Всем привет! Мы, в компании Cackle, занимаемся разработкой облачных SaaS-решений для сайтов с 2011 года. Наши продукты установлены более чем на 10 000 сайтах, каждый день мы обрабатываем в среднем 65 миллионов уникальных хитов. Полоса пропускания (bandwidth) в пики доходит до 780 мбит/сек, а БД в сутки принимает до 120 миллионов запросов на чтение, и до 300 тысяч запросов на запись. Такие нагрузки заставляют изобретать непростые решения, частью которых мы и хотим поделиться.

Сначала пара слов о том, что мы вообще разработали, на каких технологиях и архитектуре всё базируется, откуда берётся высокая нагрузка. А далее – про 5 основных решений, которые мы применяем чтобы с этой нагрузкой справиться.
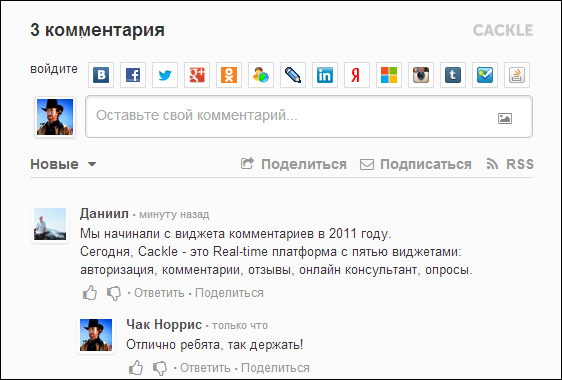
Cackle Comments – наш первый продукт, анонсированный в 2011 году.
Упрощает процесс комментирования за счёт удобной авторизации – анонимной, социальной или единой с вашим сайтом. Помогает привлечь больше трафика благодаря индексации в поисковиках, трансляции комментариев на стены социальных сетей (ВК, Мой Мир, Facebook, Twitter), подписке на новые комментарии и ответы. Снижает нагрузку за счёт независимости от вашего сайта.
Cackle Reviews – система отзывов, релиз которой состоялся в 2013 году. Используется в основном интернет-магазинами, но без проблем работает на любом сайте.
Основные возможности:

Cackle Live Chat – онлайн-чат для посетителей сайта, релиз в 2013 году.
Из особенностей: быстрая установка, панель оператора реализована в браузере, не нужно тратить время на инсталляцию desktop-клиента. Социальная авторизация пользователей, при этом оператор получает информацию о клиенте (имя, фото, email, ссылку на профиль).

Cackle Polls – опросы с возможностью голосования через социальные сети, IP или Cookie, релиз также в 2013 году.
Опросы автоматически индексируются в Google, привлекая дополнительный трафик. Можно загружать изображения, есть распознавание видео YouTube и Vimeo.
Фронтенд в понимании Cackle – это JavaScript. Бекенд – сервера данных и логики.
Фронтенд состоит из виджетов. Виджет – это исполняемая JavaScript-библиотека, базирующаяся на других, общих, JavaScript-библиотеках. Примеры общих библиотек:
Все виджеты работают без iframe, за счёт чего возможна модификация css под стиль вашего сайта.
Есть общий загрузчик виджетов (widget.js), что-то на подобии RequireJS, только более простой. У загрузчика два режима работы – devel и prod. Первый применяется при разработке, загружает библиотеки в цикле. Второй на продакшене, грузит собранный бандл (bundle). В prod режиме загрузка виджетов происходит с разных серверов выбранных случайным образом, в итоге получается балансинг (подробнее об этом дальше).
Это кластер Apache Tomcat контейнеров, снаружи обернутых Nginx-серверами. Nginx в данном случае выступает не только как прокси, но и как «поглотитель» нагрузки. База данных PostgreSQL с потоковой репликацией на несколько слейвов.
Все бекенды распределены по нескольким дата-центрам (ЦОДам) России и Европы. Наш опыт показал, что хостить все сервера в одном дата-центре слишком рискованно, поэтому сейчас мы подключены к трём разным ЦОДам.
Поддержка обновлений в режиме реального времени (комментарии, лайки, редактирование, модерация, личные сообщения, чат) на стороне браузера, происходит через любую из поддерживаемых технологий: WebSocket, EventSource, Long-Polling. То есть, сначала мы проверяем есть ли WebSocket, далее EventSource, Long-Polling. При дисконнектах (ошибках) связь автоматически восстанавливается функцией, которая в setTimeout мониторит состояние подключения.
На сервере мы используем кластер Nginx + модуль Push Stream. Всего 3 сервера: 2 общих и 1 для онлайн-консультанта. Real-time сообщения из бекендов (Tomcat-ов) отправляются на все сервера. А в браузере, при подключении из виджета, выбирается любой сервер (случайным образом). В итоге получается, что-то на подобии балансинга (к сожалению, Push Stream балансинг «из коробки» не поддерживает).
Кроме этого есть:

PG — PostgreSQL.
RT — Real-time.
ЦОД (1,2,..., N) — различные дата-центры.
RMI — Java технология удаленного вызова методов (wikipedia).
