Возможно вы уже догадались, что речь пойдет о

Пользователь
 В этом посте я хочу подробно рассказать о моём опыте переезда на работу PHP-разработчиком в Германию — от момента, когда есть просто желание переехать, но не знаешь что и как делать, до момента, когда уже переехал, вселился в квартиру и получил вид на жительство. Кроме того, в конце поста я приведу немного полезной информации и ссылок по переезду в некоторые другие страны.
В этом посте я хочу подробно рассказать о моём опыте переезда на работу PHP-разработчиком в Германию — от момента, когда есть просто желание переехать, но не знаешь что и как делать, до момента, когда уже переехал, вселился в квартиру и получил вид на жительство. Кроме того, в конце поста я приведу немного полезной информации и ссылок по переезду в некоторые другие страны.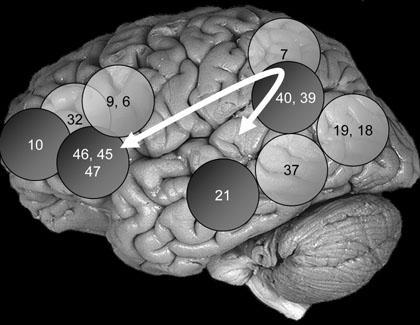



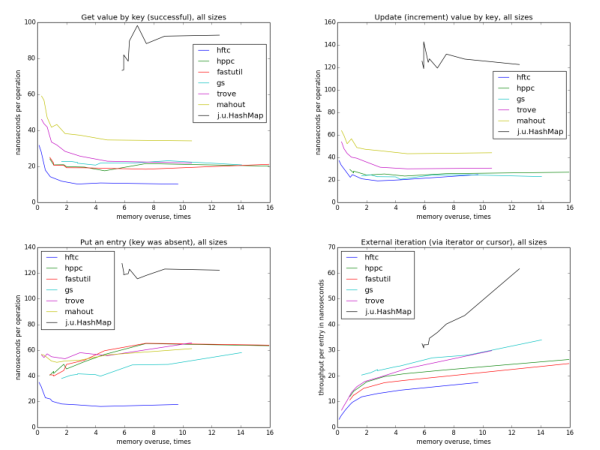
java.lang.OutOfMemoryError: PermGen space. Возникает она, как правило, после перезапуска веб-приложения внутри сервера без перезапуска самого сервера. Перезапуск веб-приложения без перезапуска сервера может понадобиться в процессе разработки, чтобы не ждать лишнее время запуска самого сервера. Если у вас задеплоено несколько веб-приложений, перезапуск всего сервера может быть гораздо дольше перезапуска одного веб-приложения. Или же весь сервер просто нельзя перезапускать, так как другие веб-приложения используются. Первое решение, которое приходит на ум – увеличить максимальный объем PermGen памяти, доступный JVM (сделать это можно опцией -XX:MaxPermSize), но это лишь отсрочит падение, после нескольких перезапусков вы снова получите OutOfMemoryError. Хорошо было бы иметь возможность сколько угодно раз перезапускать и передеплоивать веб-приложение на работающем сервере. О том, как побороть PermGen, и пойдет дальнейший разговор.
 Генетические алгоритмы были изобретены в 1950-х годах как результат первых экспериментов по моделированию естественной эволюции на компьютере. С тех пор они используются для решения самых разнообразных оптимизационных задач, где градиентные методы почему-то не подходят. Биологическая составляющая генетических алгоритмов имеет здесь очень упрощенный вид и речь в данном случае идет скорее о следовании общей идее эволюционного отбора, чем полноценному его моделированию. Тем не менее, иногда результаты работы ГА получается интерпретировать в биологическом смысле. В нашей статье мы рассказываем об опыте применения генетических алгоритмов для задачи распознавания лиц с целью получения «регионов важности» лица. Применение этого подхода позволило в среднем на 20% повысить точность распознавания нашей системы распознавания лиц.
Генетические алгоритмы были изобретены в 1950-х годах как результат первых экспериментов по моделированию естественной эволюции на компьютере. С тех пор они используются для решения самых разнообразных оптимизационных задач, где градиентные методы почему-то не подходят. Биологическая составляющая генетических алгоритмов имеет здесь очень упрощенный вид и речь в данном случае идет скорее о следовании общей идее эволюционного отбора, чем полноценному его моделированию. Тем не менее, иногда результаты работы ГА получается интерпретировать в биологическом смысле. В нашей статье мы рассказываем об опыте применения генетических алгоритмов для задачи распознавания лиц с целью получения «регионов важности» лица. Применение этого подхода позволило в среднем на 20% повысить точность распознавания нашей системы распознавания лиц.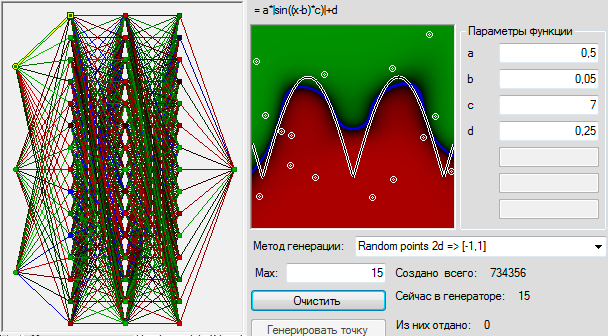 В последнее время на Хабре появилось множество статей о нейронных сетях. Из них очень интересными показались статьи о Перцептроне Розенблатта: Перцептрон Розенблатта — что забыто и придумано историей? и Какова роль первого «случайного» слоя в перцептроне Розенблатта. В них, как и во многих других очень много написано о том, что сети справляются с решением задач, и обобщают до некоторой степени свои знания. Но хотелось бы как-то визуализировать эти обобщения и процесс решения. Увидеть на практике, чему там научился перцептрон, и почувствовать, насколько успешно ему это удалось. Возможно, испытать горькую иронию относительно достижения человечества в области ИИ.
В последнее время на Хабре появилось множество статей о нейронных сетях. Из них очень интересными показались статьи о Перцептроне Розенблатта: Перцептрон Розенблатта — что забыто и придумано историей? и Какова роль первого «случайного» слоя в перцептроне Розенблатта. В них, как и во многих других очень много написано о том, что сети справляются с решением задач, и обобщают до некоторой степени свои знания. Но хотелось бы как-то визуализировать эти обобщения и процесс решения. Увидеть на практике, чему там научился перцептрон, и почувствовать, насколько успешно ему это удалось. Возможно, испытать горькую иронию относительно достижения человечества в области ИИ.