
Всё, что я делал после одобрения петиции по программе талантов EB-1A и до въезда в США в статусе резидента. Все формы, которые я заполнял. Каждый полученный ответ и каждый скриншот на пути.

Техдиректор в дикой природе
Всё, что я делал после одобрения петиции по программе талантов EB-1A и до въезда в США в статусе резидента. Все формы, которые я заполнял. Каждый полученный ответ и каждый скриншот на пути.

Сегодня поговорим о lock-free (или же без использования блокировок) структурах данных и атомарных операциях в Rust.
Каждый lock может стать узким местом, тормозящим всю систему. Базовые методы синхронизации, типо мьютексов и семафор, частенько (но не всегда) снижают производительность из-за блокировок и контекстных переключений.
lock-free структуры данных позволяют нескольким потокам одновременно читать и изменять данные без блокировок.

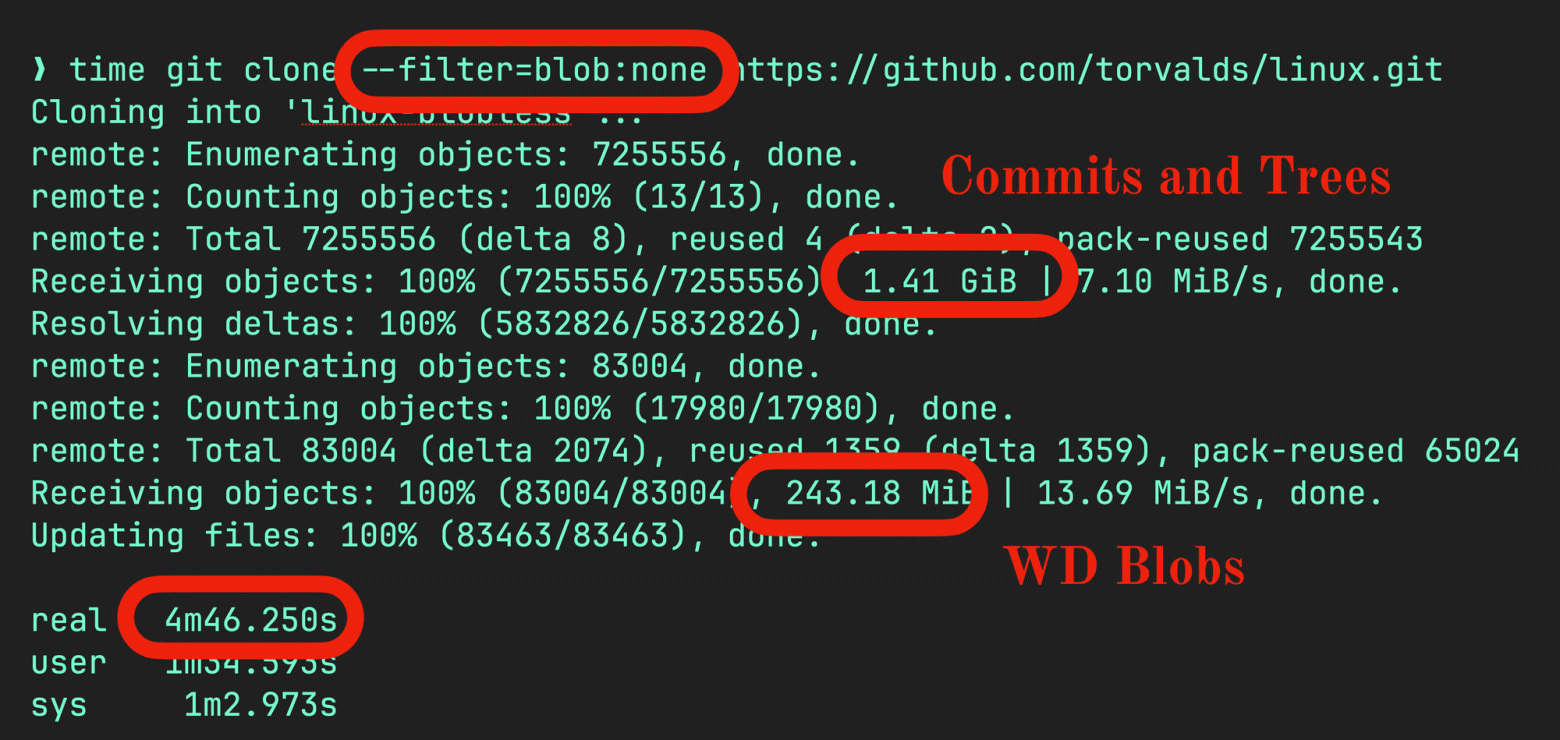
Автор оригинала Скотт Чакон — сооснователь GitHub и основатель нового клиента GitButler. Этот клиент ставит во главу угла рабочий процесс и удобство разработки, в том числе код-ревью, и не является просто очередной обёрткой над CLI git.
Вам хочется использовать ванильный Git, чтобы управлять репозиторием с объёмом 300 ГБ в 3,5 млн файлов, которые без проблем получают пуш каждые 20 секунд от 4000 разработчиков? Тогда читайте дальше!
Вот агенда блога — наша блогенда:
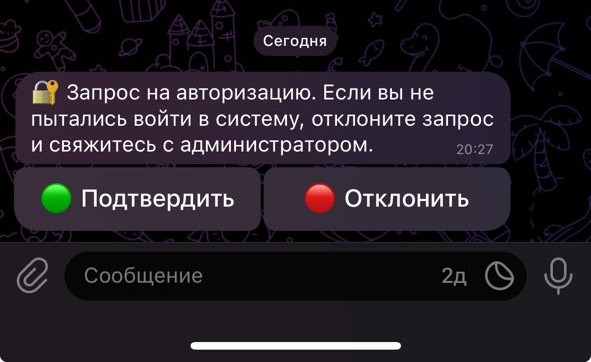
Free2FA - это бесплатное, Open Source решение для двухфакторной аутентификации с пуш-уведомлениями, основанное на FreeRADIUS, Telegram-боте и административной веб панели управления. Применялось с Cisco AnyConnect, подходит для любых систем авторизации с пользователями из Active Directory .

