
Хабр Курсы для всех
РЕКЛАМА
Практикум, Хекслет, SkyPro, авторские курсы — собрали всех и попросили скидки. Осталось выбрать!

Сетевая карта Intel X520 DA2 предназначена для систем виртуализации поэтому в ней два порта.
Я решил купить три карточки и три кабеля, чтобы соединить три сервера в 10 гигабитное кольцо, у серверов разные операционные системы, на данный момент я потестил только скорость между freenas и windows? получил 300 мегабайт между ними, на виндовсе собран 5-ый софтовый raid из 5 винчестеров, на фринасе zfs raidz2 из 20 винтов. Думаю что все упирается в виндовый raid позже проведу тесты с линуксом и думаю смогу получить почти 10 гигабит скорости между хранилищами.
Вопросы, пожелания, предложения?
Все кому не жалко скиньте денег на еду:
Яндекс деньги: 41001350134938
wmr: R216907812321
wmz: Z115984864021
Приму в дар хороший фотоаппарат, высокотехнологичное железо для обзоров, интересные штуки(предлагайте сами), тему для обзора или освещения.
Не жалеем карму и плюсы.
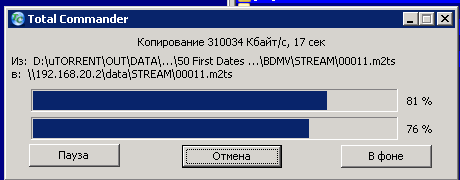
По просьбе в комментариях прикладываю скрин копирования с тотала(скорость будет выше в тестах на линуксе).
Собственно, в этом и состоит принцип саморегуляции Хабра.
Вы знаете, я свои N голосов в день использую каждый день
Автор — первый, кому я поставил минус за все время пребывания на Хабре.
И я считаю, что сделал правильно.
Потому что лично я ценю Хабрахабр за качественные статьи.
То есть каждый должен писать топик и все остальные должны его оценивать, да? А как же коллективное творчество?
просьба тухлые яйца бросать сразу мне в хабрапочту.Из вашего топика…
#!/bin/sh
#
# irq2smp -- distribute hardware interrupts from Ethernet devices by CPU cores.
#
# Should be called from /etc/rc.local.
#
/bin/echo 1 > /proc/irq/`cat /proc/interrupts | grep 'eth0-rx-0' | awk -F \: '{printf "%i", $1}'`/smp_affinity
/bin/echo 2 > /proc/irq/`cat /proc/interrupts | grep 'eth0-rx-1' | awk -F \: '{printf "%i", $1}'`/smp_affinity
/bin/echo 4 > /proc/irq/`cat /proc/interrupts | grep 'eth0-rx-2' | awk -F \: '{printf "%i", $1}'`/smp_affinity
/bin/echo 8 > /proc/irq/`cat /proc/interrupts | grep 'eth0-rx-3' | awk -F \: '{printf "%i", $1}'`/smp_affinity
/bin/echo 1 > /proc/irq/`cat /proc/interrupts | grep 'eth0-tx-0' | awk -F \: '{printf "%i", $1}'`/smp_affinity
/bin/echo 2 > /proc/irq/`cat /proc/interrupts | grep 'eth0-tx-1' | awk -F \: '{printf "%i", $1}'`/smp_affinity
/bin/echo 4 > /proc/irq/`cat /proc/interrupts | grep 'eth0-tx-2' | awk -F \: '{printf "%i", $1}'`/smp_affinity
/bin/echo 8 > /proc/irq/`cat /proc/interrupts | grep 'eth0-tx-3' | awk -F \: '{printf "%i", $1}'`/smp_affinity
/bin/echo 1 > /proc/irq/`cat /proc/interrupts | grep 'eth1-rx-0' | awk -F \: '{printf "%i", $1}'`/smp_affinity
/bin/echo 2 > /proc/irq/`cat /proc/interrupts | grep 'eth1-rx-1' | awk -F \: '{printf "%i", $1}'`/smp_affinity
/bin/echo 4 > /proc/irq/`cat /proc/interrupts | grep 'eth1-rx-2' | awk -F \: '{printf "%i", $1}'`/smp_affinity
/bin/echo 8 > /proc/irq/`cat /proc/interrupts | grep 'eth1-rx-3' | awk -F \: '{printf "%i", $1}'`/smp_affinity
