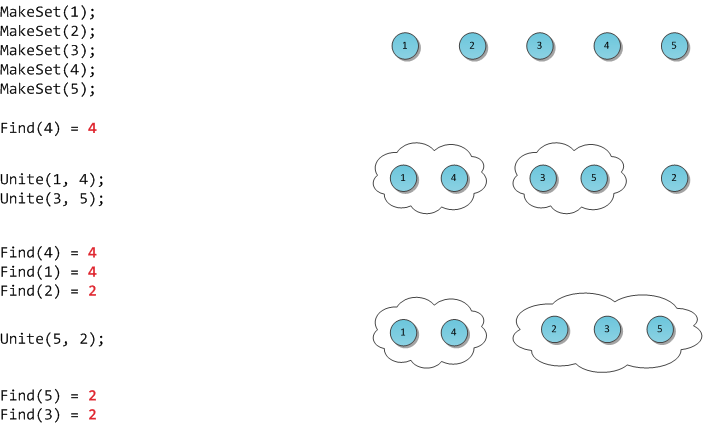
Формализируем задачу: создать быструю структуру, которая поддерживает следующие операции:
MakeSet(X) — внести в структуру новый элемент X, создать для него множество размера 1 из самого себя.
Find(X) — возвратить идентификатор множества, которому принадлежит элемент X. В качестве идентификатора мы будем выбирать один элемент из этого множества — представителя множества. Гарантируется, что для одного и того же множества представитель будет возвращаться один и тот же, иначе невозможно будет работать со структурой: не будет корректной даже проверка принадлежности двух элементов одному множеству
Unite(X, Y) — объединить два множества, в которых лежат элементы X и Y, в одно новое.
На рисунке я продемонстрирую работу такой гипотетической структуры.
Я продолжаю преимущественно выбирать те алгоритмы/структуры, которые легко понимаются и для которых не требуется много кода — а вот практическое значение сложно недооценить. В прошлый раз это было декартово дерево. В этот раз — система непересекающихся множеств. Она же известна под названиями disjoint set union (DSU) или Union-Find.
Условие
Поставим перед собой следующую задачу. Пускай мы оперируем элементами N видов (для простоты, здесь и далее — числами от 0 до N-1). Некоторые группы чисел объединены в множества. Также мы можем добавить в структуру новый элемент, он тем самым образует множество размера 1 из самого себя. И наконец, периодически некоторые два множества нам потребуется сливать в одно.
Формализируем задачу: создать быструю структуру, которая поддерживает следующие операции:
MakeSet(X) — внести в структуру новый элемент X, создать для него множество размера 1 из самого себя.
Find(X) — возвратить идентификатор множества, которому принадлежит элемент X. В качестве идентификатора мы будем выбирать один элемент из этого множества — представителя множества. Гарантируется, что для одного и того же множества представитель будет возвращаться один и тот же, иначе невозможно будет работать со структурой: не будет корректной даже проверка принадлежности двух элементов одному множеству
if (Find(X) == Find(Y)).Unite(X, Y) — объединить два множества, в которых лежат элементы X и Y, в одно новое.
На рисунке я продемонстрирую работу такой гипотетической структуры.