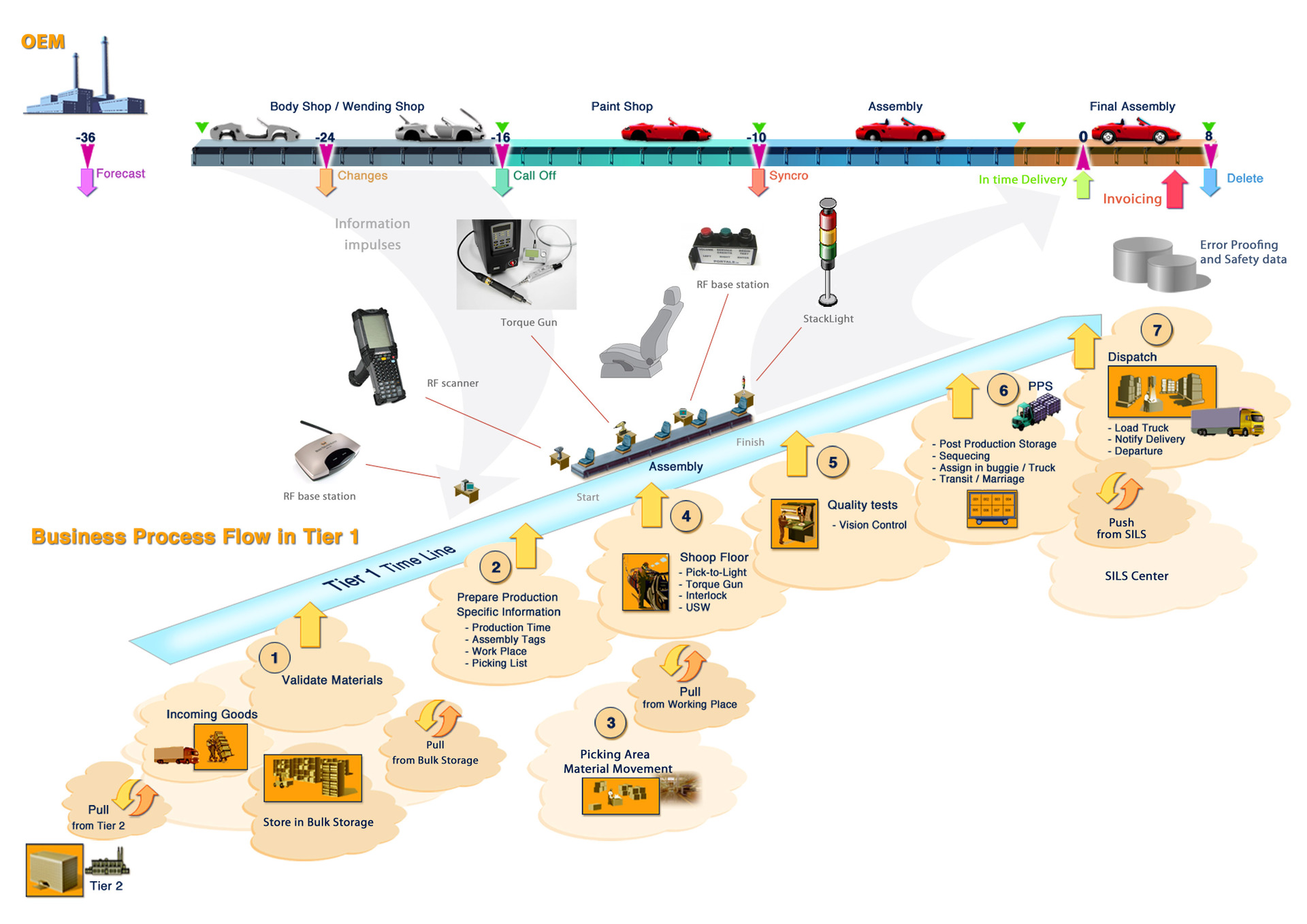
Данная статья посвящена новому Эмулятору UNL, с помощью которого вы можете создавать свои собственные виртуальные стенды для подготовки как к экзаменам CCNP/CCIE, так для решения своих инженерных задач.
Что такое UNetLab
UNenLab (Unified Networking Lab, UNL) – это мульти-вендорная и многопользовательская платформа для создания и моделирования самых различных лабораторий и дизайнов, которая позволяет смоделировать виртуальную сеть из маршрутизаторов, коммутаторов, устройств безопасности и др.
Это продолжение того же девелопера, который в своё время создал веб фронтенд для IOU. Теперь разработка iou-web завершена, разрабатывается только
UNetLab и является незаменимым инструментом для подготовки к CCIE, сетевого инженеринга, в том числе и Troubleshooting. Это, по сути, убийца GNS, IOU и даже VIRL.
UnetLab – полностью бесплатен. Вы можете запускать столько экземпляров оборудования (роутеров, коммутаторов, устройств безопасности и т.д) сколько вы хотите и какого хотите. Например, в том же Cisco VIRL Personal Edition вы ограничены 15-ю узлами и набор устройств довольно скромный. Например полноценную ASA получить не представляется возможным, равно как и маршрутизатор с Serial-интерфейсом.
Поддержка оборудования в UNetLab очень широкая. Вы можете запускать Cisco IOL-образы, образы из VIRL (vIOS-L2 и vIOS-L3), образы ASA Firewall (как портируемые 8.4(2), 9.1(5), так и официальные ASAv), образ Cisco IPS, образы XRv и CSR1000v, образы dynamips из GNS, образы Cisco vWLC и vWSA, а также образы других вендоров, таких как Juniper, HP, Checkpoint и т.д.