
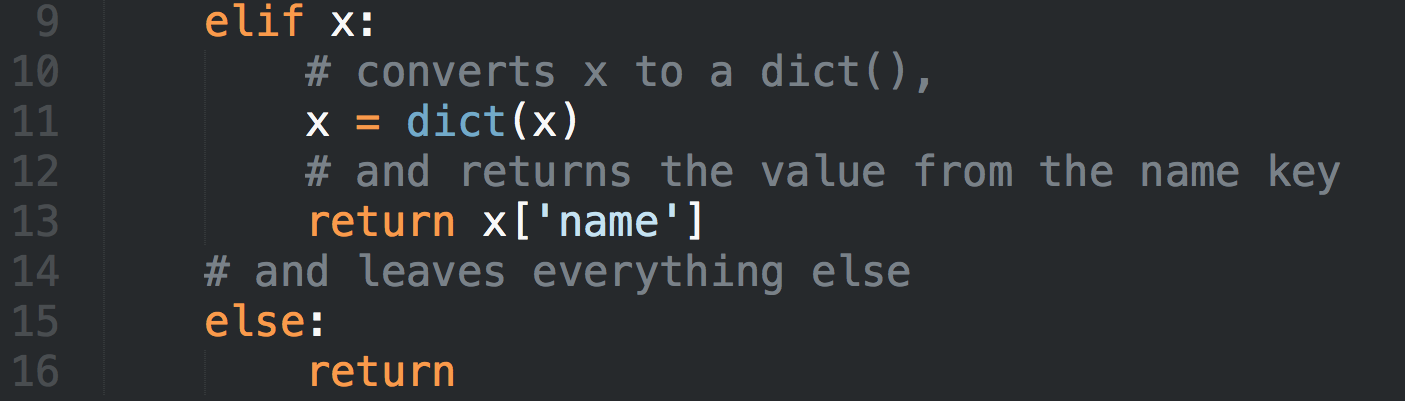
Привет сообществу!
Я Юрий Кашницкий, раньше делал здесь обзор некоторых MOOC по компьютерным наукам и искал «выбросы» среди моделей Playboy.
Сейчас я преподаю Python и машинное обучение на факультете компьютерных наук НИУ ВШЭ и в онлайн-курсе сообщества по анализу данных MLClass, а также машинное обучение и анализ больших данных в школе данных одного из российских телеком-операторов.
Почему бы воскресным вечером не поделиться с сообществом материалами по Python и обзором репозиториев по машинному обучению… В первой части будет описание репозитория GitHub с тетрадками IPython по программированию на языке Python. Во второй — пример материала курса «Машинное обучение с помощью Python». В третьей части покажу один из трюков, применяемый участниками соревнований Kaggle, конкретно, Станиславом Семеновым (4 место в текущем мировом рейтинге Kaggle). Наконец, сделаю обзор попавшихся мне классных репозиториев GitHub по программированию, анализу данных и машинному обучению на Python.

 Александр
Александр 







 Основным хранилищем метрик у нас является cassandra, мы используем её уже более трех лет. Для всех предыдущих проблем мы успешно находили решение, используя встроенные средства диагностики кассандры.
Основным хранилищем метрик у нас является cassandra, мы используем её уже более трех лет. Для всех предыдущих проблем мы успешно находили решение, используя встроенные средства диагностики кассандры. 