Решение рассматривается (пока) только для одного сайта — того, на котором мы находимся. Идея появилась в результате того, что один пользователь сделал юзерскрипт, который переадресует страницу на кеш Гугла, если вместо статьи видим «Доступ к публикации закрыт». Понятно, что это решение будет работать лишь частично, но полного решения пока не существует. Можно повысить вероятность нахождения копии выбором результата из нескольких сервисов. Этим стал заниматься скрипт HabrAjax (наряду с 3 десятками других функций). Теперь (с версии 0.859), если пользователь увидел полупустую страницу, с которой можно перейти лишь на главную, в личную страницу автора (если повезёт) и назад, юзерскрипт предоставляет несколько альтернативных ссылок, в которых можно попытаться найти потерю. И тут начинается самое интересное, потому что ни один сервис не заточен на качественное архивирование одного сайта.

Андрей Кравчук @prefrontalCortex
Software Engineer
OAuth на практике. Аутентификация и авторизация пользователей сайта через популярные социалки
14 min
Думаю, не мне одному чрезвычайно надоели ресурсы, требующие регистрации по каждому поводу и без. С обязательной капчей, которая правильно введется только с пятого раза, с подтверждением по е-мейлу, которое обязательно свалится в спам и то — только через сутки. Придумывать каждый раз новую пару логин-пароль — забудется, вводить одно и то же на всех сайтах — небезопасно. Местами прокатывают пары вида «qwerty:qwerty» или «login:password», но, увы, далеко не везде. Надоело. Не счесть, сколько раз я, увидев надпись «только зарегистрированный пользователь может ****», просто кривился и закрывал вкладку, чтобы больше ни разу на этот сайт не заходить. Неужели администраторы ресурсов сами этого не понимают?
Тестирование: Ручное или Автоматизированное?
6 min
Хочу поделиться опытом по организации процесса тестирования, который охватывает 3 года моей работы и создание нескольких крупных систем. Описание будет затрагивать только автоматизацию «ручного» тестирования без пересечения с другими аспектами разработки ПО.
Я думаю стоит сразу упомянуть, что на всех этапах мы использовали:
Везде, где я буду говорить про автоматизацию тестирования, речь будет идти про тестирование интерфейса с подключением к внешним ресурсам (БД, файловая система, сервисы и т.п.).
Я думаю стоит сразу упомянуть, что на всех этапах мы использовали:
- Модульные тесты с покрытием около 50%
- Continuous Integration с запуском модульных тестов (в последствии и интеграционных), автоматической сборкой и выпуском релиза
- Пересечение из гибких методологий под общим названием ScrumbanXP
Везде, где я буду говорить про автоматизацию тестирования, речь будет идти про тестирование интерфейса с подключением к внешним ресурсам (БД, файловая система, сервисы и т.п.).
Основы реляционной алгебры
6 min
Реляционная алгебра базируется на теории множеств и является основой логики работы баз данных.
Когда я только изучал устройство баз данных и SQL, предварительное ознакомление с реляционной алгеброй очень помогло дальнейшим знаниям правильно уложиться в голове, и я постараюсь что бы эта статья произвела подобный эффект.
Так что если вы собираетесь начать свое обучение в этой области или вам просто стало интересно, прошу под кат.
Когда я только изучал устройство баз данных и SQL, предварительное ознакомление с реляционной алгеброй очень помогло дальнейшим знаниям правильно уложиться в голове, и я постараюсь что бы эта статья произвела подобный эффект.
Так что если вы собираетесь начать свое обучение в этой области или вам просто стало интересно, прошу под кат.
Строим карту популярности дней рождения с помощью Processing и VK API
18 min
Вступление
Несколько дней назад в блоге The Daily Viz была опубликована запись, которая привлекла внимание широкой общественности как пример простой и эффективной визуализации данных.
Визуализация представляла собой карту популярности дней рождения, реализованную как теплокарта (heatmap) в виде календаря. По вертикали располагались числа, по горизонтали — месяцы, и, глядя в эту незамысловатую таблицу, мы могли по насыщенности оттенка судить о том, насколько популярен тот или иной день в году с точки зрения деторождения.
