Статья посвящена языку ассемблер с учетом актуальных реалий. Представлены преимущества и отличия от ЯВУ, произведено небольшое сравнение компиляторов, скрупулёзно собрано значительное количество лучшей тематической литературы.

Computer Vision & Graphics RnD
Приветствую тебя, Хабр! Наверняка вы заметили, что тема стилизации фотографий под различные художественные стили активно обсуждается в этих ваших интернетах. Читая все эти популярные статьи, вы можете подумать, что под капотом этих приложений творится магия, и нейронная сеть действительно фантазирует и перерисовывает изображение с нуля. Так уж получилось, что наша команда столкнулась с подобной задачей: в рамках внутрикорпоративного хакатона мы сделали стилизацию видео, т.к. приложение для фоточек уже было. В этом посте мы с вами разберемся, как это сеть "перерисовывает" изображения, и разберем статьи, благодаря которым это стало возможно. Рекомендую ознакомиться с прошлым постом перед прочтением этого материала и вообще с основами сверточных нейронных сетей. Вас ждет немного формул, немного кода (примеры я буду приводить на Theano и Lasagne), а также много картинок. Этот пост построен в хронологическом порядке появления статей и, соответственно, самих идей. Иногда я буду его разбавлять нашим недавним опытом. Вот вам мальчик из ада для привлечения внимания.

Недавно мы открыли для внешних пользователей Яндекс.Трекер – нашу систему управления задачами и процессами. В Яндексе его используют не только для создания сервисов, но даже для закупки печенья на кухни.
Как известно, чем меньше компания, тем более простые инструменты она может использовать. Если с утра вы можете поздороваться с каждым сотрудником лично, то вам хватит для работы даже чата в Telegram. Когда появляются отдельные команды, не только поприветствовать каждого лично не получится, но и в статусах задач можно запутаться.

Облако из слов в заголовках тикетов во внутреннем Яндекс.Трекере
На таком этапе важно сохранять прозрачность процессов: все стороны должны иметь возможность в любой момент узнать о ходе работы над задачей или, например, оставить свой комментарий, который не пропадёт в потоке рабочего чата. Для небольших команд трекер – это и вовсе своего рода новостная лента с последними новостями из жизни их компании.
Сегодня мы расскажем читателям Хабрахабра, почему Яндекс решил создать свой трекер, как он устроен внутри, и с какими сложностями нам пришлось столкнуться, открывая его наружу.


Всем привет! Настало время пополнить наш с вами алгоритмический арсенал.
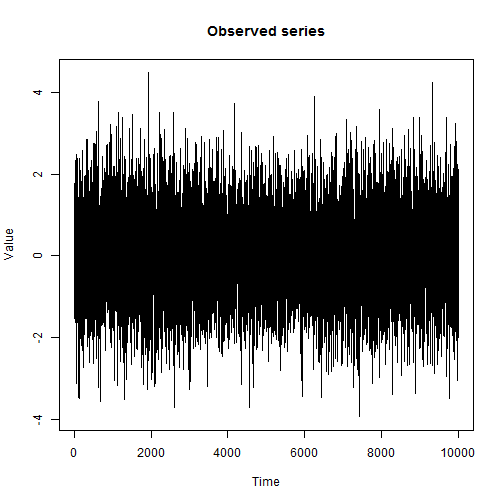
Сегодня мы основательно разберем один из наиболее популярных и применяемых на практике алгоритмов машинного обучения — градиентный бустинг. О том, откуда у бустинга растут корни и что на самом деле творится под капотом алгоритма — в нашем красочном путешествии в мир бустинга под катом.
UPD 01.2022: С февраля 2022 г. ML-курс ODS на русском возрождается под руководством Петра Ермакова couatl. Для русскоязычной аудитории это предпочтительный вариант (c этими статьями на Хабре – в подкрепление), англоговорящим рекомендуется mlcourse.ai в режиме самостоятельного прохождения.
Видеозапись лекции по мотивам этой статьи в рамках второго запуска открытого курса (сентябрь-ноябрь 2017).
 Я хотел бы рассказать о том, как создал проект по распознаванию рукописного ввода цифр с моделями, которые дообучаются на нарисованных пользователями цифрах. Используется две модели: простая нейронная сеть (FNN) на чистом numpy и сверточная сеть (CNN) на Tensorflow. Вы сможете узнать, как сделать практически с нуля следующее:
Я хотел бы рассказать о том, как создал проект по распознаванию рукописного ввода цифр с моделями, которые дообучаются на нарисованных пользователями цифрах. Используется две модели: простая нейронная сеть (FNN) на чистом numpy и сверточная сеть (CNN) на Tensorflow. Вы сможете узнать, как сделать практически с нуля следующее:


