Мультиклеты: влияние реконфигурации на бенчмарки и задачи майнинга
В 2014 году была опубликована статья о первом мультиклеточном процессоре с реконфигурацией. За прошедшее время накопился опыт ее использования и понимание, где она может применена с максимальным эффектом.
Как известно, физические и технологические ограничения, объективно существующие при проектировании и изготовлении новых микропроцессоров, постепенно перешли из теоретической в практическую плоскость. Планарные транзисторы перестали уменьшаться в 2D размерах и стали переходить в 3D измерение. Расстояния на чипе стали ограничивать тактовую частоту, а размеры чипа привели к тому, что на пластине годным стало считаться то, что хоть как-то работает. При этом, микропроцессоры стали напоминать ламповые компьютеры 60-х годов прошлого века, на корпусе которых можно было жарить яичницу.
Несмотря на все эти проблемы, рыночное требование «все выше и выше» в части производительности микропроцессоров никто не отменяет и худо-бедно оно выполняется. Для этого используется одна волшебная пилюля – параллелизм. NVIDIA увеличивает количество CUDA-блоков, число которых в ее микропроцессорах с архитектурой GA-102 превышает 10000 шт. Intel и AMD увеличивают количество ядер и количество потоков в ядре. Так, общее количество ядер у десктопных процессоров Intel и AMD нового поколения доходит до 16 шт, а потоков до 32 шт. У серверных процессоров (AMD серии EPYC и Intel серии Xeon) это количество доходит до 64 ядер и 128 потоков. Причем все потоки как у Intel, так и у AMD – суперскалярные.
Все это, конечно, замечательно, но спектр задач, решаемых всеми этими и другими процессорами необычайно широк. Он включает и последовательные алгоритмы, которым в принципе не нужен параллелизм. Есть задачи, где параллелизм присутствует только на отдельных этапах, причем он может быть весьма различным, допуская распараллеливание на две-три или на десятки веток. А некоторые задачи, например, обработки изображений, ИИ или матричные вычисления могут распараллеливаться на тысячи или десятки тысяч веток. И все это разнообразие задач мы решаем используя фактически три инструмента – это простейшие микроконтроллеры, либо многоядерные и многопоточные суперскалярные процессоры (Intel, AMD, ARM, RISC-V), либо SIMD процессоры (NVIDIA, графические процессоры AMD). Понятно, что есть задачи, для решения которых эти инструменты подходят идеально, но есть и задачи для которых они либо явно недостаточны, либо явно избыточны.
Как уже говорилось, развитие микропроцессоров заточено на повышение производительности. В отдельных случаях, на экономию энергопотребления, но как правило, этот параметр идет вторым, даже в задачах цифровой обработки сигналов, за исключением, пожалуй мобильных медицинских приборов, типа слуховых аппаратов. Соответственно, большинство бенчмарков, в первую очередь, оценивают производительность. Насколько быстро рисуется картинка на дисплее, насколько быстро перемножаются матрицы или как быстро осуществляется поиск в базе данных. Это, безусловно, важно. Но почему-то мало кто задается вопросом, насколько это оптимально. Может быть, лучше увеличить время решения на 10% и при этом уменьшить энергопотребление на 50%?
Пока ресурсов достаточно, на энергопотребление можно не обращать внимания, но первый звоночек уже прозвенел. Ряд стран, например, стал запрещать использование майнинговых ферм из-за большого потребления электроэнергии.
Инструменты
Снижение энергопотребления в настоящее время обеспечивается целым рядом разнообразных средств. К их числу относятся технологические (использование специальных энергоэффективных библиотек элементов), схемотехнические (управление питанием и тактовой частотой), а также архитектурные средства. Первые два комплекса средств имеют узкоспециализированный характер. Они решают только задачу снижения энергопотребления. Комплекс архитектурных средств обеспечивает не только снижение энергопотребления, но и, одновременно, повышение производительности процессоров. Можно сказать, что снижение энергопотребления обеспечивается повышением производительности.
Наиболее существенное значение имеют следующие решения:
Объем регистровой памяти.
Использование методов внеочередного исполнения команд.
Методы модификации адресов.
Отказ от глобальной конвейеризации.