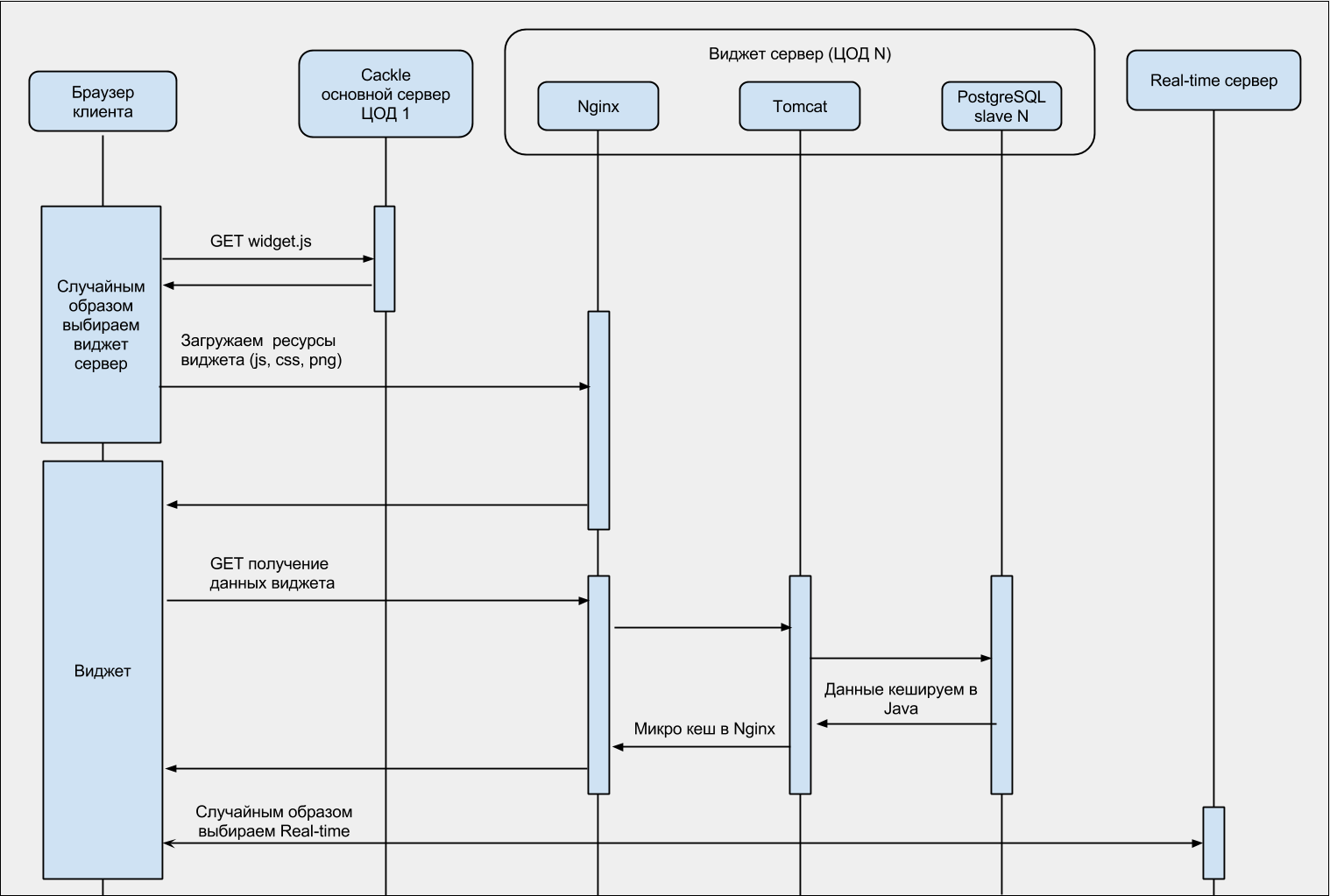
Для лучшего понимания, диаграмма последовательности загрузки виджета:
Ниже суммарная статистика по виджетам и обращениям к API.
Уникальных хитов в сутки: 60 — 70 миллионов
Пик запросов в секунду: 2700
Пик одновременных real-time сессий: 300 000
Пиковая пропускная способность: 780 мбит/с
Трафик в сутки: 1.6 Тбайт
Ежедневный суммарный лог Nginx: 102 Гбайт
Запросов к БД на чтение (в сутки): 80 — 120 миллионов
Запросов к БД на запись (в сутки): 300 000
Количество зарегистрированных сайтов: 32 558
Количество зарегистрированных пользователей: 8 220 681
Комментариев опубликовано: 23 840 847
Ежедневный средний прирост комментариев: 50 000
Ежедневный средний прирост пользователей: 15 000
Высокая нагрузка порождает две проблемы:
Во-первых, практически у всех хостеров по умолчанию пропускная способность (bandwidth) сервера 100 мбит/с. Все что выше режется или в лучшем случае вас просят докупить дополнительную полосу (а цены там в разы выше стоимости самих серверов).
Вторая проблема – это и есть сама нагрузка. Физику не обманешь, каким бы ни был крутым ваш сервер, у него есть свой предел.
Стандартные методы распределения нагрузки говорят о балансинге входного запроса на сервере. Это решит вторую проблему, но не первую (bandwidth), так как исходящий трафик все равно пойдет через тот же сервер.
Чтоб решить две проблемы одновременно, мы делаем балансинг в JavaScript, в самом загрузчике (widget.js), выбирая бекенд случайным образом. В итоге, трафик перенаправляем на сервера из кластера виджет серверов разделяя между ними bandwidth и распределяя нагрузку.
Дополнительный огромный плюс этого метода, в кешировании JavaScript. Все библиотеки (включая загрузчик widget.js), при обновлении страницы, будут получены из кеша браузера, а наши сервера продолжат спокойно обрабатывать новые запросы.
Продолжение кода загрузчика (widget.js часть 2):
Это здорово! Проблема только в том, что при наших объемах и нагрузках для того, чтобы использовать CDN необходимо поднять цены минимум в 3 раза, сохранив при этом текущий оборот.