Через какое-то время автор визуализации опубликовал в том же блоге второй пост, извинившись за то, что ввел сообщество в заблуждение, не прокомментировав должным образом исходные данные, использованные в работе над изображением. Проблема была в том, что исходный сет данных не содержал информации о реальном числе родившихся в тот или иной день людей. Информация была дана в другом виде — на каком месте (rank) находится тот или иной день в «рейтинге» популярности дней рождения.
То есть, разница между первой и второй позицией в рейтинге могла быть колоссальной (скажем, в два раза), но отличались бы они все равно только на один тон. Иными словами, визуализация не отражала реальных данных из-за того, что сет содержал лишь производные данные.
Немного подумав над этой проблемой, я решил описать собственный пример создания такой визуализации от начала до конца — т. е. от сбора данных до, собственно, отрисовки изображения. Этот пример хорош тем, что он, с одной стороны, относительно прост, а с другой — является целостным завершенным проектом с определенным интересным результатом.
Анализ закономерностей в 1300 популярных песнях
2 min
Музыканты-любители с сайта hooktheory.com решили найти закономерности в современной поп-музыке. Они провели статистический анализ аккордов 1300 песен и опубликовали результаты: какие созвучия чаще всего встречаются в музыке и как они взаимодействуют между собой.
На самом деле авторы проделали титаническую работу, потому что до сих пор не существовало открытой базы аккордов, откуда можно было просто взять информацию. В течение двух лет они медленно составляли её вручную, прослушивая по очереди все песни из хит-парадов. На их сайте аккорды синхронизированы с Youtube-видео и есть пошаговая раскладка к синтезатору и гитаре для каждой песни.
На самом деле авторы проделали титаническую работу, потому что до сих пор не существовало открытой базы аккордов, откуда можно было просто взять информацию. В течение двух лет они медленно составляли её вручную, прослушивая по очереди все песни из хит-парадов. На их сайте аккорды синхронизированы с Youtube-видео и есть пошаговая раскладка к синтезатору и гитаре для каждой песни.
Копулы — что это такое и с чем их есть
5 min
На данном ресурсе часто говорят о работе со случайными величинами — ну много где они нужны. Иногда случается так, что вам нужно определить зависимость двух случайных величин друг от друга. Тут вы воскликнете — «Пффф, дык мы ж такое в школе проходили — корреляция». Вот тут я хочу вас огорчить — корреляция Пирсона — всего лишь один из множества способов показать зависимость двух случайных величин. К тому же он линейный. То есть, если зависимость между X и Y не линейная, а, допустим, квадратичная, то есть X=Y^2, тогда корреляция Пирсона покажет отсутствие зависимости. Но мы то знаем что это не так. Если вы не задумывались об этом раньше, то сейчас у вас должны появляться идеи — «Как же так?», «А что же делать?», «Аааа, мы все умрем!» Ответы на все эти непростые вопросы я постараюсь дать под катом.
Методы, как first class citizens в C++
5 min
На днях, гуляя по багтрекеру gcc наткнулся на интересный баг, в нем используется сразу несколько возможностей C++11:
Анализируя этот баг, я подумал, что теперь можно удобно реализовать методы как first class citizens
- std::function — механизм для создания функторов — объектов функций
- non static member initialisation — механизм для инициализации членов класса вне конструктора
- lambda — тут и так все ясно. Исчерпывающие статьи были здесь.
Анализируя этот баг, я подумал, что теперь можно удобно реализовать методы как first class citizens
C++0x (С++11). Лямбда-выражения
13 min
Tutorial
Буквально на днях случайно наткнулся на Хабре на статью о лямбда-выражениях из нового (будущего) стандарта C++. Статья хорошая и даёт понять преимущества лямбда-выражений, однако, мне показалось, что статья недостаточно полная, поэтому я решил попробовать более детально изложить материал.
Что делать, если надоела смс-реклама?
5 min
Наверное, многим знакома ситуация, когда раздается звук оповещения, что на мобильный телефон пришло смс-сообщение. И вот, открывая смс-сообщение, мы видим, что какая-то организация прислала нам рекламу. Хорошо, если вы действительно подписывались на данную рассылку.
