
Введение.
На той неделе darkk описал свой подход к проблеме распознавания состояния моста(сведён/разведён).
Алгоритм, описанный в статье, использовал методы компьютерного зрения для извлечения признаков из картинок и скармливал их логистической регрессии для получения оценки вероятности того, что мост сведён.
В комментариях я попросил выложить картинки, чтобы можно было и самому поиграться. darkk на просьбу откликнулся, за что ему большое спасибо.
В последние несколько лет сильную популярность обрели нейронные сети, как алгоритм, который умудряется в автоматическом режиме извлекать признаки из данных и обрабатывать их, причём делается это настолько просто с точки зрения того, кто пишет код и достигается такая высокая точность, что во многих задачах (~5% от всех задач в машинном обучении) они рвут конкурентов на британский флаг с таким отрывом, что другие алгоритмы уже даже и не рассматриваются. Одно из этих успешных для нейронных сетей направлений — работа с изображениями. После убедительной победы свёрточных нейронных сетей на соревновании ImageNet в 2012 году публика в академических и не очень кругах возбудилась настолько, что научные результаты, а также програмные продукты в этом направлении появляются чуть ли не каждый день. И, как результат, использовать нейронные сети во многих случаях стало очень просто и они превратились из "модно и молодёжно" в обыкновенный инструмент, которым пользуются специалисты по машинному обучению, да и просто все желающие.
Постановка задачи.
darkk выложил изображения моста Александра Невского в Санкт-Петербурге. 30k+ в поднятом положении, 30k+ в опущенном, 9k+ в промежуточном положении.
Задача, которую мы пытаемся решить: по изображениям со статической камеры, которая направлена на мост Александра Невского в различное время дня, ночи и времени года определить вероятность того, что мост принадлежит к классам (поднят/опущен/процессе). Я буду работать с классами поднят/опущен из тех соображений, что именно это важно с практической точки зрения.
Нейронные сети могут решать достаточно сложные задачи с изображениями, шумными данными, в условиях, когда данных для тренировки очень немного и прочей экзотикой(Например вот эта задача про отвлекающихся водителей или вот эта про сегментацию нервов. Но! Задача классификации на сбалансированных даннных, когда этих данных хватает и объект классификации практически не меняется — для нейронных сетей, да и вообще для задач машинного обученя — это где-то между просто и очень просто, что darkk и продемонстрировал, используя достаточно простой и интерпретируемый подход комбинации компьютерного зрения и машинного обучения.
Задача, которую я постараюсь решить, — это оценить, что нейронные сети могут предложить по данному вопросу.
Подготовка данных.
Не смотря на то, что нейронные сети достатоно устойчивы к шуму, тем не менее слегка почистить данные — это никогда не помешает. В данном случае — это обрезать картинку так, чтобы там было по максимуму моста и по минимуму всего остального.
Было во так:

А стало вот так:

Также надо разделить данные на три части:
- train
- validation
- test
train — 19 мая — 17 июля
validation — 18, 19, 20 июля
test — 21, 22, 23 июля
Собственно, на этом подготовка изображений закончилась. Пытаться вычленять линии, углы, какие-то другие признаки не надо.
Тренировка модели.
Определяем простую свёрточную сеть в которой свёрточные слои извлекают признаки, а последний слой по ним пытается ответить на наш вопрос.
(Я буду использовать пакет Keras с Theano в качестве backend просто потому что это дёшево и сердито.)