Микрокеш это кеш с очень коротким сроком жизни, например 3 секунды. Он очень полезен при пиковых нагрузках, когда в секунду идут тысячи одинаковых GET запросов. Для нас это данные виджетов в JSON формате. Микрокеш имеет смысл делать в proxy серверах, например Nginx для защиты основного бекенда (Tomcat).
Часть конфига Nginx с микрокешем:
Если есть проблемы с пониманием данного конфига, то обязательно для чтения ngx_http_proxy_module.
Особо протюнинговать Tomcat не получится. Из практического опыта:
Принято считать БД, в высоконагруженных проектах, слабым местом. Это действительно так. Например, сервер принимает запрос, отправляет его в сервисный уровень, там сервис обращается к БД и возвращает результат. Связка «сервис — БД (реляционная)» в этом случае работает медленнее всех, поэтому принято оборачивать сервисы кешем. Соответственно результат из БД, кладется в кеш сервиса, и при следующем обращении берется уже из него.
Для кеширования сервисов мы разработали свой кеш, так как стандартные (например Ehcache) работают медленнее и не всегда хорошо решают специфические задачи. Из специфических задач у нас – кеширование с поддержкой нескольких ключей для одного значения. Мы используем org.apache.commons.collections.map.MultiKeyMap.
Нужно это вот для каких задач. Например пользователь заходит на страницу с комментариями. Допустим комментариев много, 300 штук. Они разбиты на три страницы (пагинация) соответственно по 100 каждая. При первом обращении, будет закеширована первая страница (100 комментариев), если пользователь листает вниз, то по очереди закешируется 2 и 3 страницы. Теперь пользователь публикует комментарий на этой странице и тут надо сбросить все три кеша. Используя MultiKeyMap это выглядит примерно так:
Ниже код ядра кеша отлично работающий на highload.
На наш взгляд PostgreSQL лучшее решение для высоконагруженных проектов. Сейчас модно применять NoSQL, но в большинстве случаев, при правильном подходе и верной архитектуре, PostgreSQL лучше.
В PostgreSQL отлично работает потоковая репликация, причем не важно в одной подсети или в разных сетях, разных дата-центрах. У нас, например, сервера БД расположены в нескольких странах и серьезных проблем замечено не было. Единственный нюанс — это большие модификации базы (ALTER TABLE) при релизах. Делать их надо кусками, стараясь не выполнять за раз весь UPDATE.
По настройке репликации есть много ресурсов, это избитая тема, так что добавить особо нечего, кроме:
Не забывайте тюнить параметры ядра ОС, так как без этого некоторые настройки Nginx или Tomcat просто не будут работать.
У нас, например, везде Debian. В настройках ядра ОС (/etc/sysctl.conf) особое внимание нужно обратить на:
Вернее одна проблема – размер БД. Есть, конечно, шардинг, но стандартного решения для PostgreSQL без падения производительности пока не нашли. Если кто-то может поделиться практическим опытом – welcome!
Спасибо за внимание. Вопросы и пожелания по нашей системе приветствуются!

Сначала пара слов о том, что мы вообще разработали, на каких технологиях и архитектуре всё базируется, откуда берётся высокая нагрузка. А далее – про 5 основных решений, которые мы применяем чтобы с этой нагрузкой справиться.
Система комментариев
Cackle Comments – наш первый продукт, анонсированный в 2011 году.
Упрощает процесс комментирования за счёт удобной авторизации – анонимной, социальной или единой с вашим сайтом. Помогает привлечь больше трафика благодаря индексации в поисковиках, трансляции комментариев на стены социальных сетей (ВК, Мой Мир, Facebook, Twitter), подписке на новые комментарии и ответы. Снижает нагрузку за счёт независимости от вашего сайта.
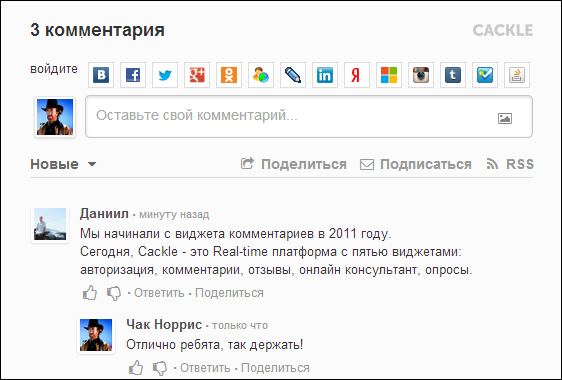
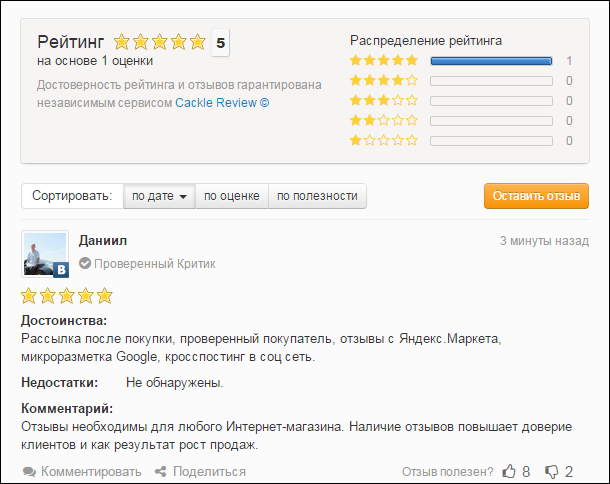
Система отзывов для интернет-магазинов
Cackle Reviews – система отзывов, релиз которой состоялся в 2013 году. Используется в основном интернет-магазинами, но без проблем работает на любом сайте.