/bin/echo 1 > /proc/irq/`cat /proc/interrupts | grep 'eth1-tx-0' | awk -F \: '{printf "%i", $1}'`/smp_affinity
/bin/echo 2 > /proc/irq/`cat /proc/interrupts | grep 'eth1-tx-1' | awk -F \: '{printf "%i", $1}'`/smp_affinity
/bin/echo 4 > /proc/irq/`cat /proc/interrupts | grep 'eth1-tx-2' | awk -F \: '{printf "%i", $1}'`/smp_affinity
/bin/echo 8 > /proc/irq/`cat /proc/interrupts | grep 'eth1-tx-3' | awk -F \: '{printf "%i", $1}'`/smp_affinity
hw.igb.rxd="4096"
hw.igb.txd="4096"
hw.igb.rx_process_limit="400"
net.isr.maxthreads=4net.route.netisr_maxqlen=512
net.isr.direct=0net.isr.maxthreads=4
net.isr.numthreads=4
net.isr.bindthreads=0Не раз читал, но там FreeBSD, а она не умеет разбрасывать именно по ядрам прерывания как в Linux
last pid: 88161; load averages: 1.10, 1.08, 1.07 up 358+05:03:51 17:51:33 205 processes: 7 running, 180 sleeping, 18 waiting CPU 0: 0.0% user, 0.0% nice, 24.4% system, 1.1% interrupt, 74.4% idle CPU 1: 0.0% user, 0.0% nice, 25.6% system, 1.1% interrupt, 73.3% idle CPU 2: 0.0% user, 0.0% nice, 28.2% system, 0.4% interrupt, 71.4% idle CPU 3: 0.0% user, 0.0% nice, 24.1% system, 0.4% interrupt, 75.6% idle Mem: 644M Active, 800M Inact, 463M Wired, 68M Cache, 199M Buf, 26M Free Swap: 8192M Total, 20K Used, 8192M Free PID USERNAME PRI NICE SIZE RES STATE C TIME CPU COMMAND 10 root 171 ki31 0K 8K RUN 3 7457.5 79.59% [idle: cpu3] 11 root 171 ki31 0K 8K RUN 2 7379.3 75.98% [idle: cpu2] 12 root 171 ki31 0K 8K CPU1 1 6679.1 73.19% [idle: cpu1] 13 root 171 ki31 0K 8K RUN 0 6126.0 72.17% [idle: cpu0] 25 root 43 - 0K 8K WAIT 1 1634.6 25.00% [em0_rx0_0] 16298 root 43 - 0K 8K WAIT 0 963.3H 24.37% [em0_rx0_1] 29 root 43 - 0K 8K CPU2 2 1478.4 24.17% [em1_rx0_0] 30 root 43 - 0K 8K RUN 3 1477.9 23.19% [em1_rx0_1] 15 root -32 - 0K 8K WAIT 0 162.0H 1.86% [swi4: clock] 27 root 16 - 0K 8K WAIT 3 88.9H 0.68% [swi16: em1_tx] 23 root 16 - 0K 8K WAIT 1 83.2H 0.68% [swi16: em0_tx] 37 root 8 - 0K 8K pftm 0 73.3H 0.49% [pfpurge]
device = 'Intel Corporation 82573E Gigabit Ethernet Controller (Copper) (82573E)'
device = 'Intel PRO/1000 PL Network Adaptor (82573L)'
em0: <Intel® PRO/1000 Network Connection 7.0.5.Yandex[$Revision: 1.36.2.18 $]> port 0x3000-0x301f mem 0xd0300000-0xd031ffff irq 16 at device 0.0 on pci13 em0: Using MSI interrupt em0: [FILTER] em0: Ethernet address: 00:30:48:64:e9:4a em1: <Intel® PRO/1000 Network Connection 7.0.5.Yandex[$Revision: 1.36.2.18 $]> port 0x4000-0x401f mem 0xd0400000-0xd041ffff irq 17 at device 0.0 on pci15 em1: Using MSI interrupt em1: [FILTER] em1: Ethernet address: 00:30:48:64:e9:4b
# Bind all kernel threads to CPU cores 0,1 sharing common L2-cache ps -axo pid,command | egrep '^ *[0-9]+ \[' | while read pid cmd; do cpuset -l 0,1 -p $pid; done # Bind em0 and em1 threads to different CPU cores ps -axo pid,command | egrep '^ *[0-9]+ \[' | grep em0 | while read pid cmd; do cpuset -l 0,1 -p $pid; done ps -axo pid,command | egrep '^ *[0-9]+ \[' | grep em1 | while read pid cmd; do cpuset -l 2,3 -p $pid; done
filename: /lib/modules/2.6.35-ARCH/kernel/drivers/net/igb/igb.ko
