
Сортировка в .NET
16 min
Задача сортировки — это классическая задача, которую должен знать любой программист. Именно поэтому эта статья посвящена данной теме — реализации сортировки на платформе .NET. Я хочу рассказать о том, как устроена сортировка массивов в .NET, поговорить о ее особенностях, реализации, а также провести небольшое сравнение с Java.
Итак, начнем с того, что первые версии .NET используют алгоритм быстрой сортировки по умолчанию. Поэтому небольшой экскурс в быструю сортировку:
Итак, начнем с того, что первые версии .NET используют алгоритм быстрой сортировки по умолчанию. Поэтому небольшой экскурс в быструю сортировку:

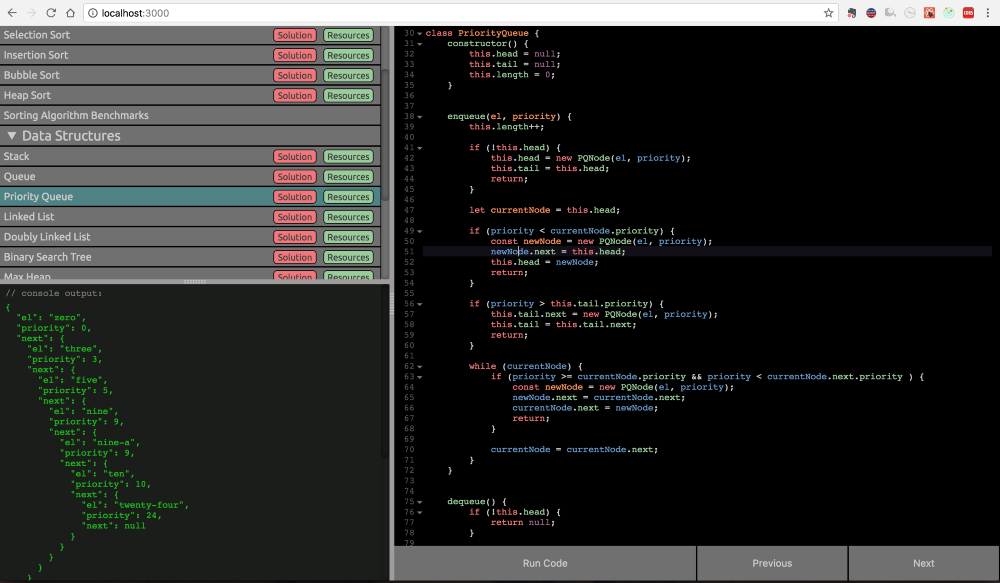

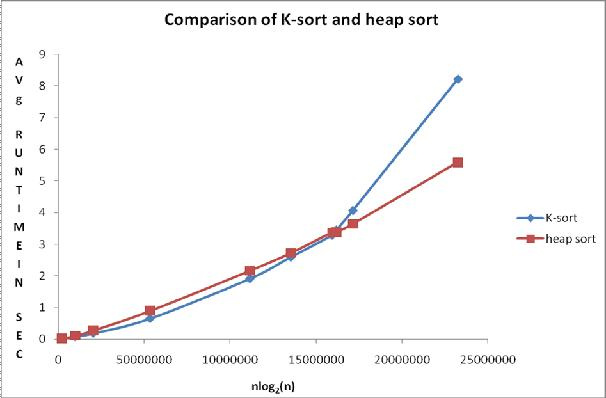
 Алгоритмы — это всего лишь пошаговые алгоритмы решения задач, и большинство таких задач уже были кем-то решены, протестированы и проверены. Можно, конечно, погрузиться в глубокую философию гениального Кнута, изучить многостраничные фолианты с доказательствами и обоснованиями, но хотите ли вы тратить на это свое время?
Алгоритмы — это всего лишь пошаговые алгоритмы решения задач, и большинство таких задач уже были кем-то решены, протестированы и проверены. Можно, конечно, погрузиться в глубокую философию гениального Кнута, изучить многостраничные фолианты с доказательствами и обоснованиями, но хотите ли вы тратить на это свое время? 

 Впервые на русском языке выходит одна из самых авторитетных книг по разработке и использованию алгоритмов. Алгоритмы — это основа программирования, определяющая, каким образом программное обеспечение будет использовать структуры данных.
Впервые на русском языке выходит одна из самых авторитетных книг по разработке и использованию алгоритмов. Алгоритмы — это основа программирования, определяющая, каким образом программное обеспечение будет использовать структуры данных.