Подробнее об этих решениях
Объем регистровой памяти. От нее в значительной мере зависит количество обращений к оперативной памяти для хранения промежуточных результатов и, соответственно, энергозатраты на организацию информационной связи между командами. Известно, что затраты на хранение промежуточных результатов в регистрах меньше, чем в оперативной памяти. Но, наибольший эффект достигается при непосредственной рассылке результатов выполнения команд – командам потребителям этого результата, как в мультиклеточных процессорах. В этом случае практически полностью исчезают накладные затраты связанные с организацией хранения и доступа к промежуточным результатам.
Использование методов внеочередного исполнения команд в 1,7-2 раза повышает производительность процессорных устройств за счет устранения энергозатратных простоев, что практически эквивалентно снижению энергозатрат на выполнение алгоритма в такой же пропорции. При этом повышение производительности может использоваться двояко. Либо для выполнения дополнительного объема задач, либо для экономии энергии, переходя в «спящий» режим после выполнения задачи.
Методы модификации адресов. Развитые методы, при организации циклических вычислений, позволяют сократить количество команд на организацию циклов и, соответственно, уменьшить общие энергозатраты.
Отказ от глобальной конвейеризации. Известно, что с увеличением длины конвейера увеличивается «стоимость» его загрузки и увеличиваются потери производительности при его приостановке, т.н. «пузыри». Альтернативным и более энергоэффективным решением является организация работы блоков процессорного устройства на принципах системы массового обслуживания, используемых в мультиклеточных процессорах, когда тот или иной блок процессора работает тогда и только тогда, когда есть необходимость в его функциях.
Все эти методы используются и в мультиклеточном процессоре. Но, у мультиклеточного процессора есть еще одна опция, которая присуща ему и только ему. Это реконфигурация. Т.е. возможность динамического перераспределения ресурсов процессора в процессе работы между решаемыми задачами (подробно см. ссылку в начале статьи). Это, если отталкиваться от известного, суперскалярный процессор, который одновременно выбирает и обрабатывает 8 команд, вдруг, по команде программиста, превратился бы в 8 независимых скалярных процессора или в четыре простеньких суперскаляра, каждый из которых обрабатывает 2 команды, или в два суперскаляра с параллельной обработкой 4-х команд каждый. И не просто превратился, а продолжил бы выполнять текущие задачи на измененной конфигурации. Ни один существующий суперскаляр этого не может в принципе. Вне зависимости от того какая у него система команд: х86, ARM или RISC-V.
Реконфигурация
Есть целый ряд понятий, которые по сути отражают одно и тоже явление. Мы говорим «командная работа», «оркестр без дирижера», «децентрализованная система» и т.п., когда группа исполнителей или исполнительных устройств согласованно выполняют одну общую работу и при этом не имеют явного централизованного управления. Понятно, что эта работа поручена всей группе, но при ее исполнении, никто не организует исполнителей и не распределяет работу между ними. Группа – это единый организм, у каждого участника которого свое позиционирование, своя роль.
Командная работа широко распространена в биосистемах как на уровне сообществ – муравейники, ульи, так и внутри живых организмов – внутренние органы, мышцы – это все примеры командной работы.
Известно, что клетку в живом организме можно рассматривать как некоторое процессорное устройство и наоборот. Аналогии с работой клеток сопровождают компьютерную индустрию с момента появления первых процессоров, точнее с момента публикации Дж. фон. Нейманом документа, который можно назвать техническим заданием на разработку первого компьютера EDVAC. Появление мультиклеточной архитектуры просто реанимировало этот подход на новом уровне и позволило создавать из клеток многоклеточные устройства – мультиклетки, аналогом которых в живой природе является многоклеточный организм.
Нельзя просто взять и объединить в единое целое несколько фон-неймановских (vN) процессоров. Их совместную работу кто-то должен организовать. Либо на программном, либо на аппаратном уровне. Иначе говоря, программа, которая выполняется на одном vN процессоре не может быть совместно выполнена несколькими процессорами без ее полной переработки. Более того, программа для совместной работы двух vN процессоров будет отличаться от программ доработанных для другого количества vN процессоров. Восемь скалярных процессоров – это вычислительная система и они никогда не будут параллельным суперскаляром.
