
Если в сельском хозяйстве по осени считают цыплят, то в IT-индустрии в это время традиционно объявляют новинки. И хотя до конца осени далеко и есть шансы, что интересные анонсы еще будут, уже объявленного вполне достаточно для того, чтобы объявить это достойным внимания. Более того, некоторые тенденции весьма любопытны.
На первый взгляд все довольно очевидно: производители жестких дисков устроили очередную гонку объемов, восторженно анонсируя 6-ти, 8-ми и даже 10-ТБ модели. Но все кроется в деталях, а если быть более точными – в специфике применения этих дисков. Сразу оговоримся, что мы будем говорить о серверных аспектах использования дисков.
Так что там, в деталях?
Сперва несколько слов про общую тенденцию: все немногие оставшиеся производители жестких дисков старательно расширяют свои продуктовые линейки. Еще сравнительно недавно выбор был прост: помимо объема достаточно было определиться со скоростью вращения пластин и интерфейсом, после чего выбор сокращался до одной-двух серий. А что сейчас? Enterprise, Cloud, AV, NAS, Green, Performance. Причина такого разнообразия проста: производители дисков уходят от универсальности ради снижения собственных издержек на производство, оставляя в дисках лишь тот минимальный набор особенностей, который необходим. Ну а бонусом такого подхода становится шторм маркетинговых материалов, беспрерывно выливающихся на пользователя.
Ну а теперь давайте о конкретике. Начнем, пожалуй, с WD.

WD Ae
Не успели пользователи обсудить серию Red Pro, предназначенную для весьма узкого сектора рынка «не очень больших NAS», как компания выкатила совершенно чудесную серию Ae, ставшую уже четвертой серией дисков для ЦОД. «Чудесность» серии состоит в том, что объем диска (а он в серии пока только один) плавающий и на текущий момент составляет от 6 до 6,5 ТБ. Насколько смогли сделать партию – настолько и сделали. Очевидно, что продавать столь необычное решение можно лишь «объемами» или партиями, а вовсе не «штуками», иначе покупатели не поймут, почему у соседа за те же деньги больше. Сам производитель пока говорит о партиях «от двадцати дисков».
Второй интересной чертой этих дисков стало то, на какие нагрузки они рассчитаны. Открываем пресс-релиз и читаем, что MTBF составляет всего 500 000 часов – в два-четыре раза меньше, чем обычно заявляется для серверных дисков. Но самое интересное рядом: для этого диска годовая нагрузка предполагается равной 60 ТБ. Да-да, никакой ошибки, 10 перезаписей всего объема в год.

Дисковая полка ETegro Fastor JS200 G3
Разгадка таких значений проста: диск предназначен для хранения холодных, можно даже сказать, ледяных данных. Фактически, перед нами диск, предназначенный для замены ленточных библиотек, задача которого 95 % процентов времени лежать в глубоком сне. Причиной такому переходу стала стоимость хранения данных, которая на дисках с 7200 об/мин составляет около 5-6 центов за гигабайт. Это все ещё дороже, чем хранение данных на лентах, но уже достаточно приемлемо для большинства по цене. И если скорость доступа к данным на ленте в лучшем случае будет составлять несколько секунд, то с диска в дисковой полке получить данные можно менее чем за сотню миллисекунд, при этом нет никаких сложностей в наращивании количества дисков, расширяя полки хоть на целую стойку.

