Рейтинг русскоязычных энкодеров предложений

Энкодер предложений (sentence encoder) – это модель, которая сопоставляет коротким текстам векторы в многомерном пространстве, причём так, что у текстов, похожих по смыслу, и векторы тоже похожи. Обычно для этой цели используются нейросети, а полученные векторы называются эмбеддингами. Они полезны для кучи задач, например, few-shot классификации текстов, семантического поиска, или оценки качества перефразирования.
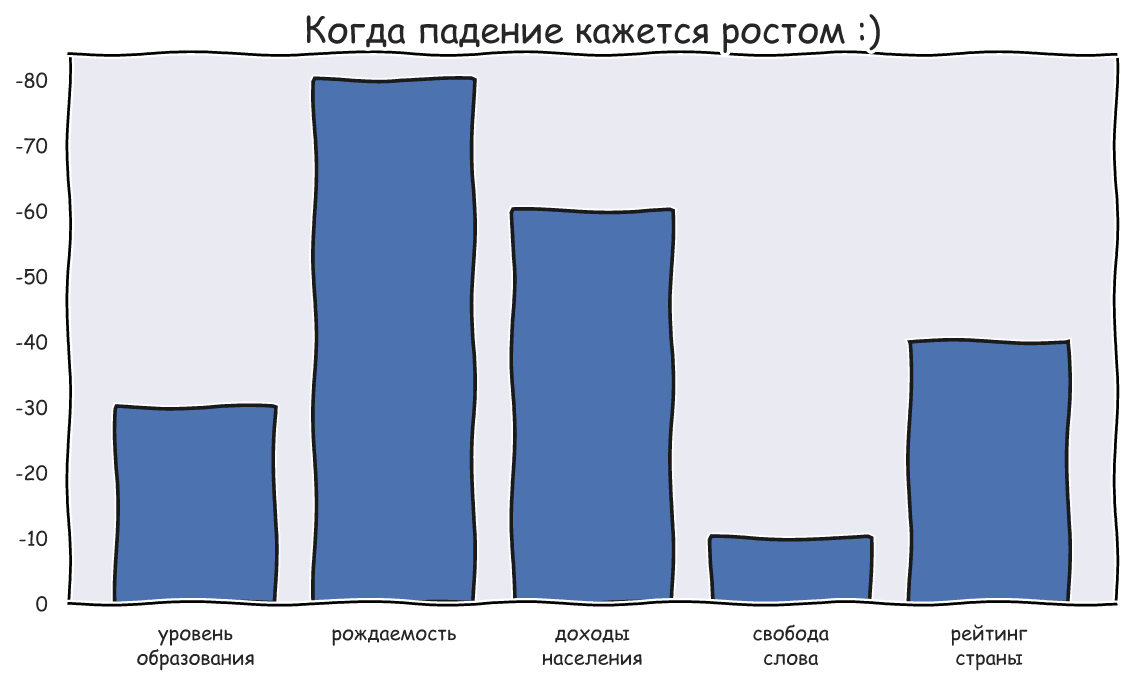
Но некоторые из таких полезных моделей занимают очень много памяти или работают медленно, особенно на обычных CPU. Можно ли выбрать наилучший энкодер предложений с учётом качества, быстродействия, и памяти? Я сравнил 25 энкодеров на 10 задачах и составил их рейтинг. Самой качественной моделью оказался mUSE, самой быстрой из предобученных – FastText, а по балансу скорости и качества победил rubert-tiny2. Код бенчмарка выложен в репозитории encodechka, а подробности – под катом.



 Сначала я хотел честно и подробно написать о методах снижения размерности данных —
Сначала я хотел честно и подробно написать о методах снижения размерности данных —