Всем привет, меня зовут Александр Бобряков. Я техлид в команде МТС Аналитики, занимаюсь Real-Time обработкой данных. Мы начали использовать фреймворк Apache Flink, и я решил поделиться на Хабре своим опытом внедрения этой технологии в цикле статей.
В предыдущей части «Как использовать Spring в качестве фреймворка для Flink-приложений» я рассказывал, как реализовать минимальное Flink-приложение с использованием фреймворка Spring. Мы запустили первую Flink-задачу в поднятом в docker-compose кластере, а также проверили корректность результата по соответствующим логам. В этой статье решим реальную бизнес-задачу дедупликации данных в пайплайне Kafka-to-Kafka.
HashiCorp Vault имеет в своём арсенале SSH secrets engine, который позволяет организовать защищённый доступ к вашим машинам по ssh, через создание клиентских сертификатов и одноразовых паролей. Про последнее – создание одноразовых паролей (OTP) – мы и поговорим в этой статье.

В преддверии выхода Rust 1.75.0, наполненным async trait-ами и return-position impl Trait in trait, надо разобраться, что такое impl Trait и с чем его едят.
После прочтения статьи вы сможете битбоксить с помощью новых акронимов понимать, что за наборы символов RPIT, RPITIT и т.д. используют в Rust сообществе.
Меня зовут Валя Борисов, и я — аналитик в команде Ozon. Задача нашей команды — создавать инструменты для мониторинга и анализа скорости.
Наши усилия направлены на то, чтобы в реальном времени следить за тем, как быстро работают наши сервисы и платформа. Благодаря инструментам, которые мы создаём и поддерживаем, команды разработки получают представление о том, как пользователи видят работу нашего сайта или приложения. Мы помогаем выявлять причины деградации скорости и определять узкие места в инфраструктуре.
Наши дашборды играют ключевую роль в предоставлении информации о скорости работы платформы. Вместе с командой аналитиков я занимаюсь созданием и поддержкой этой системы в Grafana. Мы стремимся делать ее не только информативной, но и быстрой, стабильной и удобной для всех пользователей. В этой статье я хочу поделиться методами и приемами, к которым мы пришли в процессе работы.
• Как понять что важно для конкретного сотрудника клиента?
• Как определить приоритеты разных контактных лиц?
• Как разглядеть союзы и разногласия между теми, кто участвует в принятии решения?
В этой статье я постарался интересно и вдумчиво описать 40 фундаментальных элементов ценности в привязке к психологическим особенностям клиентов.

DeepNude — это технология, использующая нейросети для создания изображений обнаженных тел на основе одетых фотографий или видео. Суть этой технологии заключается в том, чтобы "снять" одежду с изображения человека с помощью искусственного интеллекта и показать, как, предположительно, выглядит тело человека под одеждой.
Итак, в данной статье поговорим о пикантных и для некоторых людей непристойных темах, которые больше всего интересуют наше общество - обнаженное тело. Сделаем обзор таких сервисов как: Deepnude.ai, Deepfake.com, DeepSwap.ai, SoulGen и прочих.