Но это не распространяется на мультиклеточную архитектуру. Программа мультиклеточного процессора абсолютно независима от среды исполнения и может быть выполнена на любом количестве клеток без какой-либо переработки.
Клетка представляет собой простейшее процессорное устройство:
Работает клетка следующим образом:
Блоком выборки (F) выбирается очередное командное слово.
Выбранное командное слово декодируется (D) и декодированная команда записывается в буферную память. При декодировании команде присваивается индивидуальный номер (тэг) и формируется запрос к массиву результатов на получение требуемых ей результатов. Если результаты есть, то они как операнды передаются вместе с командой в буфер. Процесс декодирования может быть приостановлен, если, например, еще не получен результат ранее выбранной команды с тэгом, который должен быть присвоен декодируемой команде.
В буферной памяти (Buffer) команда находится до получения всех, необходимых ей операндов. Для чего буферная память осуществляет просмотр всех поступающих результатов и отбирает необходимые. Готовая к исполнению команда передается в исполнительное устройство.
Исполнительное устройство (Execution Unit), включает целочисленное АЛУ и АЛУ с плавающей точкой.
Результат выполнения команд исполнительное устройство передает в коммутационное среду (Communication Environment), обеспечивающую рассылку полученных результатов.
В отличие от суперскалярных процессоров восстановление последовательности состояния памяти или регистров не требуется, так как команды в программе упорядочены только частично и только по данным. Т.е. очередность исполнения команд не задана.
Мультиклетка – это мультиклеточный процессор состоящий из нескольких клеток, исполняющих общую программу:
При объединении каждая клетка получает свой логический номер (это ее роль в команде). Память программ всех клеток объединяется в один блок со сквозной адресацией и сохранением независимого доступа. Все клетки синхронно выбирают очередную команду. При этом клетка с номером i выбирает команду с адресом A+i, где А – адрес команды, которую выбирает нулевая клетка.
Выбранные команды поступают на декодирование (D). Декодирование также осуществляется синхронно. Если у какой-то клетки декодирование задерживается, то она сообщает об этом остальным, чтобы все клетки приостановились.
Декодированные команды поступают в буфера и, с этого момента, выполнение команд клетками не синхронизируется. Каждая клетка формирует и исполняет команды – независимо.
Потоки результатов объединяются в один общий поток, который рассылается всем клеткам.
Таким образом, мультиклетка это не отдельная реализация, а параллельный процессор, собранный из отдельных клеток. На кристалле может быть реализовано несколько десятков и сотен мультиклеток. Каждая мультиклетка динамически в процессе вычислений может реконфигурироваться, например, 8-ми клеточная мультиклетка может использоваться как 8 отдельных клеток или как четыре 2-х клеточные мультиклетки или как две 4-х клеточные или одна 8-ми клеточная. Эта качественная возможность присуща только мультиклеточной архитектуре, так как она использует представление алгоритма в виде зависимости между данными, и принципиально недостижима для vN архитектур, которые используют описание алгоритмов как последовательности операций.
Понятие «мультиклетка», возникло при переходе на 28 нм техпроцесс. Если ранее мы проводили изучение реконфигурируемого мультиклеточного процессора, состоящего из клеток (в частности, 4 клеточный Multiclet R1, реализованный на 180 нм техпроцессе), то дальнейшее развитие архитектуры, переход к современным техпроцессам 28 нм и меньше, позволило увеличить число клеток до 64 и 256. Это естественным образом привело к появлению нового иерархического уровня, к новой концепции - мультиклетке, состоящей из 4 клеток. Фактически, микропроцессор Multiclet R1 стал апробацией в кремнии такой мультиклетки.
Оптимальность для примере майнинга
Как уже отмечалось, энергопотребление при майнинге – ключевой параметр. Если исключить майнинговые фермы, использующий ASIC решения, то сейчас основной инструмент для майнинга – это разнообразные видеоплаты. Все они, по сути, являются SIMD процессорами и выгодно отличаются от ASIC решений универсализмом. А вот насколько они оптимальны для майнинга – рассмотрим на конкретном примере, а именно при использовании их для майнинга Ethereum.
