
Наш сервис активно развивается и растёт. Растёт число новых функций, растёт наша команда, растёт посещаемость. В общем, всё растёт и это хорошо. :)
Обо всём, что происходит с Яндекс.Картами, мы хотим рассказывать более подробно, регулярно и интересно, поэтому мы запускаем официальный блог сервиса Яндекс.Карты.
Яндекс.Карты сегодня — крупный картографический русскоязычный сервис, объединяющий целую линейку полезных для пользователей интернета приложений:
Обо всём этом и не только вы сможете читать в нашем блоге.
Кроме наших новостей мы будем рассказывать более подробно и о тех инструментах, что уже есть в Яндекс.Картах, а иногда будем писать обзоры о картах в целом — это наверняка тоже будет интересно.
Где можно нас читать?
Во-первых, в блоге Яндекс.Карт в Я.ру (добавляйте нас в «Друзья») и RSS-трансляции, а наиболее заметные новости мы продолжим писать и здесь — в корпоративном блоге.
Во-вторых, анонсы новых постингов можно читать в Twitter-аккаунте @yandexmaps
Кроме этого, напомним, что узнавать про Яндекс.Карты можно еще в Клубе пользователей мобильных Яндекс.Карт, клубе разработчиков API Яндекс.Карт и блоге Аналитического центра Яндекс.Пробок.
Обо всём, что происходит с Яндекс.Картами, мы хотим рассказывать более подробно, регулярно и интересно, поэтому мы запускаем официальный блог сервиса Яндекс.Карты.
Яндекс.Карты сегодня — крупный картографический русскоязычный сервис, объединяющий целую линейку полезных для пользователей интернета приложений:
- в первую очередь сам веб-сервис Яндекс.Карты (maps.yandex.ru) — это не только поиск по карте и организациям, но и множество различных полезных функций
- мобильные Яндекс.Карты — как приложение, так и сайт для мобильных браузеров
- интерактивные карты метро, а так же и мобильное приложение Яндекс.Метро
- API Яндекс.Карт — инструментарий для публикации Яндекс.Карт на сайтах или блогах
Обо всём этом и не только вы сможете читать в нашем блоге.
Кроме наших новостей мы будем рассказывать более подробно и о тех инструментах, что уже есть в Яндекс.Картах, а иногда будем писать обзоры о картах в целом — это наверняка тоже будет интересно.
Где можно нас читать?
Во-первых, в блоге Яндекс.Карт в Я.ру (добавляйте нас в «Друзья») и RSS-трансляции, а наиболее заметные новости мы продолжим писать и здесь — в корпоративном блоге.
Во-вторых, анонсы новых постингов можно читать в Twitter-аккаунте @yandexmaps
Кроме этого, напомним, что узнавать про Яндекс.Карты можно еще в Клубе пользователей мобильных Яндекс.Карт, клубе разработчиков API Яндекс.Карт и блоге Аналитического центра Яндекс.Пробок.

 Бесплатное распространение продукта всегда считалось хорошей маркетинговой идеей. Даже самый наивный потребитель в состоянии оценить возможность заполучить что-то задаром. Слово «бесплатно» стало заклинанием для бизнес-гуру, которые призывают веб-стартапы добиваться быстрого роста, снижая цену большинства своих услуг до нуля.
Бесплатное распространение продукта всегда считалось хорошей маркетинговой идеей. Даже самый наивный потребитель в состоянии оценить возможность заполучить что-то задаром. Слово «бесплатно» стало заклинанием для бизнес-гуру, которые призывают веб-стартапы добиваться быстрого роста, снижая цену большинства своих услуг до нуля.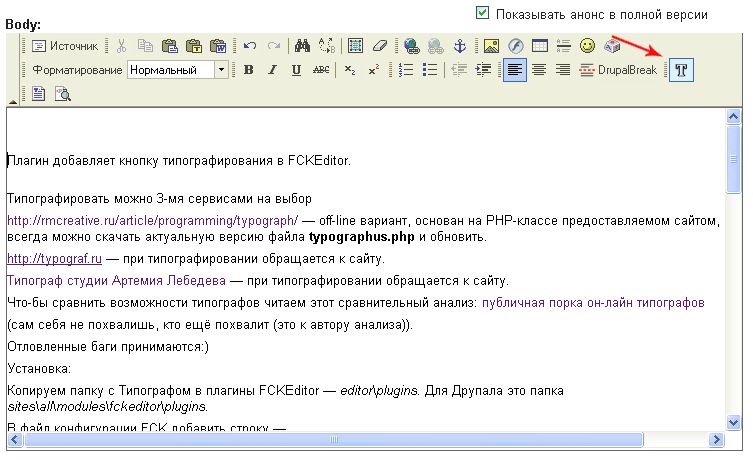
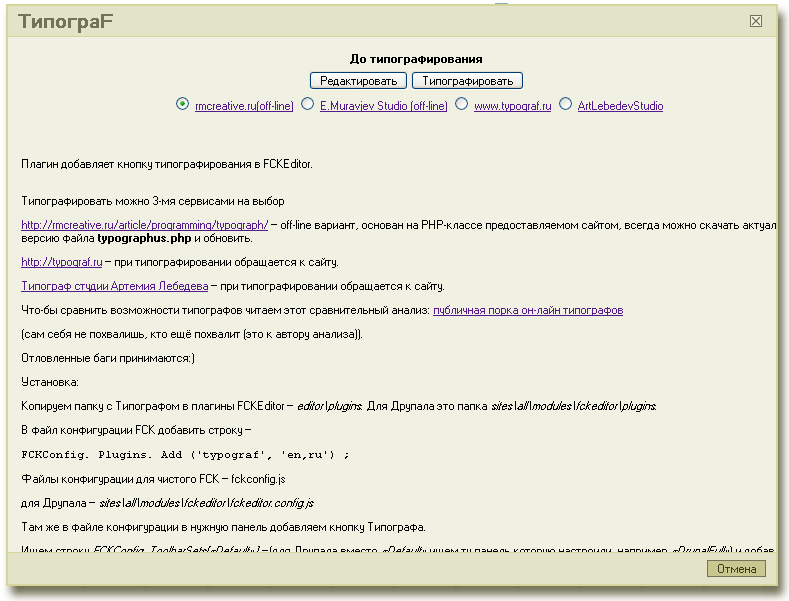

 Люди, критикуя модуль
Люди, критикуя модуль