Почему люди понимают линейные рисунки? Почему мы мгновенно узнаём объекты на линейных рисунках, хотя они не относятся к явлениям естественного мира? Многие исследования показывают, что люди, никогда ранее не видевшие такие изображения, могут их понимать; нам не нужно этому учиться.
Классический ответ на этот вопрос — та гипотеза, которую я буду называть Lines-As-Edges. Она гласит, что рисунки симулируют естественные образы, потому что признаки линий активируют рецепторы краёв в зрительной системе человека. Насколько я могу судить, такое убеждение широко распространено в среде исследователей зрения; многие люди вспоминают эту гипотезу, когда я говорю о восприятии рисунков, а также многие комментаторы под недавним постом в Twitter. Обобщением этой идеи становится то, что линии соответствуют некому внутреннему представлению, заставляющему нейроны реагировать на контуры объектов. Я называю эту гипотезу Line-As-Internal-Representation и расскажу о ней в этой статье.

Это полное изложение замечательного доклада Роба Пайка "Concurrency is Not Parallelism". Иллюстрации и диаграммы воссозданы, исходный код взят дословно со слайдов, за исключением комментариев, которые в некоторых местах были расширены.
В продажах, на собеседовании, и даже в разговоре с собственной мамой мы проходим по одному сценарию — по Модели Такмана. Если мы довольны результатом, значит прошли по сценарию правильно. Нет, — нет. В этой статье я постарался интересно и вдумчиво описать эту модель.
Привет, Хабр!
Меня зовут Андрей, я – специалист по оптическим системам, оптик и инженер-конструктор в одном лице.
В этой статье я продолжу публиковать фрагменты курса основ прикладной оптики, созданный несколько лет назад для внутреннего обучения CV-разработчиков организации.
Текущая лекция – не обязательная. Она не предлагает конкретных формул и способов решения, но даёт лучшее понимание того, как именно складывается изображение после объектива. Соприкасающимся с оптикой людям рекомендую ей прочитать. Более короткого и наглядного описания аберраций в русскоязычном интернете нет.

Привет, Хабр! Меня зовут Владимир Лебедев, я руковожу группой разработки департамента горнодобывающих решений компании «Рексофт».
На Хабре есть много полезных материалов на тему применения машинного зрения в промышленности. Я покажу вам перспективы использования этой технологии на карьерной технике и расскажу, куда копаем (извините за каламбур). В этой статье опишу, как с помощью нейронки можно считать циклы погрузки на фронтальных погрузчиках. Поехали!
В последние годы обширный список доменов первого уровня (top level domains, TLD) регулярно пополняется: всё чаще в дополнение к обычным доменам .com, .org, .ru, .net стали встречаться домены .aero, .club итд.
Следуя за спросом, Google анонсировал в мае 8 новых доменов, включая два неотличимых от популярных расширений файлов адреса: .zip и .mov. От остальных доменов верхнего уровня эти два отличаются тем, что соответствующие URL крайне трудно отличить от имен файлов с таким же расширением. IT и ИБ-специалисты немедленно подняли тревогу о проблемах этого TLD: возможная путаница, ошибки в обработке ссылок и новые схемы фишинга.
Не прошло и месяца, как уже были обнаружили первые примеры реального фишинга с использованием этого подарка Google скамерам. Бороться с этим можно и нужно, но не лучше ли было бы просто признать ошибку и разделегерировать эти домены насовсем?

В прошлой части был запущен эмулятор raspberry pi с консольным дистрибутивом. В этой части я расскажу, как я запускал эмулятор с рабочим столом.

В сборнике VLDB'17 вышла такая статья. В ней представлена NAM-DB, масштабируемая распределённая система баз данных, использующая удалённый прямой доступ к памяти (RDMA) — в основном, однонаправленный вариант RDMA — и инновационную технологию диспетчера временных меток (timestamp oracle) для поддержки транзакций с изоляцией мгновенного снимка (SI). NAM в данном случае означает архитектуру с прикреплением памяти к сети (network-attached-memory), где благодаря активному использованию RDMA вычислительные узлы получают возможность напрямую общаться с пулом узлов памяти.
Хотим сохранить ваше время и нервы с задачей по подсчету трафика на перекрестках.
Ярослав и Никита – наши CV-инженеры, поделились решением, которое всего за 4 шага поможет подойти к релизу с минимальной потерей времени и денег.
Статья будет полезна начинающим CV-инженерам, продуктологам, владельцам IT-продукта, маркетологам и проджект-менеджерам.