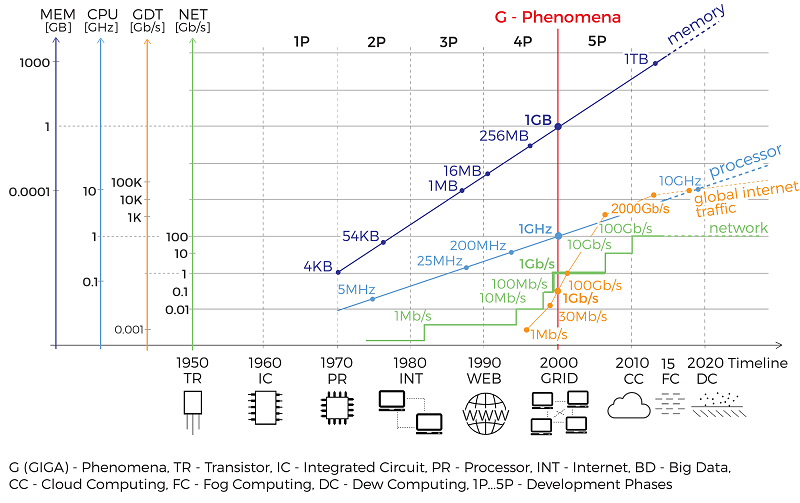
Мы занимаемся поставками электронных компонентов. Чтобы делать нашу работу хорошо, недостаточно просто уметь привозить и продавать электронные компоненты — ещё важно уметь демонстрировать их преимущества. Именно поэтому мы не только пишем обзорные статьи, но и создаем руководства по применению разных «железок» и разрабатываем небольшие демонстрационные проекты.

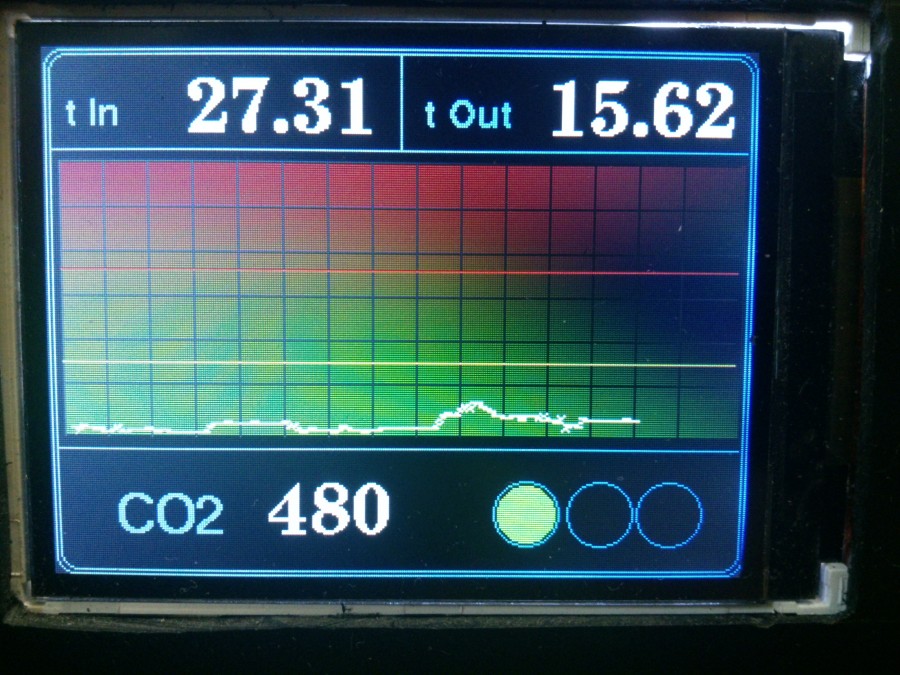
Об истории создания одного из таких демонстрационных проектов я и расскажу — буду последовательно описывать процесс создания прототипа устройства, оснащенного ёмкостным сенсорным экраном, и предназначенного для измерения относительной влажности и температуры.
Особенный интерес представляет подход к написанию встроенного ПО — софт полностью написан в онлайн IDE от mbed. То есть программа для микроконтроллера была создана на единственной вкладке гугл-хрома и одинаково работает на отладочных платах от разных производителей.
Содержание цикла публикаций:
Первая часть под катом.
Об истории создания одного из таких демонстрационных проектов я и расскажу — буду последовательно описывать процесс создания прототипа устройства, оснащенного ёмкостным сенсорным экраном, и предназначенного для измерения относительной влажности и температуры.
Особенный интерес представляет подход к написанию встроенного ПО — софт полностью написан в онлайн IDE от mbed. То есть программа для микроконтроллера была создана на единственной вкладке гугл-хрома и одинаково работает на отладочных платах от разных производителей.
Содержание цикла публикаций:
- [Часть 1] Обзор использованных программных и аппаратных решений.
- [Часть 2] Начало работы с графическим контроллером FT800. Использование готовых mbed-библиотек для периферийных устройств.
- [Часть 3] Подключение датчика HYT-271. Создание и публикация в mbed собственной библиотеки для периферийных устройств.
- [Часть 4] Разработка приложения: Структура программы, работа с сенсорным экраном.
- [Часть 5] Разработка приложения: Вывод изображений на дисплей, проблемы русификации.
- [Часть 6] Печать деталей корпуса
Первая часть под катом.

 В свое время на Хабре был опубликован цикл статей «Логика мышления». С тех пор прошло два года. За это время удалось сильно продвинуться вперед в понимании того, как работает мозг и получить интересные результаты моделирования. В новом цикле «Логика сознания» я опишу текущее состоянии наших исследований, ну а попутно попытаюсь рассказать о теориях и моделях интересных для тех, кто хочет разобраться в биологии естественного мозга и понять принципы построения искусственного интеллекта.
В свое время на Хабре был опубликован цикл статей «Логика мышления». С тех пор прошло два года. За это время удалось сильно продвинуться вперед в понимании того, как работает мозг и получить интересные результаты моделирования. В новом цикле «Логика сознания» я опишу текущее состоянии наших исследований, ну а попутно попытаюсь рассказать о теориях и моделях интересных для тех, кто хочет разобраться в биологии естественного мозга и понять принципы построения искусственного интеллекта.