Первое, что надлежит знать, это то, что любая рекламная рассылка посредством смс-сообщений без вашего предварительного согласия является нарушением ч. 1. ст. 18 Федерального закона от 13.03.2006 N 38-ФЗ «О рекламе»:
Но что же делать, если вы не подписывались, и вам регулярно присылают рекламу посредством смс-сообщений?
Первое, что надлежит знать, это то, что любая рекламная рассылка посредством смс-сообщений без вашего предварительного согласия является нарушением ч. 1. ст. 18 Федерального закона от 13.03.2006 N 38-ФЗ «О рекламе»:
Метрики Хранилища Данных
5 min
Приветствую.
Создавая, или даже поддерживая, существующее хранилище данных, неизбежно возникает такой этап, когда множественность желаний пользователей встречается с неизбежностью физических ограничений той СУБД, которая используется для хранилища. В действительности, никто не может иметь бесконечного места на диске, процессорной мощности или сколь угодно долгого времени на обновление данных.
В этот момент у руководства могут возникнуть вопросы, если они не возникли ранее, что именно занимает так много места в БД, почему загрузка до сих пор не закончилась и прочее подобное.
Чтобы знать, что отвечать, необходимо провести учет. Создание ХД — процесс длительный, люди, разрабатывавшие архитектуру могут быть уже далеко, я не говорю уже о том, что бизнес требования меняются, иногда, так же быстро, как выходят новые версии браузера Firefox.
Создавая, или даже поддерживая, существующее хранилище данных, неизбежно возникает такой этап, когда множественность желаний пользователей встречается с неизбежностью физических ограничений той СУБД, которая используется для хранилища. В действительности, никто не может иметь бесконечного места на диске, процессорной мощности или сколь угодно долгого времени на обновление данных.
В этот момент у руководства могут возникнуть вопросы, если они не возникли ранее, что именно занимает так много места в БД, почему загрузка до сих пор не закончилась и прочее подобное.
Чтобы знать, что отвечать, необходимо провести учет. Создание ХД — процесс длительный, люди, разрабатывавшие архитектуру могут быть уже далеко, я не говорю уже о том, что бизнес требования меняются, иногда, так же быстро, как выходят новые версии браузера Firefox.
Немного о красоте T-фракталов
2 min

В 1977 году Бенуа Мандельброт написал книгу «Фрактальная геометрия природы». В ней он подробно описал, как, руководствуясь простыми правилами, нарисовать сложный и красивый самоподобный узор. И до Мандельброта, и после, и по сей день фрактальные узоры привлекают к себе внимание математиков, программистов, художников и прочих любителей красоты.
Существует множество фрактальных семейств. Сегодня я расскажу об одном из них, удивительно простом в построении его в окне вашего браузера, и достаточно красивом, что бы захотеть исследовать его свойства.
Beamer — верстаем презентации
11 min
LaTeX годится не только для составления всевозможной документации, но и для верстки качественных презентаций. При помощи пакета beamer можно создавать презентации, ничуть не уступающие презентациям PowerPoint или Impress.
Бесплатного супа больше не будет
23 min
Translation
Фундаментальный поворот к параллелизму в программировании
Автор: Герб Саттер
Перевод: Александр Качанов
The Free Lunch Is Over: A Fundamental Turn Toward Concurrency in Software
(By Herb Sutter)
Ссылка на оригинал статьи: www.gotw.ca/publications/concurrency-ddj.htm
Примечание переводчика: В данной статье дается обзор современных тенденций развития процессоров, а также, что именно эти тенденции значат для нас — программистов. Автор считает, что тенденции эти имеют фундаментальное значение, и что каждому современному программисту придется кое в чем переучиваться, чтобы не отстать от жизни.
Данная статья достаточно старая. Ей уже 7 лет, если считать с момента ее первой публикации в начале 2005 года. Помните об этом, когда будете читать перевод, так как многие вещи, которые для вас уже стали привычными, для автора статьи в 2005 году были в новинку и только-только появлялись.
Автор: Герб Саттер
Перевод: Александр Качанов
The Free Lunch Is Over: A Fundamental Turn Toward Concurrency in Software
(By Herb Sutter)
Ссылка на оригинал статьи: www.gotw.ca/publications/concurrency-ddj.htm
Примечание переводчика: В данной статье дается обзор современных тенденций развития процессоров, а также, что именно эти тенденции значат для нас — программистов. Автор считает, что тенденции эти имеют фундаментальное значение, и что каждому современному программисту придется кое в чем переучиваться, чтобы не отстать от жизни.