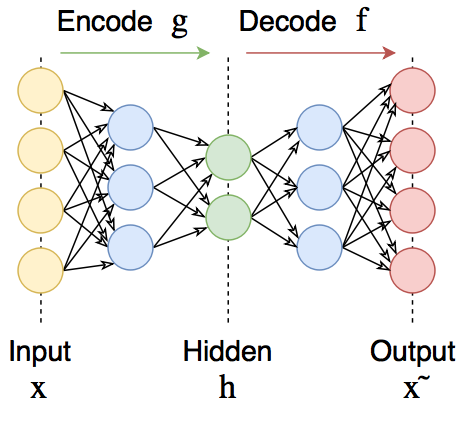


Всем привет!

Вот мы постепенно и дошли до продвинутых методов машинного обучения. Сегодня обсудим, как вообще подступиться к обучению модели, если данных гигабайты или десятки гигабайт. Обсудим приемы, позволяющие это делать: стохастический градиентный спуск (SGD) и хэширование признаков, посмотрим на примеры применения библиотеки Vowpal Wabbit.
UPD 01.2022: С февраля 2022 г. ML-курс ODS на русском возрождается под руководством Петра Ермакова couatl. Для русскоязычной аудитории это предпочтительный вариант (c этими статьями на Хабре – в подкрепление), англоговорящим рекомендуется mlcourse.ai в режиме самостоятельного прохождения.
Видеозапись лекции по мотивам этой статьи в рамках второго запуска открытого курса (сентябрь-ноябрь 2017).
Привет всем! Приглашаем изучить седьмую тему нашего открытого курса машинного обучения!
 Данное занятие мы посвятим методам обучения без учителя (unsupervised learning), в частности методу главных компонент (PCA — principal component analysis) и кластеризации. Вы узнаете, зачем снижать размерность в данных, как это делать и какие есть способы группирования схожих наблюдений в данных.
Данное занятие мы посвятим методам обучения без учителя (unsupervised learning), в частности методу главных компонент (PCA — principal component analysis) и кластеризации. Вы узнаете, зачем снижать размерность в данных, как это делать и какие есть способы группирования схожих наблюдений в данных.
UPD 01.2022: С февраля 2022 г. ML-курс ODS на русском возрождается под руководством Петра Ермакова couatl. Для русскоязычной аудитории это предпочтительный вариант (c этими статьями на Хабре – в подкрепление), англоговорящим рекомендуется mlcourse.ai в режиме самостоятельного прохождения.
Видеозапись лекции по мотивам этой статьи в рамках второго запуска открытого курса (сентябрь-ноябрь 2017).
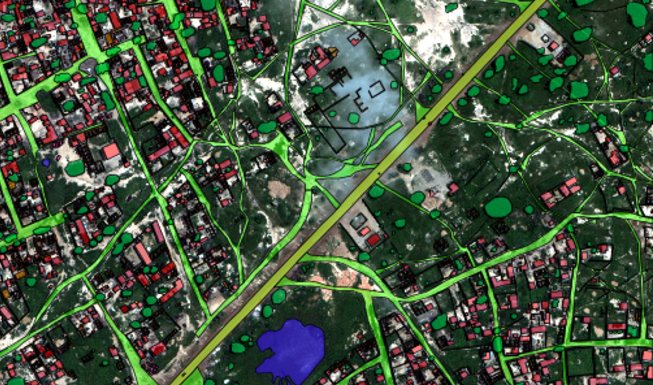

PyTorch — современная библиотека глубокого обучения, развивающаяся под крылом Facebook. Она не похожа на другие популярные библиотеки, такие как Caffe, Theano и TensorFlow. Она позволяет исследователям воплощать в жизнь свои самые смелые фантазии, а инженерам с лёгкостью эти фантазии имплементировать.
Данная статья представляет собой лаконичное введение в PyTorch и предназначена для быстрого ознакомления с библиотекой и формирования понимания её основных особенностей и её местоположения среди остальных библиотек глубокого обучения.