Seagate Enterprise Capasity, 8 ТБ

HGST, 10 ТБ
Следующую «интересность» нам предоставили Seagate и HGST. Первые объявили, что уже отгружают 8-ТБ жесткие диски, на что вторые заметили, что если к этому добавить их фирменную и уже использующуюся в сериях Ultrastar He6 и He8 технологию заполнения дисков гелием, то можно вполне получить и 10 ТБ от диска стандартных размеров. А объединяет эти две новинки то, что в них используется технология черепичной записи (Shingled Magnetic Recording,SMR).
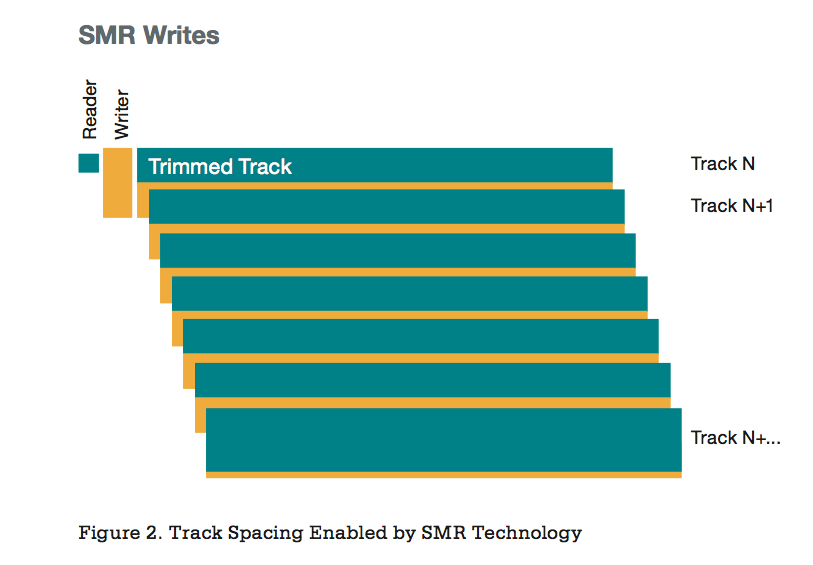
Суть черепичной записи
Напомним, что технология SMR использует тот факт, что ширина головки для чтения в дисках меньше, чем у головки для записи. Поэтому можно вести запись треков с наложением их друг на друга, оставляя «на поверхности» лишь относительно узкую зону каждого трека, достаточную для уверенного чтения. Запись же при этом осуществляется треками большой ширины полями высокой мощности. В сумме это позволяет повысить плотность записи за счет ликвидации межтрекового промежутка при сохранении надежности.
Разговоры о ней идут уже очень давно, но все идет к тому, что 2015 год станет годом ее реального выхода в свет. К этому шло давно, достаточно вспомнить, например, вот этот довольно старый график:

Развитие технологий жестких дисков
Технология сама по себе очень красива, поскольку позволяет повысить плотность без радикального изменения производственного оборудования, идя тем же путем, что и в свое время был пройден при вводе дисков с 4-кБ секторами (Advanced Format). Но у нее есть один недостаток: как только вам надо модифицировать данные, то есть сделать запись в область, вокруг которой есть данные, как вы наталкиваетесь на то, что этим вы сотрете эти самые соседние данные.
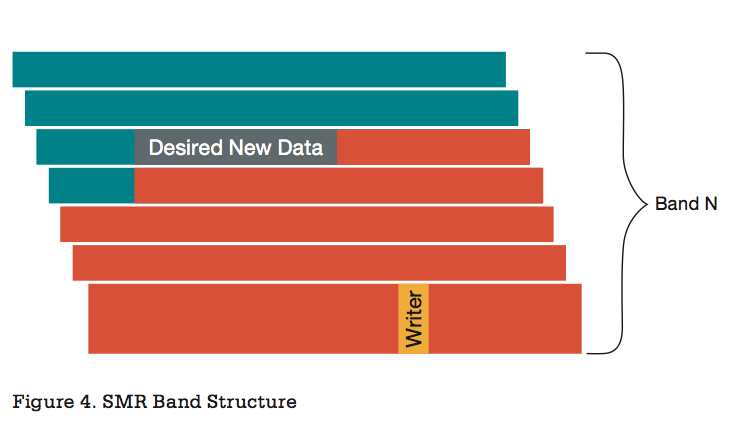
Наложение области записи
Выход из такой ситуации очевиден: черепицу кладут лентами, состоящими из нескольких треков. А между лентами обеспечивают стандартный межтрековый промежуток. И при записи необходимо часть ленты (от модифицируемых данных и до конца ленты) считать, модифицировать, после чего записать обратно. С одной стороны, лента должна быть достаточно широкой, чтобы эффект от черепичного наложения треков все же был заметен, а с другой – большую ленту дольше считывать, дольше записывать, да и хранить где-то надо. Подробностей реализации производители жестких дисков пока не раскрывают, но предположительно размер ленты составляет несколько десятков треков, а каждый трек, на минуточку, сейчас составляет уже более 1 МБ.
Немножко математики, чтобы развеяться: узнать примерное количество данных на треке не так уж и сложно: возьмите скорость диска в МБ/с, разделите на скорость вращения и помножьте на те самые 60 секунд в минуте. Получите количество мегабайт, считываемых за оборот… то есть, за трек. Так, для текущих 4-ТБ дисков на 7200 об/мин эти значения составляют соответственно около 180 МБ/с и 1,5 МБ на трек.
Думаю, все уже поняли, к чему мы клоним. Да, отклик на записи со случайной адресацией данных мы получаем ужасным, в среднем мы будем считывать несколько десятков мегабайт, после чего писать их обратно, что будет занимать ощутимые доли секунды. Не столь ужасно, как на ленточных накопителях, но о привычных миллисекундах придется забыть. Со чтением, конечно, все будет вполне традиционно, а значит диски вполне подойдут под любое использование, подразумевающею схему WORM (Write Once, Read Many) или хранение холодных данных. Теоретически, производители дисков могут творчески перенять опыт использования SSD и адаптировать под себя TRIM и трансляцию адресов, но пока об этом лишь поговаривают на уровне теории.
Есть и еще одно важное следствие из такой организации жестких дисков. И состоит оно в том, что, похоже, переход на подобные диски полностью убьет RAID-массивы с записью контрольных сумм. Размеры блоков записи там сильно меньше размера ленты в SMR, а это значит, что при любой перезаписи старых данных мы получаем чудовищное пенальти. «Отличное» дополнение к тому факту, что RAID5 на массивах из современных дисков с 7200 об/мин, имеющих типичную битовую частоту невосстановимых ошибок 1 на 10^15, уже становится ненадежным вариантом хранения при размере массива более 100 ТБ – такая ошибка хотя бы раз, но случится во время перестроения массива. А ведь такой объем — это всего одна дисковая полка. Вишенкой на торте является совершенно бесчеловечное время ребилда таких массивов, на протяжении которого дисковая подсистема работает с уменьшенной производительностью. Так что есть все шансы, что в ближайшем будущем самым популярным способом хранить данные станут многочисленные дисковые полки с JBOD’ами, данные на дисках которых будут силами ОС многократно дублироваться.
Что же касается дисковой подсистемы для «горячих» данных, то здесь вот уже который год правят бал SSD и радикальных изменений не предвидится. В зависимости от объемов данных, все будет решаться либо локальными для сервера накопителями, такими как HGST Ultrastar SN100 или Intel SSD DC P3700, благо, их объем уже дошел до 2 ТБ, либо целыми all-flash дисковыми полками. Первые во всю перебрались на интерфейс NVMe, обеспечивающий минимальные задержки и более эффективную работу в условиях действительно высоких нагрузок (подробнее – в нашей предыдущей статье). Разработчики протокола NVMe не теряют времени даром и уже объявили о разработке стандарта NVMe over Fabrics, который позволит использовать все достоинства протокола NVMe при работе по таким средам обмена данными как Ethernet с использованием RDMA, InfiniBand, и Intel Omni Scale Fabric. И Fibre Channel Industry Association (FCIA), к слову, под это дело уже организовала отдельную рабочую группу. Но это еще дело несколько отдаленного будущего, в ближайшем же у нас наметилась явная миграция на стандарт SAS 12G, под который активно начала появляться инфраструктура в виде контроллеров и экспандеров.
