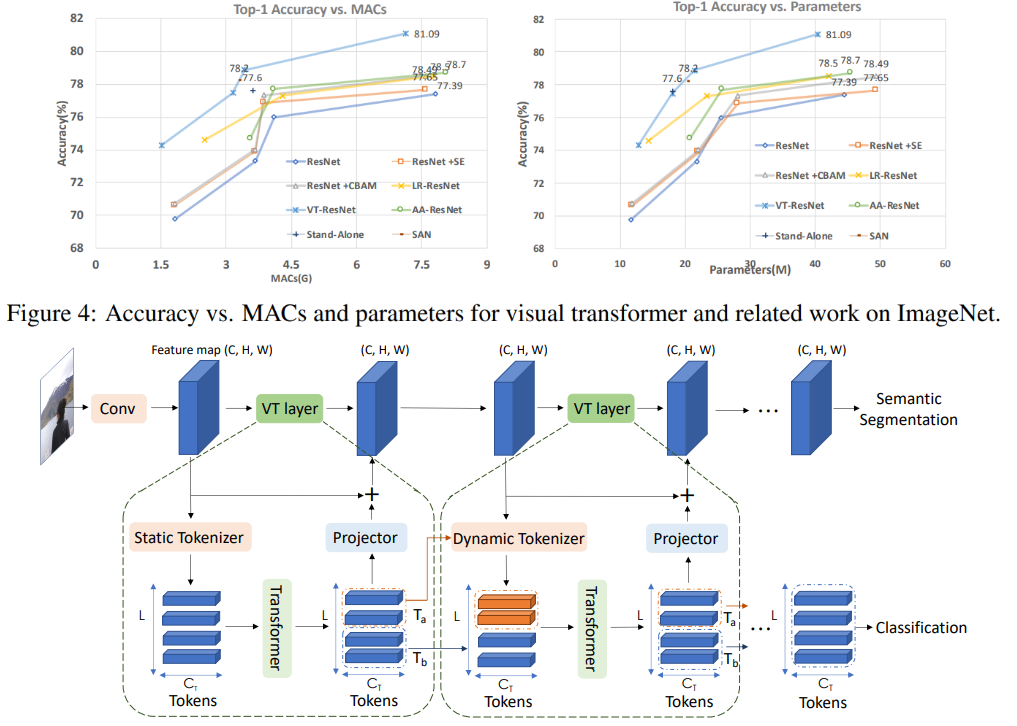
Права и обязанности заказчика, веб-студии и дизайнера могут быть совершенно разными в зависимости от подписанных документов и, самое главное, от сохранности этих документов, даже если они были подписаны. А для объектов авторского права, для которых установлена законом обязательная регистрация, ещё и в зависимости от действия или бездействия после подписания договора, акта о передаче исключительных прав. Четвёртая глава ГК РФ сложная и таит в себе массу потенциальных граблей, на которые могут наступить те, кто заказывает услуги, результатом которых являются объекты авторского права.