Основные возможности:
- Загрузка отзывов с Яндекс.Маркета;
- Индексация в Google с микроразметкой «из коробки» (рейтинг в результатах поиска);
- Follow-up рассылка писем с приглашением оставить отзыв после покупки;
- Удобная анонимная, социальная, единая авторизация;
- Трансляция отзывов в социальные сети: ВК, Мой Мир, Facebook, Twitter;
- Модерация отзывов в режиме реального времени;
- Комментарии к отзывам;
- СПАМ-защита;
- CMS плагины: 1С-Битрикс, Joomla (K2, Virtuemart, Zoo), OpenCart, PrestaShop.
Online-консультант
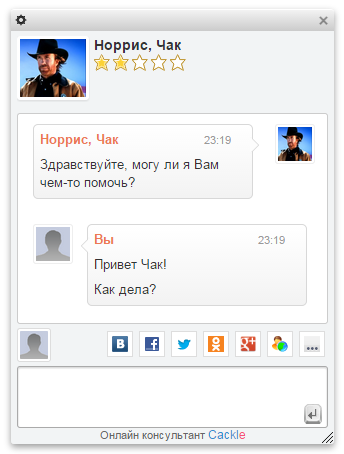
Cackle Live Chat – онлайн-чат для посетителей сайта, релиз в 2013 году.
Из особенностей: быстрая установка, панель оператора реализована в браузере, не нужно тратить время на инсталляцию desktop-клиента. Социальная авторизация пользователей, при этом оператор получает информацию о клиенте (имя, фото, email, ссылку на профиль).
Виджет опросов
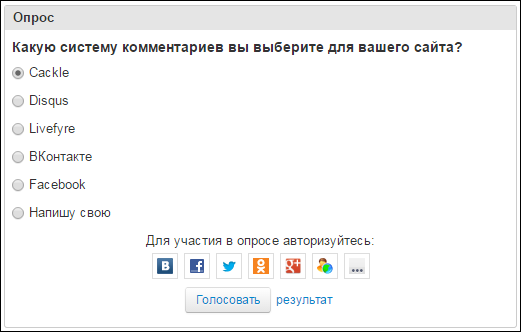
Cackle Polls – опросы с возможностью голосования через социальные сети, IP или Cookie, релиз также в 2013 году.
Опросы автоматически индексируются в Google, привлекая дополнительный трафик. Можно загружать изображения, есть распознавание видео YouTube и Vimeo.
Технологии
Фронтенд в понимании Cackle – это JavaScript. Бекенд – сервера данных и логики.
Фронтенд
Фронтенд состоит из виджетов. Виджет – это исполняемая JavaScript-библиотека, базирующаяся на других, общих, JavaScript-библиотеках. Примеры общих библиотек:
- Библиотека для работы с DOM: jQuery сильно тормозил и не работал на нескольких мобильных платформах, поэтому написали свое решение на Vanilla JS. В итоге по некоторым операциям скорость работы выросла в 600 раз + наше решение работает на всех версиях Android и iOS;
- Библиотека единой авторизации (анонимная, социальная, SSO);
- Библиотека поддержки Real-time режима с умным выбором протокола взаимодействия (WebSocket, EventSource, Long-Polling);
- Библиотека кроссдоменных GET/POST запросов;
- И другие: работа с датой, БД браузера (cookie, localstorage), json, загрузка изображений, распознавание видео (YouTube, Vimeo), tray нотификации, пагинация и др.
Все виджеты работают без iframe, за счёт чего возможна модификация css под стиль вашего сайта.
Есть общий загрузчик виджетов (widget.js), что-то на подобии RequireJS, только более простой. У загрузчика два режима работы – devel и prod. Первый применяется при разработке, загружает библиотеки в цикле. Второй на продакшене, грузит собранный бандл (bundle). В prod режиме загрузка виджетов происходит с разных серверов выбранных случайным образом, в итоге получается балансинг (подробнее об этом дальше).
Кроссбраузерный код загрузчика (widget.js часть 1)
Cackle.Bootstrap = Cackle.Bootstrap || {
appendToRoot: function(child) {
(document.getElementsByTagName('head')[0] || document.getElementsByTagName('body')[0]).appendChild(child);
},
//загружает js
loadJs: function(src, callback) {
var script = document.createElement('script');
script.type = 'text/javascript';
script.src = src;
script.async = true;
if (callback) {
if (typeof script.onload != 'undefined') {
script.onload = callback;
} else if (typeof script.onreadystatechange != 'undefined') {
script.onreadystatechange = function () {
if (this.readyState == 'complete' || this.readyState == 'loaded') {
callback();
}
};
} else {
script.onreadystatechange = script.onload = function() {
var state = script.readyState;
if (!state || /loaded|complete/.test(state)) {
callback();
}
};
}
}
this.appendToRoot(script);
},
//загружает css
loadCss: function(href) {
var style = document.createElement('link');
style.rel = 'stylesheet';
style.type = 'text/css';
style.href = href;
this.appendToRoot(style);
},
//загружает несколько css
loadCsss: function(url, css) {
for (var i = 0; i < css.length; i++) {
Cackle.Bootstrap.loadCss(url + css[i] + Cackle.ver);
}
},
//загружает несколько js
loadJss: function(url, js, i) {
var handler = this;
if (js.length > i) {
Cackle.Bootstrap.loadJs(url + js[i] + Cackle.ver, function() {
handler.loadJss(url, js, i + 1);
});
}
},
//общий загрузчик ресурсов
load: function(host, js, css) {
var url = host + '/widget/';
this.loadJss(url + 'js/', js, 0);
if (css) this.loadCsss(url + 'css/', css);
},
/**
* Далее идут виджеты, например, комментариев
*/
Comment: {
isLoaded: false,
load: function(host) {
this.isLoaded = true;
if (Cackle.env == 'prod') {
//В продакшене загружаем бандл
Cackle.Bootstrap.load(host, ['comment.js'], ['comment.css']);
} else {
//При разработке синхронно загружаем библиотеки и сам виджет для модификации/дебага
Cackle.Bootstrap.load(host, ['fastjs.js',
'json2.js',
'rt.js',
'xpost.js',
'storage.js',
'login.js',
'comment.js'],
['comment.css']);
}
}
},
...
