
Эта статья — частичный перевод одной интересной статьи с sqlite.org, в которой подробно рассматривается реализация транзакций в SQLite. На самом деле я очень редко работаю с SQLite, но тем не менее мне очень понравилось это чтиво. Поэтому если хотите просто развить кругозор — будет интересно почитать. Первые две секции не включены в перевод, так как там нет ничего интересного, да и мне лень их набивать (пост и так огромный).
Мы начнём с обзора шагов, которые SQLite предпринимает, чтобы совершить атомарный коммит транзакции, которая затрагивает только один файл базы данных. Детали формата файлов, которые используются для защиты от повреждения БД и техники, которые применяются для коммита в несколько БД будут показаны ниже.
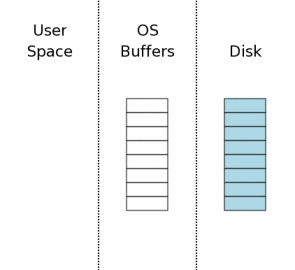
Состояние системы, когда соединение с БД только что было поднято, поверхностно изображено на рисунке справа. Справа показана информация, которая хранится на энерго-независимом носителе. Каждый прямоугольник — это сектор. Синий цвет говорит о том, что этот сектор содержит оригинальные данные. Посередине изображён дисковый кеш операционной системы. В самом начале нашего примера кеш холодный, это изображено белым цветом. На левой части рисунка — содержимое оперативной памяти процесса, который использует SQLite. Соединение с БД только что было открыто, и никакой информации прочитано не было.
3.0 Однофайловый коммит
Мы начнём с обзора шагов, которые SQLite предпринимает, чтобы совершить атомарный коммит транзакции, которая затрагивает только один файл базы данных. Детали формата файлов, которые используются для защиты от повреждения БД и техники, которые применяются для коммита в несколько БД будут показаны ниже.
3.1 Начальное состояние
Состояние системы, когда соединение с БД только что было поднято, поверхностно изображено на рисунке справа. Справа показана информация, которая хранится на энерго-независимом носителе. Каждый прямоугольник — это сектор. Синий цвет говорит о том, что этот сектор содержит оригинальные данные. Посередине изображён дисковый кеш операционной системы. В самом начале нашего примера кеш холодный, это изображено белым цветом. На левой части рисунка — содержимое оперативной памяти процесса, который использует SQLite. Соединение с БД только что было открыто, и никакой информации прочитано не было.


 На Хабре уже был
На Хабре уже был 
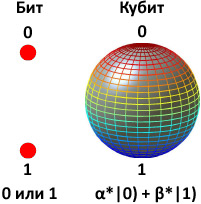 Хотя квантовые компьютеры существуют пока только в теории, но это не мешает делать обоснованные предположения об их будущей архитектуре и, что более важно, об интерфейсе взаимодействия с ними. Таким образом, уже сейчас есть возможность проектировать программные симуляторы квантовых компьютеров — и писать софт.
Хотя квантовые компьютеры существуют пока только в теории, но это не мешает делать обоснованные предположения об их будущей архитектуре и, что более важно, об интерфейсе взаимодействия с ними. Таким образом, уже сейчас есть возможность проектировать программные симуляторы квантовых компьютеров — и писать софт. 
 Шесть месяцев назад ребром
Шесть месяцев назад ребром 
 На этой неделе мы выкладывали
На этой неделе мы выкладывали  Некоторое время назад зам.главы московского офиса разработки Badoo Алексей Рыбак и ведущие IT-Компот записали выпуск подкаста «Архитектура высоконагруженных приложений. Масштабирование распределенных систем".
Некоторое время назад зам.главы московского офиса разработки Badoo Алексей Рыбак и ведущие IT-Компот записали выпуск подкаста «Архитектура высоконагруженных приложений. Масштабирование распределенных систем".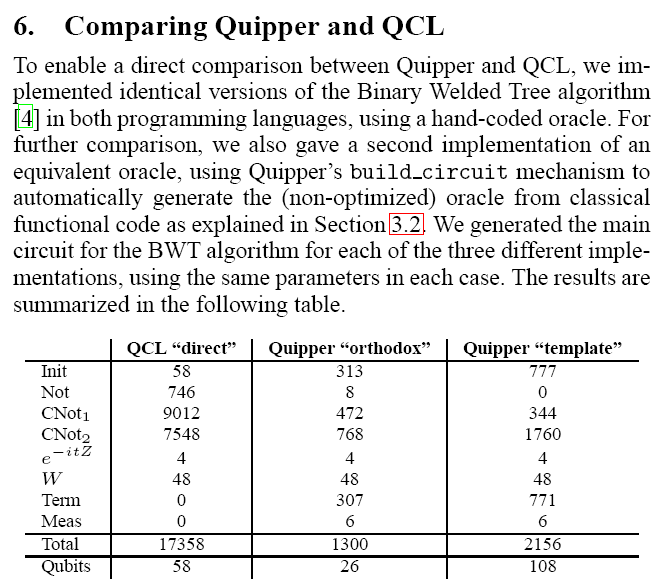{kind=link}