Интересный факт: в Ruby 1.9.3 с 64-битным интерпретатором обработка строк длиной 23 и менее символов происходит почти вдвое быстрее, чем строк длиной 24 и более символов. Другими словами, этот код Ruby:
… будет обработан в 1,92 раза быстрее, чем этот:
Для 32-битного интерпретатора Ruby граница производительности находится в районе 11/12 символов.
Конечно, довольно глупо изучать свой код и уменьшать все строки до 11 или 23 символов. Разница в производительности проявляется только на сотнях тысяч строк. Однако, желающим покопаться во внутренностях замечательного языка Ruby может быть интересно, почему так происходит.
Разницу в производительности можно увидеть с помощью простого бенчмарка:
Вот какой получается результат на строках разной длины.
В табличке — чуть больше данных, но тенденция понятна.
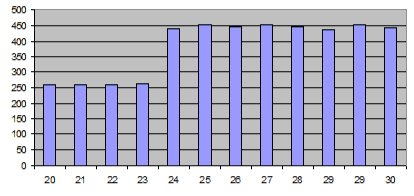
Время создания 1 млн строк (мс), в зависимости от длины строки (символов).
Добавим, что фокус работает только с интерпретатором Ruby 1.9.3, но не 1.8.
Чтобы разобраться в этом, Ruby-разработчик Пэт Шонесси (Pat Shaughnessy) изучил справочник по внутренней работе интерпретаторов Ruby Hacking Guide, в том числе главу 2, где речь идёт о базовых типах данных Ruby, в том числе строках. После этого он решил углубиться в исходный код ruby.h (описание типов данных) и string.c (реализация строк). В коде C и нашлась разгадка.
Всё дело в
Интерпретатор Ruby различает три вида строк, которые можно назвать так:
Далее, интерпретатор проверяет размер строки. Если значение составляет 23 символа или менее, то опять под него не выделяется память из «кучи» и не вызывается
Здесь и кроется разгадка. Подробное описание структуры
Здесь размер массива
На 64-битной машине sizeof(VALUE) равняется 8, что приводит к лимиту в 23 символа.
Значит, без переноса в память непосредственно в структуру
str = "1234567890123456789012" + "x"
… будет обработан в 1,92 раза быстрее, чем этот:
str = "12345678901234567890123" + "x"
Для 32-битного интерпретатора Ruby граница производительности находится в районе 11/12 символов.
Конечно, довольно глупо изучать свой код и уменьшать все строки до 11 или 23 символов. Разница в производительности проявляется только на сотнях тысяч строк. Однако, желающим покопаться во внутренностях замечательного языка Ruby может быть интересно, почему так происходит.
Разницу в производительности можно увидеть с помощью простого бенчмарка:
require 'benchmark' ITERATIONS = 1000000 def run(str, bench) bench.report("#{str.length + 1} chars") do ITERATIONS.times do new_string = str + 'x' end end end
Вот какой получается результат на строках разной длины.
user system total real 21 chars 0.250000 0.000000 0.250000 ( 0.247459) 22 chars 0.250000 0.000000 0.250000 ( 0.246954) 23 chars 0.250000 0.000000 0.250000 ( 0.248440) 24 chars 0.480000 0.000000 0.480000 ( 0.478391) 25 chars 0.480000 0.000000 0.480000 ( 0.479662) 26 chars 0.480000 0.000000 0.480000 ( 0.481211) 27 chars 0.490000 0.000000 0.490000 ( 0.490404)
В табличке — чуть больше данных, но тенденция понятна.
Время создания 1 млн строк (мс), в зависимости от длины строки (символов).
Добавим, что фокус работает только с интерпретатором Ruby 1.9.3, но не 1.8.
Чтобы разобраться в этом, Ruby-разработчик Пэт Шонесси (Pat Shaughnessy) изучил справочник по внутренней работе интерпретаторов Ruby Hacking Guide, в том числе главу 2, где речь идёт о базовых типах данных Ruby, в том числе строках. После этого он решил углубиться в исходный код ruby.h (описание типов данных) и string.c (реализация строк). В коде C и нашлась разгадка.
Всё дело в
malloc — стандартной функции C, которая занимается динамическим распределением памяти. На самом деле это довольно ресурсоёмкая операция, ведь нужно найти свободные блоки памяти нужного размера в «куче», а также отследить освобождение этого блока после выполнения операции.Интерпретатор Ruby различает три вида строк, которые можно назвать так:
- Heap Strings (строки «кучи»)
- Shared Strings (одинаковые строки)
- Embedded Strings (встроенные строки)
RString, но функция malloc применяется только к первому типу строк (строки «кучи»), но не применяется к одинаковым строкам и встроенным строкам, за счёт чего экономятся ресурсы и повышается производительность. Как происходит эта оптимизация? Интерпретатор Ruby сначала проверяет строку на уникальность: если это копия существующей строки, то выделять новую память под неё не надо. Такая структура RString создаётся быстрее всего. struct RString { long len; char *ptr; VALUE shared; };
Далее, интерпретатор проверяет размер строки. Если значение составляет 23 символа или менее, то опять под него не выделяется память из «кучи» и не вызывается
malloc, а значение встраивается непосредственно в структуру RString через char ary[]. struct RString { char ary[RSTRING_EMBED_LEN_MAX + 1]; }
Здесь и кроется разгадка. Подробное описание структуры
RString выглядит так.struct RString { struct RBasic basic; union { struct { long len; char *ptr; union { long capa; VALUE shared; } aux; } heap; char ary[RSTRING_EMBED_LEN_MAX + 1]; } as; };
Здесь размер массива
RSTRING_EMBED_LEN_MAX устанавливается как сумма значений len/ptr/capa, то есть как раз 24 байта. Вот строчка из ruby.h, которая определяет значение RSTRING_EMBED_LEN_MAX.#define RSTRING_EMBED_LEN_MAX ((int)((sizeof(VALUE)*3)/sizeof(char)-1))
На 64-битной машине sizeof(VALUE) равняется 8, что приводит к лимиту в 23 символа.
Значит, без переноса в память непосредственно в структуру
RString может поместиться только 23 символа из значения строки. Если строка превышает это значение, только тогда данные помещаются в «кучу», для чего вызывается malloc и происходят соответствующие ресурсозатратные процедуры. Именно поэтому «длинные» строки обрабатываются медленнее.
