
Содержание:
- Стрелочные функции: arguments, hoisting
- Работа с контекстом
- Методы присваивания контекста
- Обработчик событий

User
Содержание:
- Стрелочные функции: arguments, hoisting
- Работа с контекстом
- Методы присваивания контекста
- Обработчик событий

Меня зовут Сергей Чугунов. Я более 10 лет занимаюсь конструированием медицинских рентгенодиагностических комплексов. Одна из моих зон ответственности — внедрение лучших практик работы с системой автоматизированного проектирования (CAD — системой). После общения с коллегами из других компаний у меня сложилось впечатление, что многие компании испытывают проблемы с хранением и поддержкой актуальности 3D моделей и чертежей. А системный подход к работе с CAD развит лишь у малой части небольших и средних фирм-разработчиков.

Привет, Хабр!
В этой статье рассмотрим, почему безобидная строчка await fetch() неожиданно превращается в тормоз, где именно она зарывает драгоценные миллисекунды — и что можно сделать с этим.

Очередной пост по личным впечатлениям, написанный в минуты отдыха (читай: прокрастинации). И, конечно, снова о работе! (irony mode:on) На этот раз — про рабочие инструменты. (irony mode:off) Основано на реальном опыте: когда-то я выстраивал систему работы с контентом в стартапе с нуля.
Когда я пришёл в новую команду, сперва просто впал в ступор: задачи разлетались по чатам, созданным непонятно кем, дедлайны плыли, контроль держался исключительно на напоминаниях. А мне в этом всём предстояло наладить выпуск материалов.
Разбирался я поэтапно, но в детали вдаваться не буду — специфические нюансы контент-менеджмента вряд ли пригодятся разработчикам, тестировщикам или дизайнерам. Зато вот этап, который применим в любой команде — выбор системы управления задачами.
Так как я за этим рынком постоянно не слежу, пришлось порядочно походить по сайтам систем и пересмотреть с десяток обзоров. После всего этого понял простую вещь: идеальной системы нет. Все они строятся вокруг одной концепции — канбан-доски.
Но какие из них действительно стоят внимания? И причём тут вообще кофе?

Привет, земляне, в этой статье я хочу затронуть вопрос интернационализации Qt-приложений, поделиться своим опытом, показать легкость работы с предоставленными инструментами и некоторые неочевидные моменты, которые могут возникнуть...


В настоящее время трудно себе представить работу сложных систем, состоящих из множества компонентов, без взаимодействия между собой при помощи различных интеграций. Ну и само собой, брокеры сообщений по популярности на сегодняшний день входят в топ самых используемых решений.
RabbitMQ и Apache Kafka — это термины, которые, возможно, на слуху у каждого, кто так или иначе работает в ИТ-сфере.
И сегодня я хотел бы познакомить вас с одним из, на мой взгляд, интереснейших инструментов для симуляции брокера RabbitMQ - сайтом RabbitMQ Simulator https://tryrabbitmq.com.
Для начала пару слов теории о брокере сообщений RabbitMQ.
RabbitMQ — это популярная система обмена сообщениями с открытым исходным кодом, которая используется для передачи данных между различными приложениями и сервисами. Она основана на протоколе AMQP (Advanced Message Queuing Protocol) и позволяет создавать надежные и масштабируемые системы обмена сообщениями.
RabbitMQ представляет собой брокер сообщений, который принимает сообщения от отправителей (publishers), хранит их в очереди и передает получателям (consumers). Он поддерживает различные модели взаимодействия, такие как точка-точка (point-to-point) и публикация-подписка (publish-subscribe).
Теперь перейдём к самому RabbitMQ Simulator-у.
Итак, RabbitMQ Simulator — это онлайн-симулятор, который предоставляет пользователям возможность познакомиться с основами работы RabbitMQ и отработать сценарии использования очередей сообщений в безопасной и понятной среде, не требующей установки самого RabbitMQ на локальной машине. И это делает его необычайно полезным инструментом для изучения принципов работы RabbitMQ, а также для тестирования различных сценариев использования.

Если вы хотите заниматься безопасностью конфиденциальной информации и разработкой соответствующих средств защиты, то вам придется получить лицензию ФСТЭК. Многие, кто прошел этот мучительно долгий процесс, хотят забыть его как страшный сон.
А что наяву? Лицензия получена, а значит ее требованиям придется соответствовать. Что именно делать потом и чем опасно бездействие, пишут редко. Что ж, давайте это исправим.

useReducer - это хук для работы с состоянием компонента. Он используется под капотом у хука useState. В этой статье разберемся с api useReducer, когда лучше использовать useReducer вместо useState и поговорим про нестандартный случай использования useReducer.

