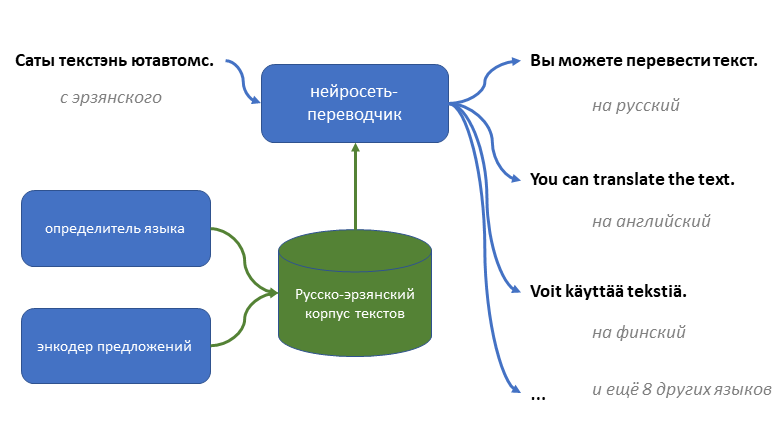
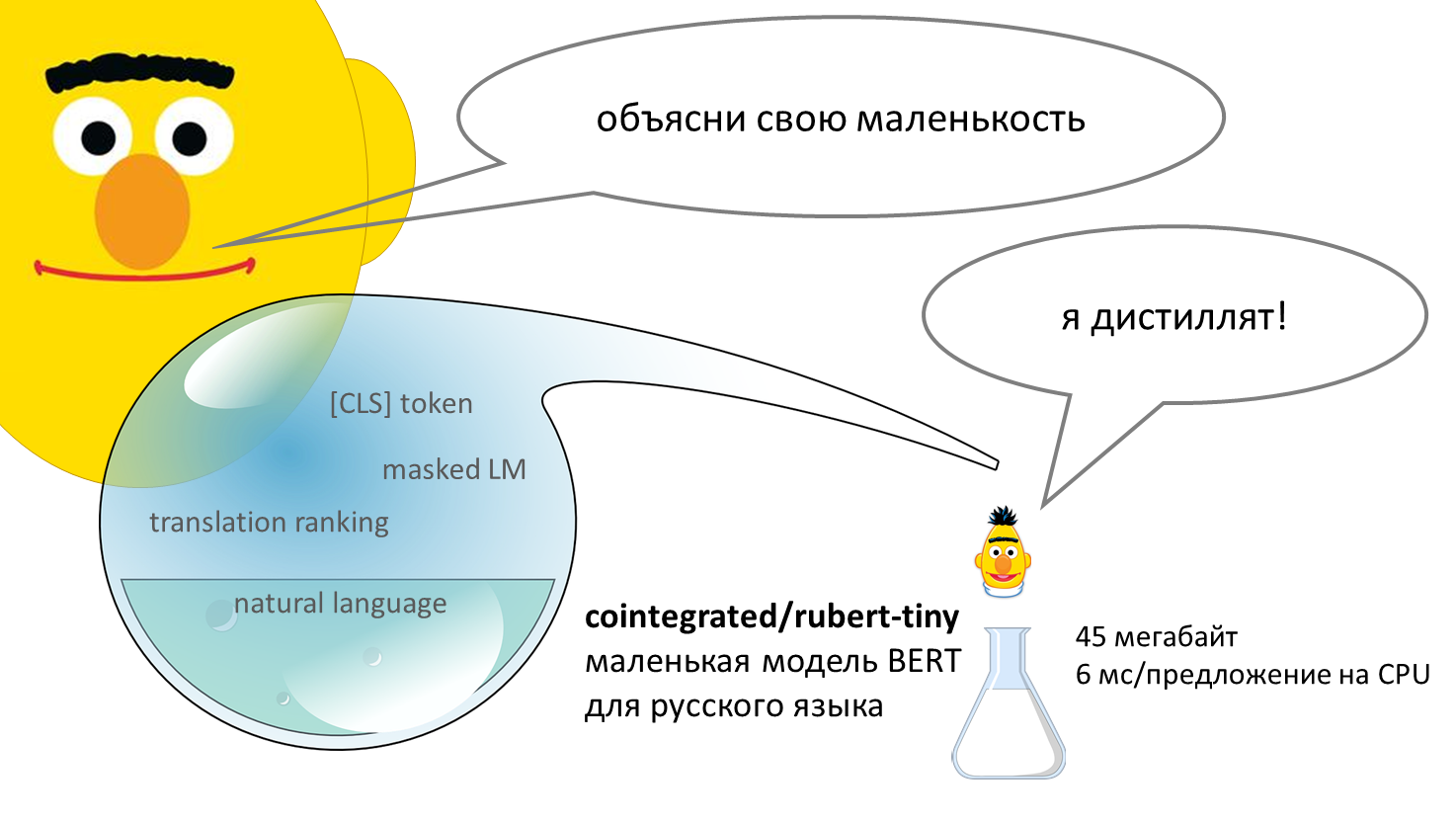
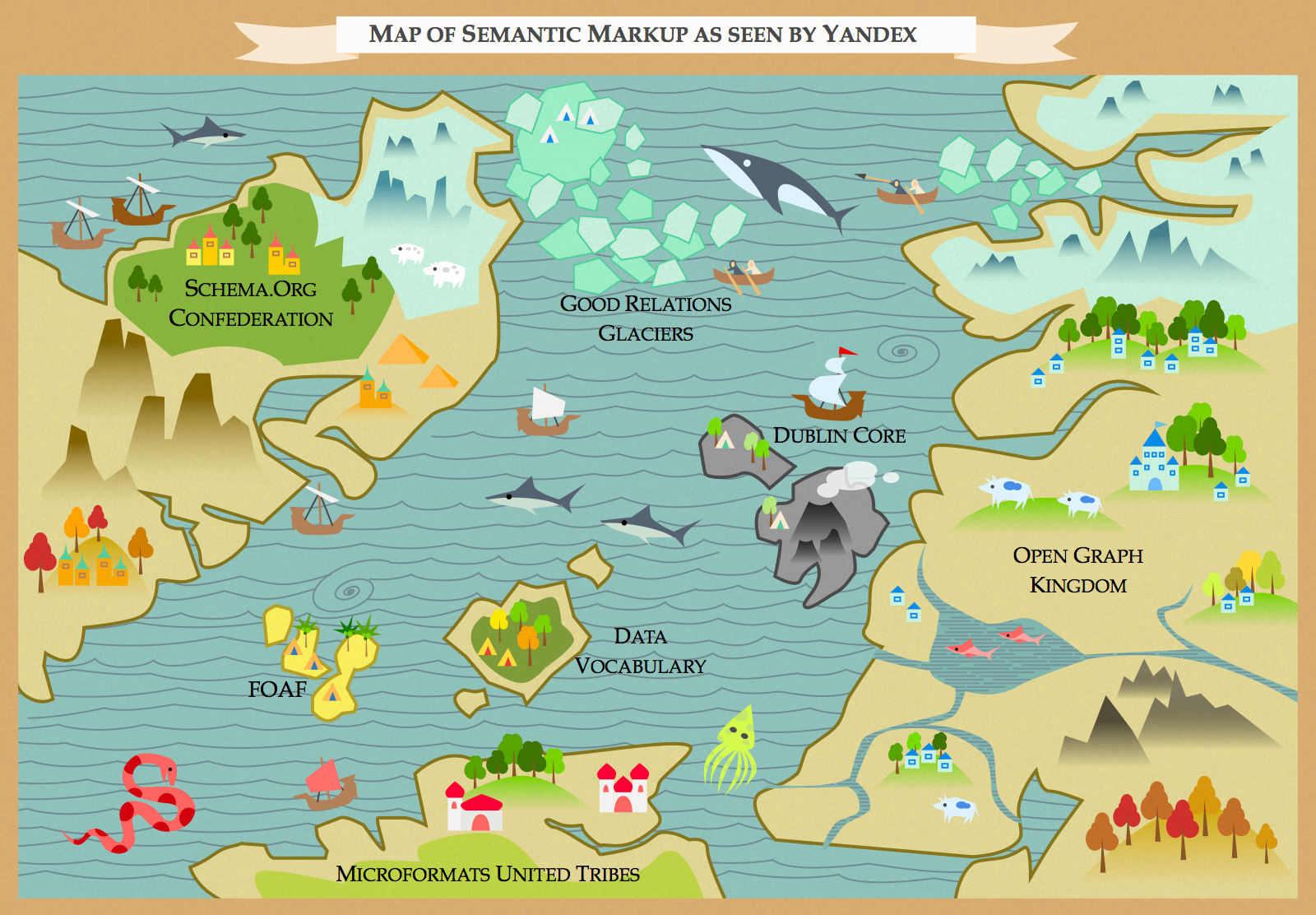
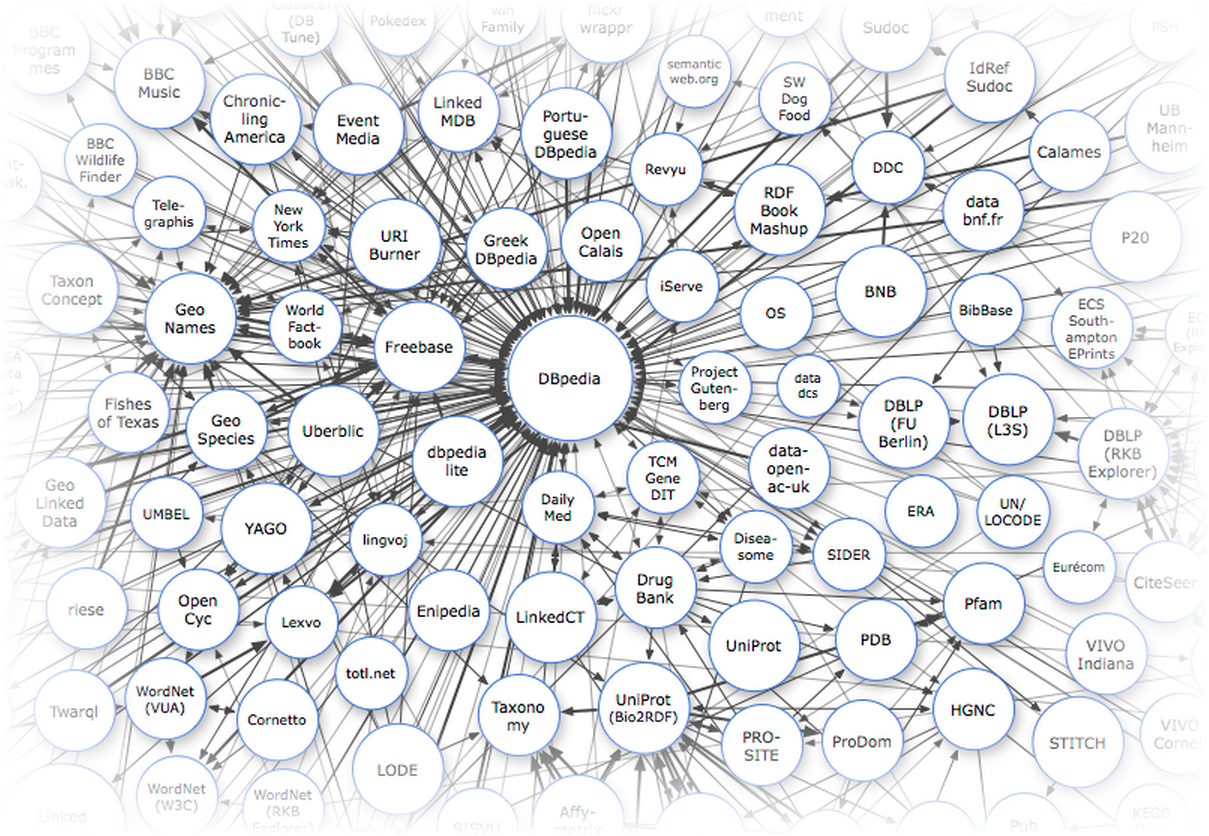
Если вы подозреваете, что «трамвай» — это глагол повелительного наклонения, или что «забор крови» — это нечто из фильмов ужасов, то вы точно понимаете, где в тестах по русскому языку есть обширное поле для лютого троллинга.
Сначала я вообще считал, что «Русский медвежонок» — это отдельное произведение искусства, созданное, чтобы с иррациональным юмором показать расширенные возможности языка. А потом
allex познакомил меня с создателями сего шедевра, и выяснилось, что это вообще-то ужасно серьёзное дело, которым заняты математики и лингвисты. Предельно адекватные, насколько это вообще возможно для математиков и лингвистов.