};
//Загружаем виджет комментариев (widget == 'Comment')
//host - случайный сервер из кластера (об этом дальше)
if (!Cackle.Bootstrap[widget].isLoaded) {
Cackle.Bootstrap[widget].load(host);
}
Бекенд
Это кластер Apache Tomcat контейнеров, снаружи обернутых Nginx-серверами. Nginx в данном случае выступает не только как прокси, но и как «поглотитель» нагрузки. База данных PostgreSQL с потоковой репликацией на несколько слейвов.
Все бекенды распределены по нескольким дата-центрам (ЦОДам) России и Европы. Наш опыт показал, что хостить все сервера в одном дата-центре слишком рискованно, поэтому сейчас мы подключены к трём разным ЦОДам.
Real-time
Поддержка обновлений в режиме реального времени (комментарии, лайки, редактирование, модерация, личные сообщения, чат) на стороне браузера, происходит через любую из поддерживаемых технологий: WebSocket, EventSource, Long-Polling. То есть, сначала мы проверяем есть ли WebSocket, далее EventSource, Long-Polling. При дисконнектах (ошибках) связь автоматически восстанавливается функцией, которая в setTimeout мониторит состояние подключения.
На сервере мы используем кластер Nginx + модуль Push Stream. Всего 3 сервера: 2 общих и 1 для онлайн-консультанта. Real-time сообщения из бекендов (Tomcat-ов) отправляются на все сервера. А в браузере, при подключении из виджета, выбирается любой сервер (случайным образом). В итоге получается, что-то на подобии балансинга (к сожалению, Push Stream балансинг «из коробки» не поддерживает).
