
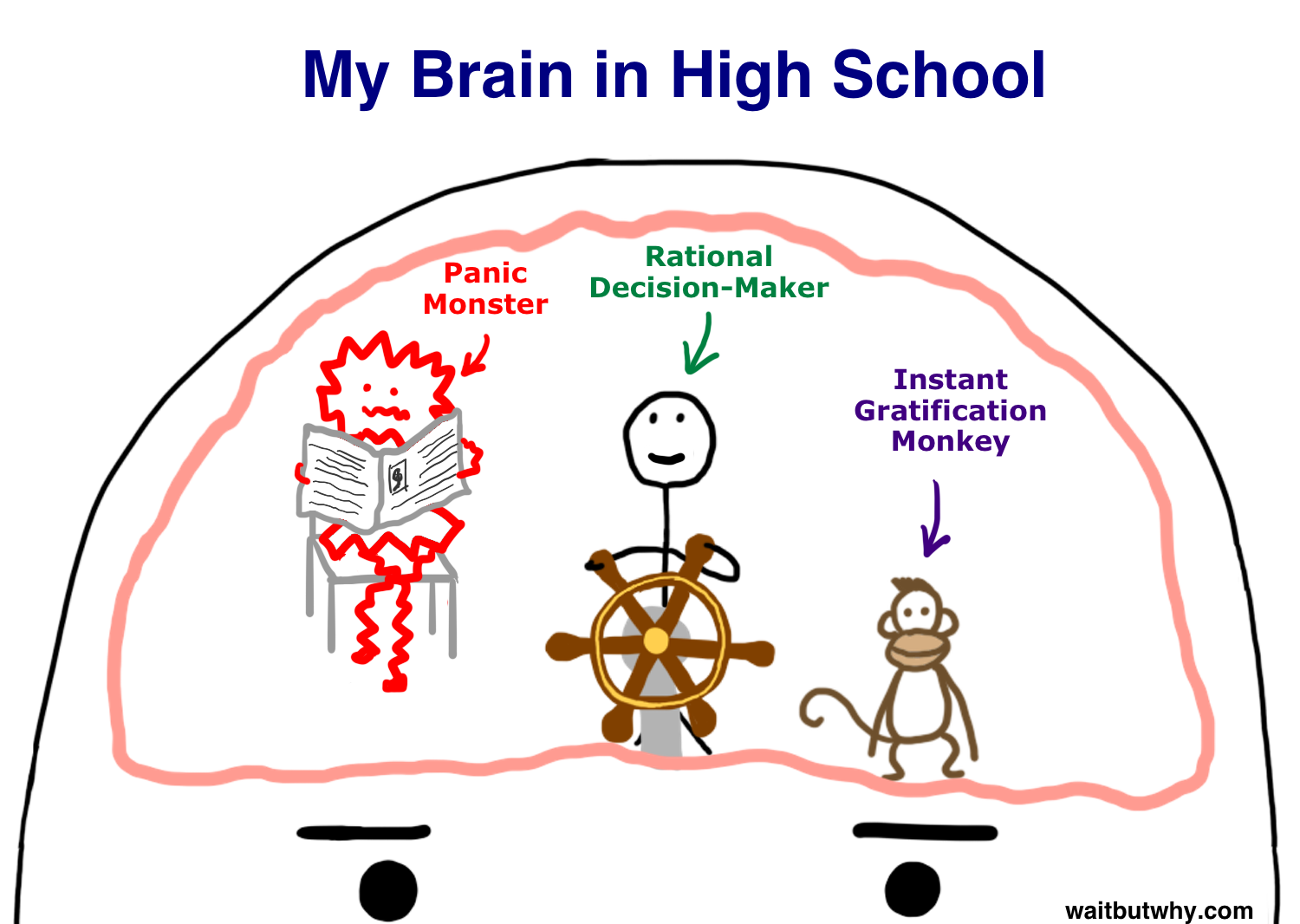
Несколько вещей гарантированно будут увеличиваться со временем: расстояния между звёздами, энтропия вселенной и бизнес-требования к ПО. Многие статьи пишут «Не усложняйте!», но не пишут почему или как это сделать. Вот вам 10 ясных примеров.