Предположим нам нужно спроектировать процессор, обеспечивающий хэшрейт на уровне 35 Mh/s. Исходя из алгоритма Ethash, используемого Ethereum, пропускная способность канала памяти, обеспечивающая этот хэшрейт должна быть: 35 Mh/s × 128 B × 64 B ≈ 286,7 GB/s. Это решается использованием памяти GDDR6X шириной 128 бит. Вопрос: а какова должна быть производительность процессора? При заданном хэшрейте время на вычисление одного хэша должно быть: 1 000 000 000 нс ÷ 35 000 000 H ≈ 28 нс.
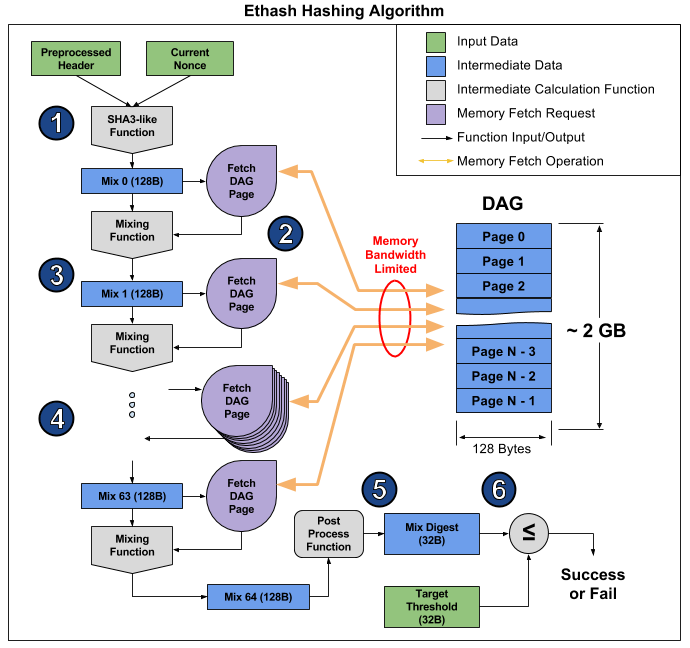{kind=link}
Базовая (универсальная) система команд мультиклеточного процессора, по составу операций, мало чем отличается от системы команд традиционных процессоров. В текущей реализации Ethash для мультиклеточного процессора, количество команд, выполняемых при расчете одного хэша с использованием только базовых команд, составляет 11038 команд. По замерам при помощи симуляции процессора в ModelSim, одна клетка выполняет их за 13520 тактов. Двухклеточный процессор – за 10692 такта, а четырехклеточный за 8879 тактов. Результаты показывают, что особенности выполняемого алгоритма таковы, что наиболее эффективно выполнять его на одноклеточных процессорах. Т.е. мультиклетки процессора должны быть реконфигурированы и использованы как одноклеточные процессоры. Аналогичную картину мы наблюдаем и при решении других задач:
| 1 клетка | 2 клетки | 4 клетки |
Множество Мандельброта 32х32, такты | 671750 | 494926 | 412117 |
Бинарные деревья глубины 6, такты | 1866847 | 1277282 | 1166775 |
8 ферзей, такты | 3666622 | 2900814 | 2119435 |
Dhrystone, такты | 1180 | 818 | 730 |
Ethereum, такты* | 13520 | 10692 | 8879 |
*без аппаратной поддержки алгоритма
Относительное изменение времени выполнения этих задач представлено на графике:
Как видно на графике, ни в одном случае мы, кратно увеличив количество клеток решающих задачу, не получили соответствующего кратного прироста производительности. Понятно, что есть задачи, где крайне важна скорость решения, но в большинстве приложений это не так. Однако, так как реконфигурацию можно провести в любой момент, можно, в зависимости от требований и поставленной задачи, выбирать нужное количество клеток для достижения желаемых результатов.
Но, вернемся к Ethereum. Если мы используем процессор с тактовой частоте 2 GHz, то в первом случае для обеспечения хэшрейта нам потребуется 242 клетки. Во втором случае – 382, а в третьем – 632 клетки. Однако реализация аппаратной поддержки вычисления SHA-3 позволяет одноклеточному процессору выполнить расчет хэша за 3217 тактов, что занимает 1609 нс при частоте 2 ГГц. Соответственно, для достижения заявленного хэшрейта нам потребуется иметь на борту не менее 1609 нс ÷ 28 нс/хэш ≈ 57 клеток (в проекте – 64 клетки).