У нас достаточно простая задача, простая структура сети с малым числом свободных параметров, поэтому сеть замечательно сходится. Все картинки можно засунуть в память, но, не хочется, так что тренировать будем считывая картинки с диска порциями.
Тренировочный процес выглядит как-то вот так:
Using Theano backend. Using gpu device 0: GeForce GTX 980 Ti (CNMeM is disabled, cuDNN 5103) Found 59834 images belonging to 2 classes. Found 6339 images belonging to 2 classes. [2016-08-06 14:26:48.878313] Creating model Epoch 1/10 59834/59834 [==============================] - 54s - loss: 0.1785 - acc: 0.9528 - val_loss: 0.0623 - val_acc: 0.9882 Epoch 2/10 59834/59834 [==============================] - 53s - loss: 0.0400 - acc: 0.9869 - val_loss: 0.0375 - val_acc: 0.9880 Epoch 3/10 59834/59834 [==============================] - 53s - loss: 0.0320 - acc: 0.9870 - val_loss: 0.0281 - val_acc: 0.9883 Epoch 4/10 59834/59834 [==============================] - 53s - loss: 0.0273 - acc: 0.9875 - val_loss: 0.0225 - val_acc: 0.9886 Epoch 5/10 59834/59834 [==============================] - 53s - loss: 0.0228 - acc: 0.9896 - val_loss: 0.0182 - val_acc: 0.9915 Epoch 6/10 59834/59834 [==============================] - 53s - loss: 0.0189 - acc: 0.9921 - val_loss: 0.0142 - val_acc: 0.9961 Epoch 7/10 59834/59834 [==============================] - 53s - loss: 0.0158 - acc: 0.9941 - val_loss: 0.0129 - val_acc: 0.9940 Epoch 8/10 59834/59834 [==============================] - 53s - loss: 0.0137 - acc: 0.9953 - val_loss: 0.0108 - val_acc: 0.9964 Epoch 9/10 59834/59834 [==============================] - 53s - loss: 0.0118 - acc: 0.9963 - val_loss: 0.0094 - val_acc: 0.9979 Epoch 10/10 59834/59834 [==============================] - 53s - loss: 0.0111 - acc: 0.9964 - val_loss: 0.0083 - val_acc: 0.9975 [2016-08-06 14:35:46.666799] Saving model [2016-08-06 14:35:46.809798] Saving history [2016-08-06 14:35:46.810558] Evaluating on test set Found 6393 images belonging to 2 classes. [0.014433901176242065, 0.99405599874863126] ...
Или на картинках:
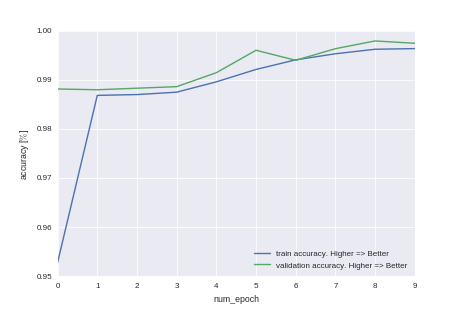
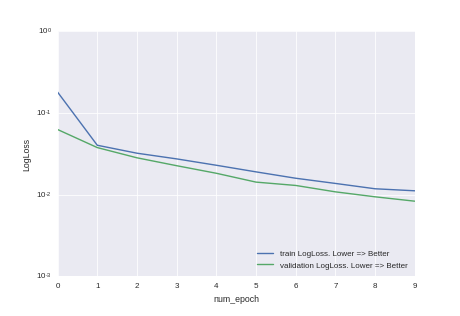
Видно, что мы не дотренировали и точность модели можно повысить, просто увеличив время тренировки. Но, как любят говорить в университах нерадивые преподаватели — это домашнее задание для желающих.
Оценка точности предсказания
Численная
Оценка точности будет производится на данных за 21-23 июля.
accuracy_score = 0.994
roc_auc_score = 0.985
log_loss_score = 0.014
Визуальная
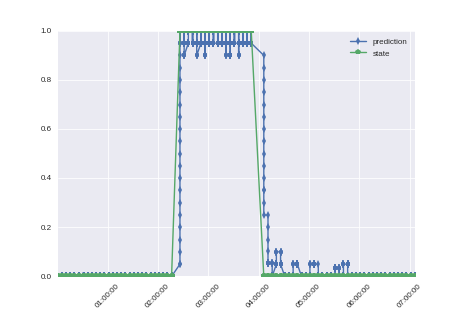
Зелёная линия — то, что отмечено на картинках.
Синяя линия — бегущее среднее по предыдущим 20 предсказаниям.
Что осталось за кадром.
Почему при тренировке модели точность на val лучше, чем на train. Ответ: => потому что на train — эта точность с dropout, а на val — нет
Почему выбрана именно такая архитектура модели. Ответ => Хочется сказать: "Но это же очевидно!", но правильный ответ, наверно, всё-таки — читаем конспект лекций на http://cs231n.github.io/, смотрим серию лекций на https://www.youtube.com/watch?v=PlhFWT7vAEw и гоняем соревнования на kaggle.com пока не прийдёт озарение в виде ответа:"Эта архитектура выбрана потому что она работает на очень похожих задачах типа MNIST"
На каких картинках модель даёт ошибку. Ответ: => Я глянул одним глазом — это те картинки, где и человек не отличит просто потому что камера не работала. Возможно там есть адекватные изображения, на которых модель даёт ошибку, но это требует более вдумчивого анализа.
Где взять код, от всего вышеописанного? Ответ => https://github.com/ternaus/spb_bridges
Будет ли модель работать на других мостах? Ответ => не исключено, но кто его знает, надо пробовать.
А если бы задача стояла так: По изображениям моста Александра Невского создать модель для предсказания разведения Литейного моста, вы бы действовали так же? Ответ => Нет. У них различная система подъёма, так что там надо было смотреть на данные, пробовать и думать. Вопрос про правильной cross validation стоял бы очень остро. В общем это была бы интересная задача.
А если не обрезать изображение, так чтобы остался только мост, то задача стала бы сильно сложнее? Ответ => Стала бы, но не сильно.
А что если делать классификацию не на два класса (сведён/разведён), а на три (сведён/разведён/в движении)? Ответ => Если классифицировать на три класса, то получим оценку принадлежности к одному из трёх классов. Но надо менять несколько строк в файле, который делит данные на части, и одну в определении модели. => Домашнее задание для энтузиастов.
Пример сложной задачи, на которой надо мозг сломать, чтобы заставить модель хорошо работать => Ответ: Вот прямо сейчас я закончу текст, причешу github c кодом. и начну думать о сегментации нервов на изображениях.
Где взять сами картинки с мостами? Ответ: => Это к darkk
- Сколько нужно нейронов, чтобы узнать, разведён ли мост Александра Невского? Ответ: => И один нейрон, то есть логистическая регрессия выдаст замечательный результат.
Послесловие.
Это действительно очень простая задача для нейронных сетей на данном этапе развития этого направления в машинном обучении. Причём тут даже и не нейронные сети, а и более простые алгоритмы будут работать на ура. Премущество нейронных сетей в том, что они работают в режиме автоматического извлечения признаков, при наличии большого количества шума, и на некоторых типах данных, например, при работе с изображениями выдают точность на уровне State Of The Art. И данным текстом с приложенным кодом я попытался развеять мнение, что работать с нейронными сетями очень сложно. Нет это не так. Работать с нейронными сетями так чтобы они показывали хорошую точность на сложных задачах — это сложно, но очень многие задачи к этой категории не относятся и порог вхождения в эту область не такой высокий, как может показаться после прочтения новостей на популярных ресурсах.