Данная статья достаточно старая. Ей уже 7 лет, если считать с момента ее первой публикации в начале 2005 года. Помните об этом, когда будете читать перевод, так как многие вещи, которые для вас уже стали привычными, для автора статьи в 2005 году были в новинку и только-только появлялись.
Рандомизированные деревья поиска
8 min
Tutorial
Не знаю, как вы, уважаемый читатель, а я всегда поражался контрасту между изяществом базовой идеи, заложенной в концепцию двоичных деревьев поиска, и сложностью реализации сбалансированных двоичных деревьев поиска (красно-черные деревья, АВЛ-деревья, декартовы деревья). Недавно, перелистывая в очередной раз Седжвика [1], нашел описание рандомизированных деревьев поиска (нашлась и оригинальная работа [2]) — настолько простое, что занимает оно всего треть страницы (вставка узлов, еще страница — удаление узлов). Кроме того, при ближайшем рассмотрении обнаружился дополнительный бонус в виде очень красивой реализации операции удаления узлов из дерева поиска. Далее вы найдете описание (с цветными картинками) рандомизированных деревьев поиска, реализация на С++, а также результаты небольшого авторского исследования сбалансированности описываемых деревьев.
Прогнозирование закупок: адская, но очень полезная математика
4 min
Представьте двух героев: коммерсанта Александра и сисадмина Василия. Вася, как олицетворение среднестатистического клиента, каждый вечер заходит в магазин Саши (представителя розничной сети) и покупает пиво. Саша заказывает для него 7 бутылок пива в неделю. Иногда Вася остаётся работать с ночевкой и не выходит из серверной, а иногда – после работы берёт по две бутылки пива для себя и главбуха.
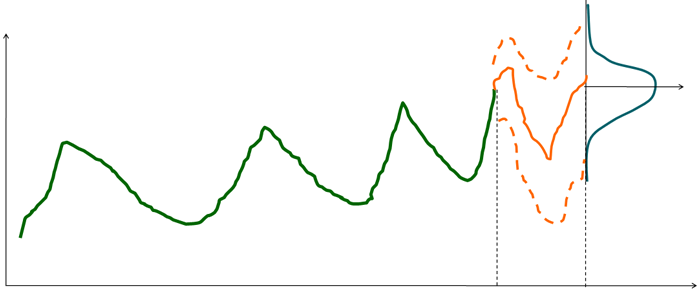
График спроса на пиво в зависимости от жизненных приключений Васи
Саша не может предсказать эти периоды, поэтому постоянно находится меж двух огней: либо купить больше товара, «заморозить» деньги и потратиться на его хранение, либо купить ровно по среднему спросу, рискуя в какой-то момент расстроить Васю и его друга бухгалтера отсутствием нужного количества пива.
График спроса на пиво в зависимости от жизненных приключений Васи
Саша не может предсказать эти периоды, поэтому постоянно находится меж двух огней: либо купить больше товара, «заморозить» деньги и потратиться на его хранение, либо купить ровно по среднему спросу, рискуя в какой-то момент расстроить Васю и его друга бухгалтера отсутствием нужного количества пива.
Алгоритм моделирования многомерного массива данных, распределенных по нормальному закону
4 min
При разработке или исследовании готовых алгоритмов часто требуется определить качество их работы. Использовать для этой цели данные из реальных источников не всегда возможно, так как их свойства зачастую неизвестны и потому нельзя спрогнозировать результат выполнения исследуемых алгоритмов. В таком случае применяется моделирование данных по одному из хорошо известных законов распределения. Применяя исследуемый алгоритм к модельным данным, можно заранее предположить, каким окажется результат его выполнения. Если он окажется удовлетворительным, можно попробовать применить его и к реальным данным. Естественно, что это относится только к непараметрическим алгоритмам, то есть не зависящим от закона распределения данных.
