Перевод доклада Стивена Вольфрама, прочитанного им на фестивале SXSW 2014.
Оригинальный текст вы можете найти
здесь.
 Две недели назад я выступал с речью на конференции SXSW в Остине, Техас. Эта статья является немного доработанными тезисами доклада (это конспект текста, включающий демонстрации, от которых пришлось отказаться в процессе выступления)
Две недели назад я выступал с речью на конференции SXSW в Остине, Техас. Эта статья является немного доработанными тезисами доклада (это конспект текста, включающий демонстрации, от которых пришлось отказаться в процессе выступления):
Итак, на этот час запланировано довольно много.
В целом, мне бы хотелось рассказать историю, происходящую со мной в течение последних 40 лет, которая начинает приносить удивительные результаты только сейчас. Я имею ввиду что мы практически можем наблюдать эти результаты сегодня. Я хотел бы впервые представить вам весь спектр технологий, являющийся довольно-таки значительным результатом этих сорокалетних трудов. И я думаю что это достаточно важно.
Мне всегда нравилось представлять программы вживую. Но сегодня я собираюсь рискнуть больше обычного и продемонстрировать многие вещи, находящиеся еще на стадии тестирования. Надеюсь, что хотя бы большая часть из них работает.
Итак, основная задача в том чтобы начать относиться к вычислениям серьезно. Понять идею вычислений как таковых, а затем создать технологию, которая позволит внедрить их повсюду — после чего посмотреть к чему это приведет.
Можно сказать, я гонялся за этой идеей 40 лет. Я уже давно балансирую на стыке науки и технологий — создаю все более масштабные строительные блоки и строю из них все более высокую башню. И каждые несколько лет мне удается увидеть куда она будет расти дальше. По-моему, получается здорово. Однако, в последние несколько лет случилось нечто удивительное — своего рода великая унификация, которая ведет к технологическому
Кембрийскому взрыву. И сегодня я впервые вам частично её представлю.
Но, для начала, немного
истории. 40 лет назад я был 14-летним юнцом, который впервые прикоснулся к компьютеру (он тогда еще был размером со стол). Я не часто использовал его как нечто фундаментальное, но пытался с его помощью понять некоторые вещи из
физики, которая меня по-настоящему интересовала. В тот момент я открыл для себя некоторые важные вещи, которыми пользуюсь до сих пор. Но сейчас я понимаю что самая важная вещь, которую я понял тогда относилась вовсе не к физике: чем лучше инструменты, которые мы используем, тем глубже мы сможем копнуть. Мне не очень хорошо давалась “математика на бумаге”, а в то время это было серьезной проблемой для тех, кто хотел заниматься физикой. Однако, я осознавал, что расчеты можно делать на компьютере и начал создавать инструменты для этого. Очень скоро я с моими программами был лучше всех в математических расчетах для физики.
Вернемся в 1981-й год. В этом году случилось нечто восхитительное для 21-летнего ученого — я превратил все это в свой первый продукт и свою первую компанию. Важно то, что это заставило меня осознать — программные продукты могут стимулировать интеллектуальное мышление. Предстояло выяснить как создать язык для математических расчетов на компьютере, и мне потребовалось многое понять о вычислениях чтобы достигнуть цели. А потом я снова погрузился в основы науки уже с использованием созданных инструментов.
В итоге, я понял, что в то время как с математикой все хорошо, её фундаментальная концепция нуждается в обобщении. Я начал изучать всю вселенную всевозможных формальных систем, которая по сути является всеобщей вычислительной вселенной возможных программ. Я ставил небольшие эксперименты — как бы направлял свой вычислительный телескоп на части этой вселенной и смотрел что там было. То что я увидел, было потрясающе. Ниже я покажу вам несколько простых программ.

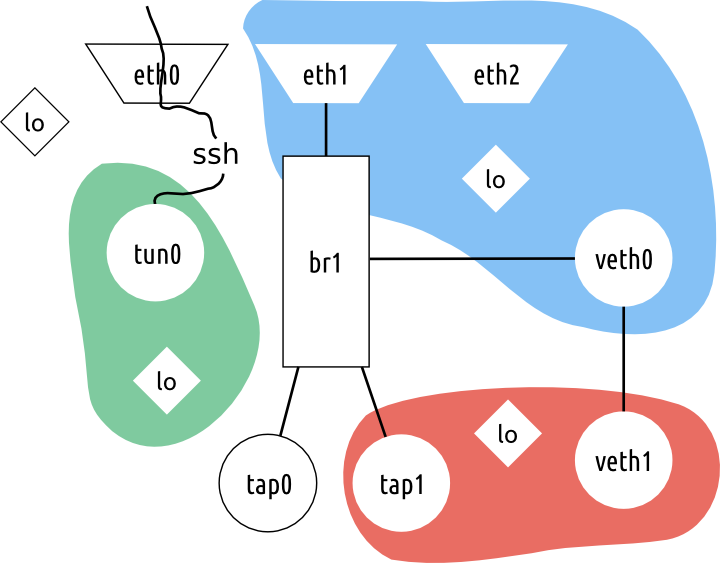
 abstract: В статье описаны продвинутые функций OpenSSH, которые позволяют сильно упростить жизнь системным администраторам и программистам, которые не боятся шелла. В отличие от большинства руководств, которые кроме ключей и -L/D/R опций ничего не описывают, я попытался собрать все интересные фичи и удобства, которые с собой несёт ssh.
abstract: В статье описаны продвинутые функций OpenSSH, которые позволяют сильно упростить жизнь системным администраторам и программистам, которые не боятся шелла. В отличие от большинства руководств, которые кроме ключей и -L/D/R опций ничего не описывают, я попытался собрать все интересные фичи и удобства, которые с собой несёт ssh. Шла холодная зима 2063 года… Вы, сидя в избушке в сибирских степях, попивая горячий чай, из ностальгических побуждений достали свой любимый раритетный смартфон образца 2014 года с поддержкой ГЛОНАСС — однако он почему-то не нашел ни одного спутника. Вдруг тишину разрезал пронзительный звонок красного правительственного телефона — голос на той стороне затараторил: оказалось все спутники ГЛОНАСС вышли из строя из-за неизвестного сбоя… (ТЗЧ? Закладки? Кто теперь разберет....)
Шла холодная зима 2063 года… Вы, сидя в избушке в сибирских степях, попивая горячий чай, из ностальгических побуждений достали свой любимый раритетный смартфон образца 2014 года с поддержкой ГЛОНАСС — однако он почему-то не нашел ни одного спутника. Вдруг тишину разрезал пронзительный звонок красного правительственного телефона — голос на той стороне затараторил: оказалось все спутники ГЛОНАСС вышли из строя из-за неизвестного сбоя… (ТЗЧ? Закладки? Кто теперь разберет....)