Мы, инженеры, считаем себя умнейшими людьми. Ну, поскольку мы создаём разные штуки. И эта ошибка часто приводит к оверинжинирингу. Если вы спланировали и построили 100 модулей — Бизнес всегда попросит у вас 101-ый, о котором вы никогда не задумывались. Если вы соберётесь с силами и решите 1000 проблем — они придут к вам и выложат на стол 10 000 новых. Вы считаете, что у вас всё под контролем, а на самом деле вы даже не представляете, в каком направлении вас завтра поведёт дорога.

За мои 15 лет работы программистом я ещё ни разу не видел, чтобы Бизнес выдал законченные и стабильные раз и навсегда требования к ПО. Они всегда меняются, расширяются. И это природа бизнеса, а не ошибки людей, управляющих им.
Мораль: Казино (бизнес) всегда побеждает.
1. Инженерам виднее
Мы, инженеры, считаем себя умнейшими людьми. Ну, поскольку мы создаём разные штуки. И эта ошибка часто приводит к оверинжинирингу. Если вы спланировали и построили 100 модулей — Бизнес всегда попросит у вас 101-ый, о котором вы никогда не задумывались. Если вы соберётесь с силами и решите 1000 проблем — они придут к вам и выложат на стол 10 000 новых. Вы считаете, что у вас всё под контролем, а на самом деле вы даже не представляете, в каком направлении вас завтра поведёт дорога.
За мои 15 лет работы программистом я ещё ни разу не видел, чтобы Бизнес выдал законченные и стабильные раз и навсегда требования к ПО. Они всегда меняются, расширяются. И это природа бизнеса, а не ошибки людей, управляющих им.
Мораль: Казино (бизнес) всегда побеждает.



 Добро пожаловать, или Посторонним вход воспрещён
Добро пожаловать, или Посторонним вход воспрещён


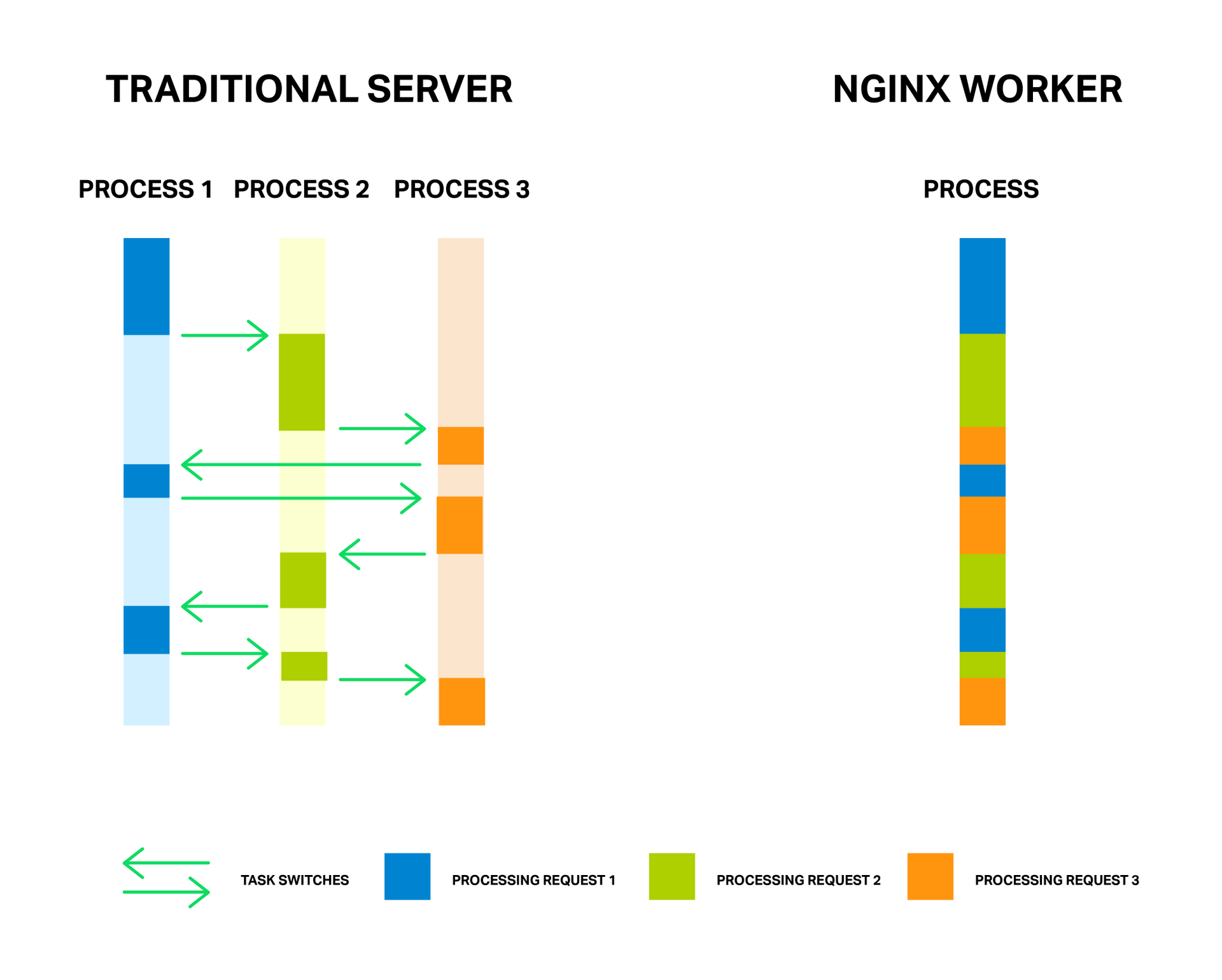
 Появилась необходимость создать облачный сервис и для реализации этого проекта было выбрано open source решение OpenShift. После успешного прохождения Getting Started и деплоя HelloWorld, возникли неожиданные трудности: официальная документация потребовала детального изучения для решения такой простой задачи, как поднять свой готовый контейнер, с произвольным содержанием. Пришлось немного разобраться и ниже простое готовое руководство. Подразумевается, что читатель знаком с docker, т.к. объяснений его команд в данном мануале нет.
Появилась необходимость создать облачный сервис и для реализации этого проекта было выбрано open source решение OpenShift. После успешного прохождения Getting Started и деплоя HelloWorld, возникли неожиданные трудности: официальная документация потребовала детального изучения для решения такой простой задачи, как поднять свой готовый контейнер, с произвольным содержанием. Пришлось немного разобраться и ниже простое готовое руководство. Подразумевается, что читатель знаком с docker, т.к. объяснений его команд в данном мануале нет.

