Поиск по Хабру не нашел подробных статей по системе Alfresco. В данной статье попробую убить сразу двух зайцев: рассказать что представляет из себя система Alfresco и как мы используем ее в нашей работе.
Поиск по Хабру не нашел подробных статей по системе Alfresco. В данной статье попробую убить сразу двух зайцев: рассказать что представляет из себя система Alfresco и как мы используем ее в нашей работе.Как хранятся документы в небольшой организации? Самое простое — на локальном диске. А если необходима совместная работа — пересылаются по почте, либо, самый популярный вариант, на сетевом диске. Еще прекрасный вариант — Google Docs, но не уверен что он широко используется в Российской практике.
Не знаю, какого размера должна достигнуть организация, чтобы в ней задумались о внедрении системы электронного документооборота, но думаю примерно это цифра в районе 50-100 сотрудников, работающих с документами.
При мысли о системе электронного документооборота первыми на ум приходят дорогие решения от известных вендоров, таких как Microsoft, EMC, 1С и т.д. Но есть и альтернатива закрытым решениям — система управления документами с открытым исходным кодом Alfresco. Или, если по-английски, то Open Source Enterprise Content Management System (ECM, CMS).
Конкуренты Alfresco — это закрытое ПО, такое как EMC Documentum, Open Text, Sharepoint. Сами разработчики Alfresco пишут о своих конкурентах, как о наследии 90-х годов, которое:
- слишком дорого стоит
- слишком сложно использовать, разворачивать, масштабировать
- слишком сложно модифицировать под свои нужды
- слишком “проприетарно”
Попробую рассказать о системе, а вы уже решайте правы ли были разработчики.

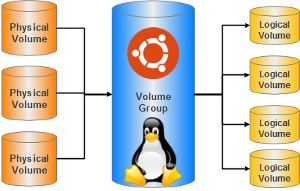 Классические разделы, на которые чаще всего разбивается жёсткий диск для установки системы и хранения данных, имею ряд существенных недостатков. Их размер очень сложно изменять, они находятся в строгой последовательности и просто взять кусочек от первого раздела и добавить к последнему не получится, если между ними есть ещё разделы. Поэтому очень часто при начальном разбиении винчестера пользователи ломают себе голову — сколько места выделить под тот или иной раздел. И почти всегда в процессе использования системы приходят к выводу, что они сделали не правильный выбор.
Классические разделы, на которые чаще всего разбивается жёсткий диск для установки системы и хранения данных, имею ряд существенных недостатков. Их размер очень сложно изменять, они находятся в строгой последовательности и просто взять кусочек от первого раздела и добавить к последнему не получится, если между ними есть ещё разделы. Поэтому очень часто при начальном разбиении винчестера пользователи ломают себе голову — сколько места выделить под тот или иной раздел. И почти всегда в процессе использования системы приходят к выводу, что они сделали не правильный выбор.
 Вероятно, всем известно и все прекрасно понимают, что главной частью в работе над программным продуктом, будь то сайт или настольное приложение, является совсем не процесс написания кода. Под словом главный я не подразумеваю время, которое уходит на этапы разработки, я имею ввиду наиболее важный этап, который определяет успешность дальнейшей работы над проектом. Трудно будет получить автомобиль, если на бумаге уже расписано создание велосипеда!
Вероятно, всем известно и все прекрасно понимают, что главной частью в работе над программным продуктом, будь то сайт или настольное приложение, является совсем не процесс написания кода. Под словом главный я не подразумеваю время, которое уходит на этапы разработки, я имею ввиду наиболее важный этап, который определяет успешность дальнейшей работы над проектом. Трудно будет получить автомобиль, если на бумаге уже расписано создание велосипеда!