Кроме этого есть:
- Сервер загрузки, обработки и хранения изображений;
- SMTP сервер.
Архитектура
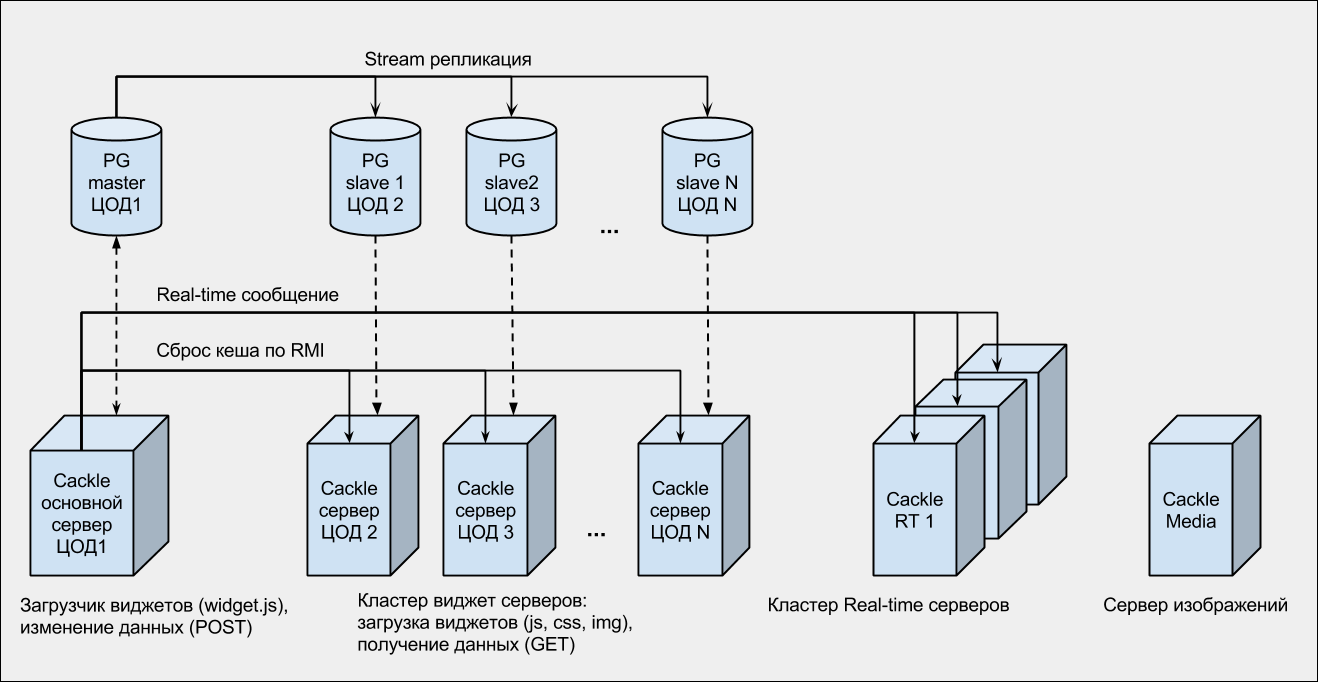
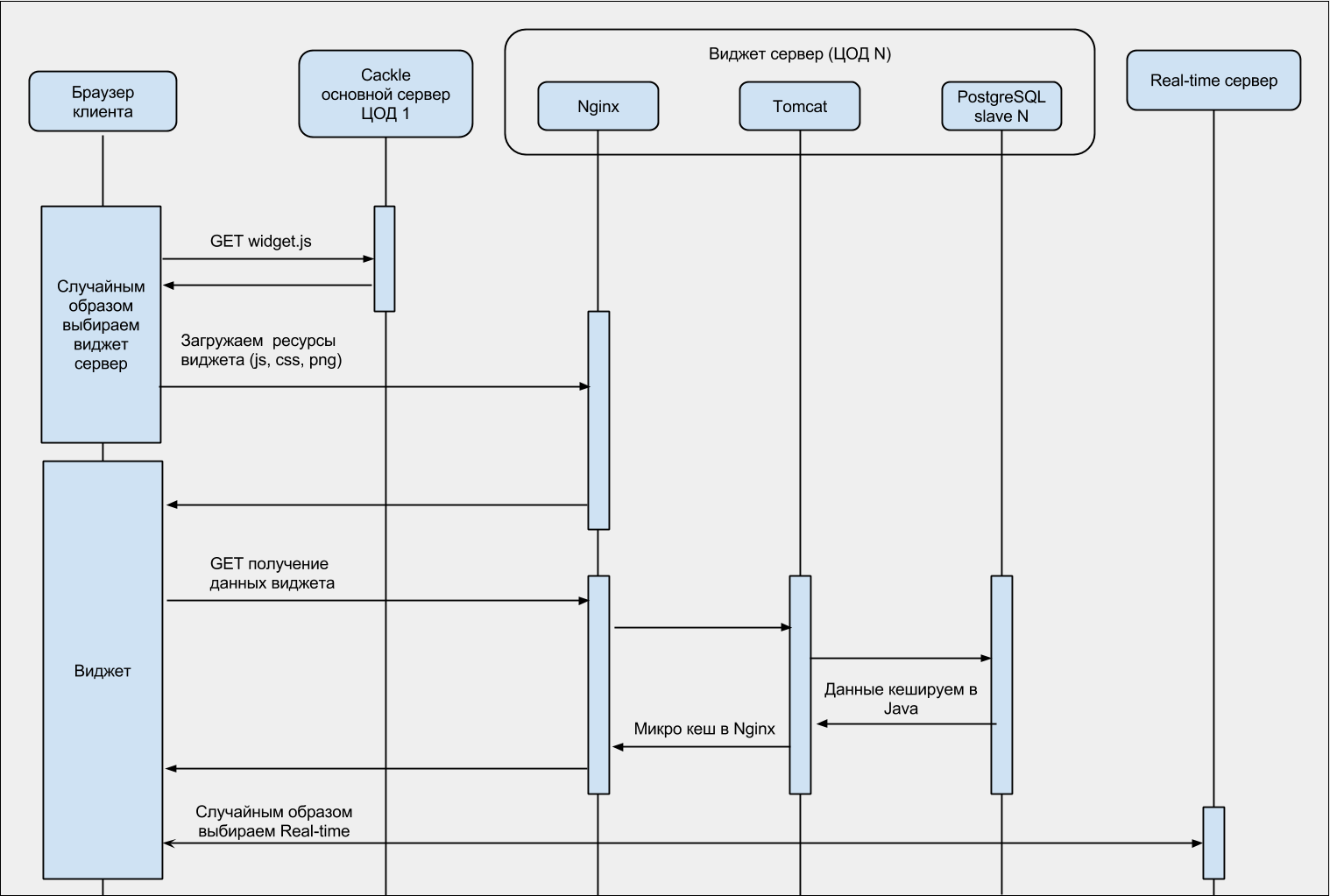
PG — PostgreSQL.
RT — Real-time.
ЦОД (1,2,..., N) — различные дата-центры.
RMI — Java технология удаленного вызова методов (wikipedia).
Для лучшего понимания, диаграмма последовательности загрузки виджета:
Нагрузка
Ниже суммарная статистика по виджетам и обращениям к API.
Уникальных хитов в сутки: 60 — 70 миллионов
Пик запросов в секунду: 2700
Пик одновременных real-time сессий: 300 000
Пиковая пропускная способность: 780 мбит/с
Трафик в сутки: 1.6 Тбайт
Ежедневный суммарный лог Nginx: 102 Гбайт
Запросов к БД на чтение (в сутки): 80 — 120 миллионов
Запросов к БД на запись (в сутки): 300 000
Количество зарегистрированных сайтов: 32 558
Количество зарегистрированных пользователей: 8 220 681
Комментариев опубликовано: 23 840 847
Ежедневный средний прирост комментариев: 50 000
Ежедневный средний прирост пользователей: 15 000
Проблемы
Высокая нагрузка порождает две проблемы:
Во-первых, практически у всех хостеров по умолчанию пропускная способность (bandwidth) сервера 100 мбит/с. Все что выше режется или в лучшем случае вас просят докупить дополнительную полосу (а цены там в разы выше стоимости самих серверов).
Вторая проблема – это и есть сама нагрузка. Физику не обманешь, каким бы ни был крутым ваш сервер, у него есть свой предел.
