
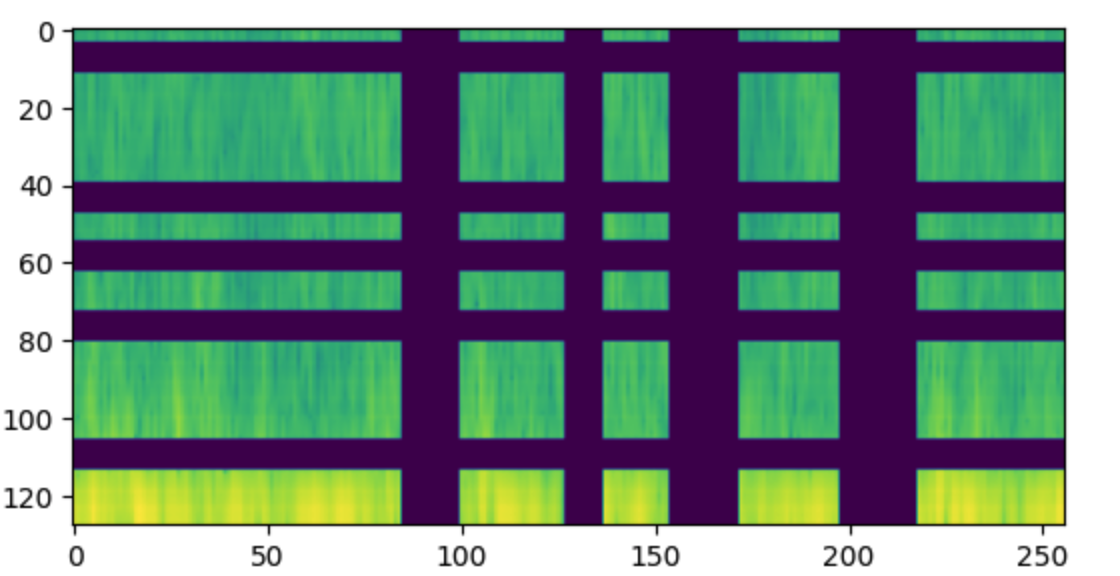
Короткая версия
После длинного вступления, будет туториал по применению аугментации XYMasking к спектрограммам от ЭЭГ. Кто экономит время - код с примерами можно найти по ссылке в документации библиотеки.
Длинная версия
Albumentations - это Open Source библиотека для аугментации изображений.
Аугментация - это умное слово, которое в переводе с русского на русский означает "преобразование".
Q: Зачем это надо?
A: Основное применение - тренировка нейронных сетей на картиночных данных, например ImageNet.
Чем больше разнообразных данных сеть видит при тренировке, тем выше шансы, что она выучит закономерности, а не просто запомнит их.
На практике, пока прошлый батч картинок обрабатывается сетью на GPU, CPU занимается подготовкой нового батча, причем к каждому изображению применяются различные аугментации. Это позволяет достигнуть большего разнообразия данных, которые видит сеть.
Благодаря такому подходу нейронная сеть никогда не видит один и тот же набор пикселей, что способствует более высокой точности и обобщающей способности.












{kind=link}