Нам приходилось слышать абсолютно разные оценки скорости (ну или наоборот — оценки потребности в железе) систем распознавания речи, отличающиеся даже на порядок. Особенно радует, когда указаны системные требования из которых следует, что метрики сильно лучше, чем лучшие state-of-the-art системы из bleeding edge статей, а на практике иногда оказывается, что метрики рассчитаны в надежде, что "покупают для галочки и никто пользоваться не будет и так сойдет". Также не помогает то, что некоторые системы работают на GPU, а некоторые нет, равно как и то, что ядра процессоров могут отличаться в разы по производительности (например старые серверные процессора с тактовой частотой 2 — 2.5 GHz против современных решений от AMD с 4+ GHz на ядро имеющие до 64 ядер). Давайте в этом вместе разберемся, на самом деле, все не так уж и сложно!
Как правило люди начинают задумываться о скорости в 3 случаях:
В этой статье мы постараемся ответить на несколько вопросов:

Главной новостью этой недели стала блокировка пользователей из России ресурсом Docker Hub. Она осуществляется по Geo IP.
Ирония в том, что у самого докера есть инструменты, чтобы обойти эту блокировку. Используем докер, чтобы обойти блокировку докера и дальше использовать докер.
В статье три проверенных мною способа, как получить доступ к ресурсу.

Весной 2023 года разработчики Depot добавили в свой сервис возможность проверять Dockerfile'ы при каждой сборке.
В этой статье они делятся десятью наиболее распространенными проблемами при линтинге Dockerfile'ов, разбирают каждую проблему и объясняют, почему она возникает и как ее решить. Авторы отмечают, что со временем список может измениться, но даже в таком виде он станет хорошей отправной точкой для оптимизации Dockerfile'ов.

Перевод транскрипции подкаста подготовлен в преддверии старта курса «Администратор Linux»

Docker Compose — это удивительный инструмент для создания рабочего
окружения для стека, используемого в вашем приложении. Он позволяет вам определять
каждый компонент вашего приложения, следуя четкому и простому синтаксису в YAML-
файлах.
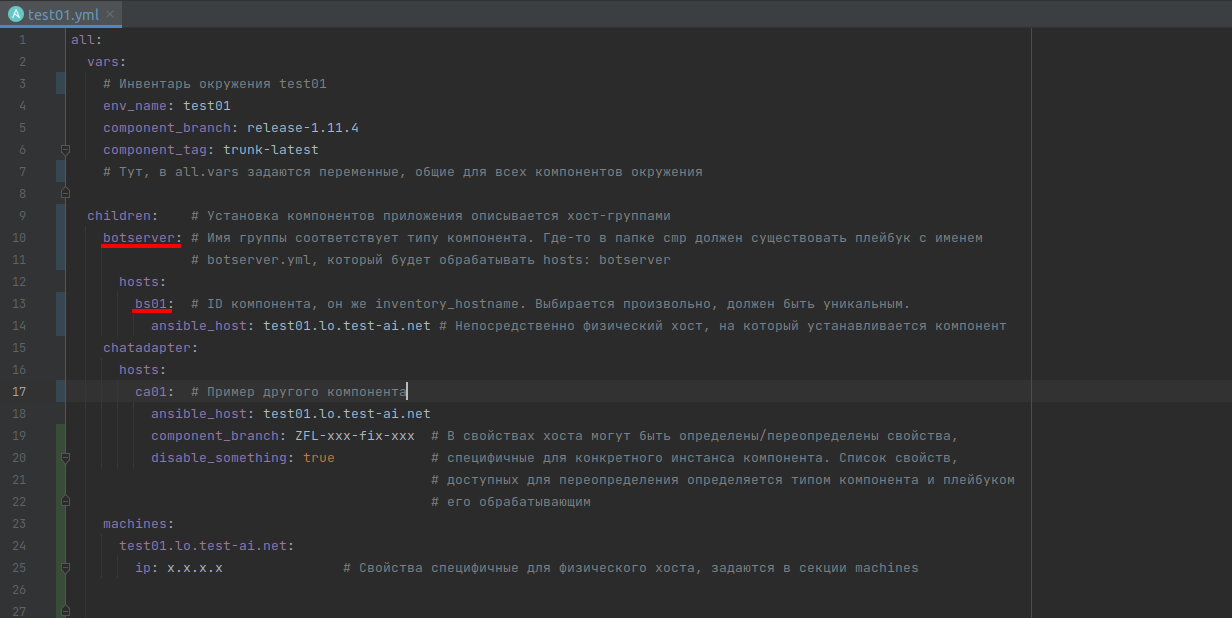
Привет, Хабр! Меня зовут Игорь Гербылев, я технический директор в компании Just AI. В этой статье я расскажу о методологии структурирования ansible-плейбуков, которую мы называем «Компонентный ансибл». Этот подход позволил нам упростить разработку и поддержку большого объёма ансибл-кода, который мы используем для настройки инфраструктуры и развёртывания наших SaaS продуктов.

Переменные очень активно используются в Ansible. Но один из неприятных моментов заключается в том, что Ansible предлагает слишком много свободы. В этом есть как свои преимущества, так и недостатки. Недостаток состоит в сложности наряду с высокой ответственностью, а преимущество — в гибкости. Давайте вспомним и упорядочим то, что мы знаем о переменных Ansible.


Команда, в которой я работаю, использует микросервисную организацию в проектах.
У каждого микросервиса свой репозиторий. Каждый микросервис это docker контейнер.
Для среды разработки, чтобы запустить все вместе, мы используем docker-compose.
Кроме того, мы используем концепцию разделения процессов сборки приложения и упаковки контейнера, чтобы не тащить исходные коды и утилиты разработки в контейнеры.
Мы столкнулись с двумя проблемами:
docker build.Для решения этих проблем мы сделали управляющий скрипт docker-project, который оказался очень удобным в работе.
Чем мы и хотим поделиться с open-source сообществом.