

Скорость развития технологий в наши дни поражает. Скачок научно-технического прогресса в последние годы можно сравнить разве что с темпами развития космической отрасли в период с конца 50-х по середину 70-х годов ХХ века. Как тогда присутствие человека в космосе стало реальностью, так же и сейчас повсеместная замена людей машинами уже не кажется чем-то заоблачным.
Автоматизация процессов стала полноценным «трендом» нашего времени и продолжает расширять свое влияние практически во всех сферах деятельности: начиная с сельского хозяйства и заканчивая «умными домами» или искусственным интеллектом.
Данная тенденция диктует свои правила игры и в сфере бизнеса. Игроки рынка, недостаточно инвестирующие в оптимизацию своих бизнес- и производственных процессов, в их удешевление и ускорение путем автоматизации, совсем скоро окажутся «за бортом».
Автоматизация производства – это, если хотите, уже гигиена. И речь здесь идет как о производстве автомобилей (с заменой ручной сборки конвейером), так и о производстве программного обеспечения (с заменой ручного тестирования автотестами) или предоставлении услуг связи (с заменой ручного труда телефонисток сначала на коммутационное оборудование, а затем и вовсе на новые технологии связи).
Понимая значимость автоматизации в современных реалиях, мы в компании Huawei считаем важным и полезным делиться нашим опытом автоматизации работы сетевого оборудования Huawei c пользователями нашей продукции и представляем вашему вниманию цикл постов, посвященных автоматизации.
В «первой серии» пойдет речь о средствах управления событиями, реализованных в оборудовании Huawei.




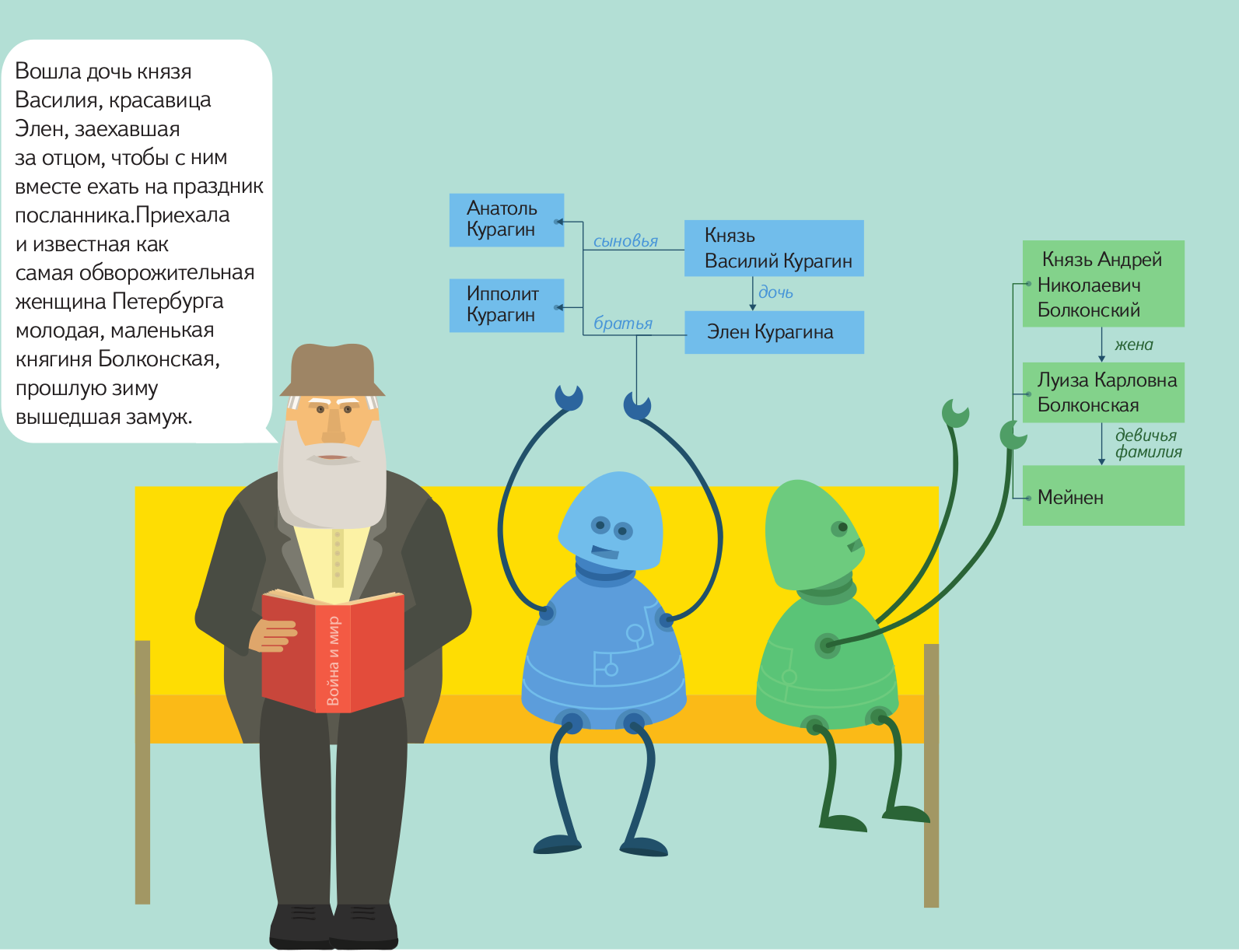


 Когда вставал вопрос о тестировании кода, я не задумываясь использовал boost::test. Для расширения кругозора попробовал Google Test Framework. Помимо всяких имеющихся в нем плюшек, в отличии от boost::test проект бурно развивается. Хотел бы поделиться приобретенными знаниями. Всем кому интересно прошу
Когда вставал вопрос о тестировании кода, я не задумываясь использовал boost::test. Для расширения кругозора попробовал Google Test Framework. Помимо всяких имеющихся в нем плюшек, в отличии от boost::test проект бурно развивается. Хотел бы поделиться приобретенными знаниями. Всем кому интересно прошу

 Статистика приходит к нам на помощь при решении многих задач, например: когда нет возможности построить детерминированную модель, когда слишком много факторов или когда нам необходимо оценить правдоподобие построенной модели с учётом имеющихся данных. Отношение к статистике неоднозначное. Есть мнение, что существует три вида лжи: ложь, наглая ложь и статистика. С другой стороны, многие «пользователи» статистики слишком ей верят, не понимая до конца, как она работает: применяя, например, тест
Статистика приходит к нам на помощь при решении многих задач, например: когда нет возможности построить детерминированную модель, когда слишком много факторов или когда нам необходимо оценить правдоподобие построенной модели с учётом имеющихся данных. Отношение к статистике неоднозначное. Есть мнение, что существует три вида лжи: ложь, наглая ложь и статистика. С другой стороны, многие «пользователи» статистики слишком ей верят, не понимая до конца, как она работает: применяя, например, тест {kind=link}