version: 3.0.22
license: GPL
description: Intel® Gigabit Ethernet Network Driver
author: Intel Corporation, <e1000-devel@lists.sourceforge.net>
srcversion: 45B8078075068728A5A5573
alias: pci:v00008086d000010D6sv*sd*bc*sc*i*
alias: pci:v00008086d000010A9sv*sd*bc*sc*i*
alias: pci:v00008086d000010A7sv*sd*bc*sc*i*
alias: pci:v00008086d00001526sv*sd*bc*sc*i*
alias: pci:v00008086d000010E8sv*sd*bc*sc*i*
alias: pci:v00008086d0000150Dsv*sd*bc*sc*i*
alias: pci:v00008086d000010E7sv*sd*bc*sc*i*
alias: pci:v00008086d000010E6sv*sd*bc*sc*i*
alias: pci:v00008086d00001518sv*sd*bc*sc*i*
alias: pci:v00008086d0000150Asv*sd*bc*sc*i*
alias: pci:v00008086d000010C9sv*sd*bc*sc*i*
alias: pci:v00008086d00000440sv*sd*bc*sc*i*
alias: pci:v00008086d0000043Csv*sd*bc*sc*i*
alias: pci:v00008086d0000043Asv*sd*bc*sc*i*
alias: pci:v00008086d00000438sv*sd*bc*sc*i*
alias: pci:v00008086d00001527sv*sd*bc*sc*i*
alias: pci:v00008086d00001516sv*sd*bc*sc*i*
alias: pci:v00008086d00001511sv*sd*bc*sc*i*
alias: pci:v00008086d00001510sv*sd*bc*sc*i*
alias: pci:v00008086d0000150Fsv*sd*bc*sc*i*
alias: pci:v00008086d0000150Esv*sd*bc*sc*i*
alias: pci:v00008086d00001524sv*sd*bc*sc*i*
alias: pci:v00008086d00001523sv*sd*bc*sc*i*
alias: pci:v00008086d00001522sv*sd*bc*sc*i*
alias: pci:v00008086d00001521sv*sd*bc*sc*i*
depends: dca
vermagic: 2.6.35-ARCH SMP preempt mod_unload
parm: InterruptThrottleRate:Maximum interrupts per second, per vector, (max 100000), default 3=adaptive (array of int)
parm: IntMode:Change Interrupt Mode (0=Legacy, 1=MSI, 2=MSI-X), default 2 (array of int)
parm: Node:set the starting node to allocate memory on, default -1 (array of int)
parm: LLIPort:Low Latency Interrupt TCP Port (0-65535), default 0=off (array of int)
parm: LLIPush:Low Latency Interrupt on TCP Push flag (0,1), default 0=off (array of int)
parm: LLISize:Low Latency Interrupt on Packet Size (0-1500), default 0=off (array of int)
parm: RSS:Number of Receive-Side Scaling Descriptor Queues (0-8), default 1=number of cpus (array of int)
parm: VMDQ:Number of Virtual Machine Device Queues: 0-1 = disable, 2-8 enable, default 0 (array of int)
parm: max_vfs:Number of Virtual Functions: 0 = disable, 1-7 enable, default 0 (array of int)
parm: QueuePairs:Enable TX/RX queue pairs for interrupt handling (0,1), default 1=on (array of int)
parm: EEE:Enable/disable on parts that support the feature (array of int)
parm: DMAC:Enable/disable on parts that support the feature (array of int)
parm: debug:Debug level (0=none, ..., 16=all) (int)В обзоре (?) не описаны: драйвера, которые использовались (подозреваю igbx?), процессор, с которым это всё работало, как распределялись прерывания, и так далее. Без тюнинга всего этого даже нормальная гигабитная карта — всего лишь офигенно дорогой кусок текстолита и кремния.
Во-первых, производительность карт меряется в пакетах в секунду, а не в битах. Тем более не в байтах.
У меня, например, их 8 штук стоит, и все — WD Black.

{kind=link}
10 гигабитный линк дома?