» Решение 1: балансинг в JavaScript
Стандартные методы распределения нагрузки говорят о балансинге входного запроса на сервере. Это решит вторую проблему, но не первую (bandwidth), так как исходящий трафик все равно пойдет через тот же сервер.
Чтоб решить две проблемы одновременно, мы делаем балансинг в JavaScript, в самом загрузчике (widget.js), выбирая бекенд случайным образом. В итоге, трафик перенаправляем на сервера из кластера виджет серверов разделяя между ними bandwidth и распределяя нагрузку.
Дополнительный огромный плюс этого метода, в кешировании JavaScript. Все библиотеки (включая загрузчик widget.js), при обновлении страницы, будут получены из кеша браузера, а наши сервера продолжат спокойно обрабатывать новые запросы.
Продолжение кода загрузчика (widget.js часть 2):
var Cackle = Cackle || {};
Cackle.protocol = ('https:' == window.location.protocol) ? 'https:' : 'http:';
Cackle.host = Cackle.host || 'cackle.me';
Cackle.origin = Cackle.protocol + '//' + Cackle.host;
//Кластер виджет серверов (a.cackle.me, b.cackle.me, c.cackle.me):
Cackle.cluster = ['a.' + Cackle.host, 'b.' + Cackle.host, 'c.' + Cackle.host];
//Тут код загрузчика, см. выше widget.js часть 1
Cackle.getRandInt = function(min, max) {
return Math.floor(Math.random() * (max - min + 1)) + min;
}
Cackle.getRandHost = function() {
return Cackle.cluster[Cackle.getRandInt(0, Cackle.cluster.length - 1)];
};
Cackle.initHosts = function() {
//getRandHost собственно и есть балансинг
var host = Cackle.getRandHost();
for (var i = 0; i < cackle_widget.length; i++) {
cackle_widget[i].host = Cackle.protocol + '//' + host;
}
};
//cackle_widget - служебный массив содержищай виджеты для загрузки,
//он заполняется в коде самого виджета (на сайте клиента).
//Например: cackle_widget.push({widget: 'Comment', id: 1});
Cackle.main = function() {
Cackle.initHosts();
for (var i = 0; i < cackle_widget.length; i++) {
var widget = cackle_widget[i].widget;
if (!Cackle.Bootstrap[widget].isLoaded) {
Cackle.Bootstrap[widget].load(cackle_widget[i].host);
}
}
};
Cackle.main();
А как на счет профессионального CDN?
Это здорово! Проблема только в том, что при наших объемах и нагрузках для того, чтобы использовать CDN необходимо поднять цены минимум в 3 раза, сохранив при этом текущий оборот.
» Решение 2: микрокеш Nginx
Микрокеш это кеш с очень коротким сроком жизни, например 3 секунды. Он очень полезен при пиковых нагрузках, когда в секунду идут тысячи одинаковых GET запросов. Для нас это данные виджетов в JSON формате. Микрокеш имеет смысл делать в proxy серверах, например Nginx для защиты основного бекенда (Tomcat).
Часть конфига Nginx с микрокешем:
...
location /bootstrap {
try_files $uri @proxy;
}
...
location @proxy {
#Бекенд (Tomcat)
proxy_pass http://localhost:8888;
proxy_redirect off;
#В интернете много постов про настройку Nginx кеша,
#но почему-то нигде не сказано, что без этого ничего работать не будет
proxy_ignore_headers X-Accel-Expires Expires Cache-Control;
set $no_cache "";
#Кешируем только GET|HEAD
if ($request_method !~ ^(GET|HEAD)$) {
set $no_cache "1";
}
if ($no_cache = "1") {
add_header Set-Cookie "_mcnc=1; Max-Age=2; Path=/";
add_header X-Microcachable "0";
}
if ($http_cookie ~* "_mcnc") {
set $no_cache "1";
}
proxy_cache microcache;
proxy_no_cache $no_cache;
proxy_cache_bypass $no_cache;
proxy_cache_key $scheme$host$request_method$request_uri;
#Кешируем на 3 секунды
proxy_cache_valid 200 301 302 3s;
proxy_cache_use_stale error timeout http_500 http_502 http_503 http_504 http_403 http_404 updating;
default_type application/json;
}
...
Если есть проблемы с пониманием данного конфига, то обязательно для чтения ngx_http_proxy_module.
» Решение 3: тюнинг Tomcat, Java кеш
Tomcat
Особо протюнинговать Tomcat не получится. Из практического опыта:
- Не морочьте голову с выбором коннектора (Http11Protocol, Nio, Apr). При больших нагрузках это не играет роли.
- Сделайте connectionTimeout минимальным, какой только возможно, желательно не больше 5 секунд.
- Не делайте слишком большой maxThreads, он не поможем, а в некоторых ситуация только навредит. Стандарт для нагруженного проекта 300-350. Если этого мало, добавьте новый Tomcat сервер.
- А вот acceptCount можно сделать несколько тысяч (2000-4000). При маленьких значениях подключения отрубаются (connection refused), а так будут складываться в очередь. При этом не забудьте в ОС выставить такой же или больше backlog.
Java кеш
Принято считать БД, в высоконагруженных проектах, слабым местом. Это действительно так. Например, сервер принимает запрос, отправляет его в сервисный уровень, там сервис обращается к БД и возвращает результат. Связка «сервис — БД (реляционная)» в этом случае работает медленнее всех, поэтому принято оборачивать сервисы кешем. Соответственно результат из БД, кладется в кеш сервиса, и при следующем обращении берется уже из него.