Теперь рассмотрим насколько оптимально используются ресурсы видеоплат. Видеокарта RTX 3090 имеет хэшрейт Ethereum 120 Mh/s. Хэшрейт Ravencoin (KAWPOW) равен 58 Mh/s. Процессор данной видеокарты GA-102 имеет на борту 10572 CUDA-ядра.
Хэшрейт Ethereum полностью определяется производительностью памяти. При вычислении KAWPOW, объем читаемых данных из памяти в два раза больше (256 байт на 1 хэш против 128 байт в Ethash) и, следовательно, можно было бы ожидать, что хэшрейт Ravencoin составит порядка 62 Mh/s, но он меньше. Так как потери на регенерацию памяти уже учтены, то тогда можно предположить, что некоторое снижение хэшрейта скорее всего связано с объемом вычислений. Т.е. видеокарта RTX 3090 при расчете KAWPOW загружена более, чем полностью. Сравнительная оценка вычислительной сложности показывает, что объем вычислений KAWPOW в ~14 раз больше, чем объем вычислений Ethereum. Из этого можно примерно рассчитать, насколько CUDA ядра в видеокарте RTX 3090 загружены при вычислении Ethereum: (учитывая, что KAWPOW считывает в 2 раза больше данных на 1 хэш) 2 × 100% ÷ 14 ≈ 14%. Но, потребляет она при этом свои 300 W.
В рассмотренном проекте используется один мультиклеточный процессор. Устройство с ним способно выдавать 35 Mh/s при энергопотреблении 12 W, что в расчете на W дает 2,91 Mh/s/W. При сравнении c показателем 0,35 Mh/s/W у RTX 3090, мультиклеточное устройство получается почти в 10 раз более энергоэффективным.
MultiClet | NVIDIA RTX 3090 | AMD RX 6900XT | |
Хэшрейт Ethereum, Mh/s | 35 | 120 | 64 |
TDP, W | 12 | 300 | 160 |
Хэшрейт на W, Mh/s/W | 2,91 | 0,4 | 0,4 |
Окупаемость | 2 мес | 11 мес | 11 мес |
Рассмотренный пример – это иллюстрация того, насколько эффективен может быть универсальный инструмент, если он не только подобран под задачу, но и имеет высокие эксплуатационные характеристики.
Эти характеристики выгодно отличают также мультиклеточный процессор от суперскаляров. Как известно у абсолютно всех суперскалярных процессоров есть одна особенность – это огромный объем аппаратной поддержки супескалярности, который в разы превышает объем собственно исполнительных блоков. Анализ информационной зависимости между командами, спекулятивное выполнение и предсказание переходов, восстановление последовательности изменений регистров и памяти – это все энергопотребление и снижение производительности и все это не нужно мультиклеточному процессору для эффективной работы. Как результат, уменьшение размеров кристалла и, соответственно, увеличение быстродействия, а также уменьшение энергопотребления мультиклеточных процессоров.
Заключение
Развитие мультиклеточной архитектуры показывает, что, несмотря на ее универсальность, лучшее применение в настоящее время будет получено в задачах майнинга альткоинов. Данное направление развития не требует отдельного ПО (кроме уже имеющегося C компилятора LLVM 13.0.0) для совместимости с множеством имеющихся пакетов программ. Следующими по значимости применениями для мультиклеточной архитектуры станут производство серверных ускорителей и решение задач машинного обучения, что подтвердили технические заключения специалистов Samsung и Huawei по итогам ряда презентаций.
Проведенный сравнительный анализ удельной эффективности архитектур показал, что в задачах, требующих распараллеливания, процессор, выполненный на мультиклеточной архитектуре по технологии 28 нм, соответствует суперскалярным процессорам с традиционной системой команд типа х86, АРМ, RISC-V, выполненным по технологии 12 нм, что позволяет достичь существенной экономии при строительстве фабрик.