 Посадил дед… хранилище. И выросло хранилище большое-пребольшое. Вот только толком не знал, как оно устроено. И затеял дед ревью. Позвал дед бабку, внучку, кота и мышку на семейный совет. И молвит такую тему: «Выросло у нас хранилище. Данные со всех систем стекаются, таблиц видимо-невидимо. Пользователи отчеты свои стряпают. Вроде бы все хорошо – жить да жить. Да только одна печаль – никто не знает, как оно устроено. Дисков требует видимо-невидимо – не напасешься! А тут еще пользователи ко мне ходить повадились с жалобами разными: то отчет зависает, то данные устаревшие. А то и совсем беда – приходим мы с отчетами к царю-батюшке, а цифры-то между собой не сходятся. Не ровен час – разгневается царь – не сносить тогда головы – ни мне, ни вам. Вот решил я вас собрать и посоветоваться: что делать-то будем?».
Посадил дед… хранилище. И выросло хранилище большое-пребольшое. Вот только толком не знал, как оно устроено. И затеял дед ревью. Позвал дед бабку, внучку, кота и мышку на семейный совет. И молвит такую тему: «Выросло у нас хранилище. Данные со всех систем стекаются, таблиц видимо-невидимо. Пользователи отчеты свои стряпают. Вроде бы все хорошо – жить да жить. Да только одна печаль – никто не знает, как оно устроено. Дисков требует видимо-невидимо – не напасешься! А тут еще пользователи ко мне ходить повадились с жалобами разными: то отчет зависает, то данные устаревшие. А то и совсем беда – приходим мы с отчетами к царю-батюшке, а цифры-то между собой не сходятся. Не ровен час – разгневается царь – не сносить тогда головы – ни мне, ни вам. Вот решил я вас собрать и посоветоваться: что делать-то будем?». Очень удобно, когда благодаря правильно выбранным умолчаниям все работает само и «из коробки» и не нужно ничего настраивать. Эта история о том, что выбранные умолчания должны быть работоспособными всегда, в противном случае есть риск непредвиденного отказа после многих лет беспроблемной работы.
Очень удобно, когда благодаря правильно выбранным умолчаниям все работает само и «из коробки» и не нужно ничего настраивать. Эта история о том, что выбранные умолчания должны быть работоспособными всегда, в противном случае есть риск непредвиденного отказа после многих лет беспроблемной работы.