Для кеширования сервисов мы разработали свой кеш, так как стандартные (например Ehcache) работают медленнее и не всегда хорошо решают специфические задачи. Из специфических задач у нас – кеширование с поддержкой нескольких ключей для одного значения. Мы используем org.apache.commons.collections.map.MultiKeyMap.
Нужно это вот для каких задач. Например пользователь заходит на страницу с комментариями. Допустим комментариев много, 300 штук. Они разбиты на три страницы (пагинация) соответственно по 100 каждая. При первом обращении, будет закеширована первая страница (100 комментариев), если пользователь листает вниз, то по очереди закешируется 2 и 3 страницы. Теперь пользователь публикует комментарий на этой странице и тут надо сбросить все три кеша. Используя MultiKeyMap это выглядит примерно так:
MultiKeyMap cache = MultiKeyMap.decorate(new LRUMap(capacity));
cache.put(chanId, "page1", commentSerivce.list(chanId, 1)); //chanId - id страницы с комментариями
cache.put(chanId, "page2", commentSerivce.list(chanId, 2)); //commentSerivce.list - получаем комментарии на странице (chanId) с пагинацией (2)
cache.put(chanId, "page3", commentSerivce.list(chanId, 3));
cache.removeAll(chanId); //Удаляем все 3 кеша на странице для всех пагинаций
Ниже код ядра кеша отлично работающий на highload.
Ядро кеша: thread-safety, отложенное и единственное выполнение кеширующего результата, мягкие ссылки для избежания OOM
public class CackleCache {
private final MultiKeyMap CACHE = MultiKeyMap.decorate(new LRUMap(capacity));
public static class SoftValue<K, V> extends SoftReference<V> {
final K key;
final long expired;
public SoftValue(V ref, ReferenceQueue<V> q, K key, long timelife) {
super(ref, q);
this.key = key;
this.expired = System.currentTimeMillis() + timelife;
}
}
public synchronized Future<Object> get(final MultiKey key, final long timelife, final MethodInvocation invocation) {
Future<Object> ret;
@SuppressWarnings("unchecked")
SoftValue<MultiKey, Future<Object>> sr = (SoftValue<MultiKey, Future<Object>>) CACHE.get(key);
if (sr != null) {
ret = sr.get();
if (ret != null) {
if (sr.expired > System.currentTimeMillis()) {
return ret;
} else {
sr.clear();
}
}
}
ret = executor.submit(new Callable<Object>() {
@Override
public Object call() throws Exception {
try {
return invocation.proceed();
} catch (Throwable t) {
throw new Exception(t);
}
}
});
SoftValue<MultiKey, Future<Object>> value = new SoftValue<MultiKey, Future<Object>>(ret, referenceQueue, key, timelife);
CACHE.put(key, value);
return ret;
}
public synchronized void evict(Object key) {
try {
CACHE.removeAll(key);
} catch (Throwable t) {}
}
}
» Решение 4: PostgreSQL с потоковой репликацией в разные дата-центры
На наш взгляд PostgreSQL лучшее решение для высоконагруженных проектов. Сейчас модно применять NoSQL, но в большинстве случаев, при правильном подходе и верной архитектуре, PostgreSQL лучше.
В PostgreSQL отлично работает потоковая репликация, причем не важно в одной подсети или в разных сетях, разных дата-центрах. У нас, например, сервера БД расположены в нескольких странах и серьезных проблем замечено не было. Единственный нюанс — это большие модификации базы (ALTER TABLE) при релизах. Делать их надо кусками, стараясь не выполнять за раз весь UPDATE.
По настройке репликации есть много ресурсов, это избитая тема, так что добавить особо нечего, кроме:
- Обязательно сделайте план (конфиг) на случай failover (падение мастера) и реально протестируйте это;
- Поймите принцип работы WAL, чтоб в случае рассинхронизации слейва и мастера знать зачем вам архивы и куда их надо положить;
- Следите за местом на HDD мастера, если вдруг его не станет, то PostgreSQL может упасть, а при репликации это чревато большими неприятностями.
» Решение 5: тюнинг ОС
Не забывайте тюнить параметры ядра ОС, так как без этого некоторые настройки Nginx или Tomcat просто не будут работать.
У нас, например, везде Debian. В настройках ядра ОС (/etc/sysctl.conf) особое внимание нужно обратить на:
kernel.shmmax = 8000234752 // Это для PostgreSQL, чтоб можно было выставлять большой shared_buffers (6 - 8GB)
fs.file-max = 99999999 // Это для Nginx, без него можно получить "Too many open files"
net.ipv4.tcp_max_syn_backlog=524288 // Максимальное число запоминаемых запросов на соединение
net.ipv4.tcp_max_orphans=262144 // Максимальное число допустимых в системе сокетов TCP
net.core.somaxconn=65535 // Максимальное число открытых сокетов
net.ipv4.tcp_mem=1572864 1835008 2097152 // Потребление памяти для протокола TCP
net.ipv4.tcp_rmem=4096 16384 16777216 // Размер приемного буфера сокетов TCP
net.ipv4.tcp_wmem=4096 32768 16777216 // Количество памяти, резервируемой для буферов передачи сокета TCPПроблемы, которые пока решить не удалось
Вернее одна проблема – размер БД. Есть, конечно, шардинг, но стандартного решения для PostgreSQL без падения производительности пока не нашли. Если кто-то может поделиться практическим опытом – welcome!
Спасибо за внимание. Вопросы и пожелания по нашей системе приветствуются!

{kind=link}