Значит, сейчас «Медвежонок» — это самый массовый конкурс по русскому языку, подозрительно напоминающий олимпиаду всем, кроме формы. Формально он — игра. Предприятие это сугубо коммерческое, участие стоит 85 рублей (до 100 рублей на Дальнем Востоке). Участие добровольное, в качестве приза предполагается нечто символическое — это тоже осознанно, чтобы не было тех, кто играет на мамону. Все вопросы предполагают на входе некоторый общий уровень развития человека, рождённого на Земле в России. То есть это нечто из базовой школьной программы, общечеловеческие бытовые знания и базовый же кругозор. Задач на чистое академическое знание нет. Задач на зубрёжку нет. Даже если вам кажется, что есть. Задачи довольно хорошо тестируются на живых людях до раскатки на конечных пользователей.
В общем, я хочу показать, что бывает, когда математики добираются до русского языка. И познакомить вас с двумя прекрасными людьми — кандидатом физико-математических наук Игорем Рубановым и кандидатом филологических наук Еленой Муравенко.
Первое, что меня без меры порадовало — что в методологии «пять вариантов ответов» сразу подразумевается, что все эти варианты создаются так, чтобы максимально запутать отвечающего и, фактически, внести новый уровень сложности в задачу. Сейчас покажу пару примеров.