Мы живем во времена, когда кажется, что все просто и все есть. Нужно сделать масштабируемый проект — используем MongoDB, нужна очередь — вот RabbitMQ, нужно поднять функционал поиска — раз плюнуть: ставим Sphinx, Solr, ElasticSearch (нужное подчеркнуть).
Но здесь лишь доля правды: — при определенном везении можно поставить нужный сервер и все зашевелится. Загвоздка с поиском состоит в том, что пользователи уже порядком привыкли к высокой планке, которую задают «большие ребята», а тот поиск, что поднимется у вас «из коробки», будет явно недотягивать. И если очередь или базу данных вы можете добить железом прежде, чем будете оптимизировать, то поиск железом не добьешь.
Существую толстые книжки про настройки полнотекстового поиска, однако их мало кто читает. Сегодня я хотел бы на пальцах поговорить о том, что нужно учесть, когда вы делаете префиксный поиск с выводом результатов по мере набора слова или фразы.
Мы посмотрим, как с помощью нашего проекта
http://indexisto.com сделан поиск на сайте
http://maximonline.ru и сравним его с тем, что есть на других сайтах.
Для начала несколько примеров. Возьмем запрос
«Битва за Лос Анджелес» и представим, что его напишут неправильно
«Лос Анжелес биттва». Как видно, пользователь не знает точно, как пишется имя города, и забыл, как звучит название фильма, а также у него дрогнула рука в конце на слове «битва».
Выберем достойные проекты рунета, в которых есть префиксный поиск, и попробуем поискать там наш запрос:
| Проект |
Правильный запрос |
Неправильный запрос |
afisha.ru
|
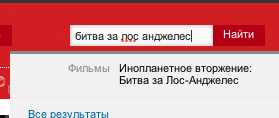
все ОК
|

Не найдено
|
ivi.ru
|
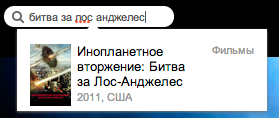
все ОК
|
Не найдено
|
vk.com
|
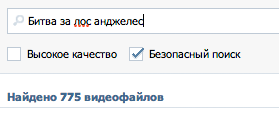
все ОК
|
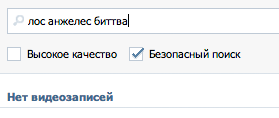
Не найдено
|
maximonline.ru
|
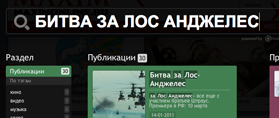
все ОК
|
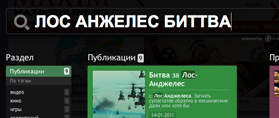
все ОК
|



 Для меня проблема заключалась в том, что я не люблю читать и чтение расцениваю исключительно как неизбежную работу, которую необходимо проделать, чтобы добыть материал из печатного вида. Но так получилось, что для повышения своей квалификации читать приходится. Я установил для себя норму — одна книга в месяц. С одной стороны, это мало, с другой, — много (если действительно придерживаться плана). Ну и раз уж мне приходится читать в принудительном порядке, это должно давать какую-либо выгоду. Каждая книга — это мучение, и я не вижу смысла тратить время на литературу, которая мне ничего не даст после. Поэтому каждый раз, попадая в книжный и держа в руках очередную книгу, я задаю себе вопрос: «А зачем?! Какой толк от этих кусков бумаги?! Что я вообще тут делаю?!». Чтобы вы не тратили время на книги, которые мне кажутся бесполезными, я решил написать небольшой обзор прочитанной за два года литературы и прочих найденных источников знаний. Весь материал ниже так или иначе связан с веб-разработкой и различными её аспектами. Ниже описаны только те книги, которые я прочитал. Те книги, которые «не осилил»/не дочитал (например, про NodeJS и пару фреймворков) не привожу.
Для меня проблема заключалась в том, что я не люблю читать и чтение расцениваю исключительно как неизбежную работу, которую необходимо проделать, чтобы добыть материал из печатного вида. Но так получилось, что для повышения своей квалификации читать приходится. Я установил для себя норму — одна книга в месяц. С одной стороны, это мало, с другой, — много (если действительно придерживаться плана). Ну и раз уж мне приходится читать в принудительном порядке, это должно давать какую-либо выгоду. Каждая книга — это мучение, и я не вижу смысла тратить время на литературу, которая мне ничего не даст после. Поэтому каждый раз, попадая в книжный и держа в руках очередную книгу, я задаю себе вопрос: «А зачем?! Какой толк от этих кусков бумаги?! Что я вообще тут делаю?!». Чтобы вы не тратили время на книги, которые мне кажутся бесполезными, я решил написать небольшой обзор прочитанной за два года литературы и прочих найденных источников знаний. Весь материал ниже так или иначе связан с веб-разработкой и различными её аспектами. Ниже описаны только те книги, которые я прочитал. Те книги, которые «не осилил»/не дочитал (например, про NodeJS и пару фреймворков) не привожу.