Чаще всего используется моделирование данных, распределённых по нормальному закону. К сожалению, MS Excel и распространённые статистические пакетаы (SPSS, Statistica) позволяют моделировать только одномерные статистические распределения. Конечно, можно составить многомерное распределение из нескольких одномерных, но только в том случае, если переменные независимы. Если же нужно исследовать данные с зависящими друг от друга переменными, придётся писать программу.
Чаще всего используется моделирование данных, распределённых по нормальному закону. К сожалению, MS Excel и распространённые статистические пакетаы (SPSS, Statistica) позволяют моделировать только одномерные статистические распределения. Конечно, можно составить многомерное распределение из нескольких одномерных, но только в том случае, если переменные независимы. Если же нужно исследовать данные с зависящими друг от друга переменными, придётся писать программу.
Web Evolution (Part 1: Interface)
7 min
Будущее не плохое и не хорошее, оно такое же как и мы

После прочтения некоторых статей на Хабре на тему «будущее...» WEB 3.0, Следующий шаг Всемирной паутины (часть 1), , Будущее социальных сетей, Золотой век Кремниевой долины окончен, и мы танцуем на её могиле, а также — относящиеся к тематике копирайта О гиках, индустрии массового искусства и о том, как копирайт убил классическую музыку, Стартап Unglue.it освобождает книги от копирайта с помощью краудфандинга, решил предоставить хабросообществу цикл статей о Web 3.0. В этих статьях я постараюсь как можно подробнее изложить свое видение на скорое будущее Интернета. Почему я решил писать о будущем? Потому как считаю, что мысли, почерпнутые из прочитанного мною, собранные в единую цельную концепцию, дополненную личными соображениями, будут полезны также и другим, особенно тем, кто хочет идти в будущее, завоевывать IT-рынок, а не заниматься тем, что уже завтра станет никому не нужным. К чему тут упомянутая тема копирайта? По моему мнению, именно концепция Web 2.0 полноценно разрушила сложившуюся схему защиты авторских прав, и как раз концепция Web 3.0 решит проблему копирайта самым неожиданным образом. Но об этом в следующих статьях. А сейчас уделим внимание теме интерфейса Web 3.0.
После прочтения некоторых статей на Хабре на тему «будущее...» WEB 3.0, Следующий шаг Всемирной паутины (часть 1), , Будущее социальных сетей, Золотой век Кремниевой долины окончен, и мы танцуем на её могиле, а также — относящиеся к тематике копирайта О гиках, индустрии массового искусства и о том, как копирайт убил классическую музыку, Стартап Unglue.it освобождает книги от копирайта с помощью краудфандинга, решил предоставить хабросообществу цикл статей о Web 3.0. В этих статьях я постараюсь как можно подробнее изложить свое видение на скорое будущее Интернета. Почему я решил писать о будущем? Потому как считаю, что мысли, почерпнутые из прочитанного мною, собранные в единую цельную концепцию, дополненную личными соображениями, будут полезны также и другим, особенно тем, кто хочет идти в будущее, завоевывать IT-рынок, а не заниматься тем, что уже завтра станет никому не нужным. К чему тут упомянутая тема копирайта? По моему мнению, именно концепция Web 2.0 полноценно разрушила сложившуюся схему защиты авторских прав, и как раз концепция Web 3.0 решит проблему копирайта самым неожиданным образом. Но об этом в следующих статьях. А сейчас уделим внимание теме интерфейса Web 3.0.
Защита для NGINX — NAXSI
3 min
Что такое NAXSI ?
NAXSI = NGINX ANTI XSS & SQL INJECTION
Проще говоря, это файрвол веб-приложений (WAF) для NGINX, помогающий в защите от XSS, SQL-инъекций, CSRF, Local & Remote file inclusions.
Отличительными особенностями его являются быстрота работы и простота настройки. Это делает его хорошей альтернативой например mod_security и апачу.
Зачем нужен NAXSI ?
Очевидно, лучше всего защищаться от вышеперечисленных атак правильно написанным кодом. Но есть ситуации, когда WAF (и в частности naxsi), поможет:
- Низкое качество кода сайта, при отсутствии возможности/ресурсов все выкинуть и переписать нормально.
- “Закрытый” код, в котором невозможно исправить ошибки.
- Неизвестное качество кода в важном для бизнеса участке.