В последние годы NoSQL и BigData стали очень популярными в ИТ-индустрии, и на базе NoSQL успешно реализованы тысячи проектов. Часто на разных конференциях и форумах слушатели задают вопрос о том, как модернизировать или перенести старые системы (legacy) в NoSQL. К счастью, у нас был опыт перехода из SQL на NoSQL в крупном проекте СМЭВ 2.0, о котором я и расскажу под катом.

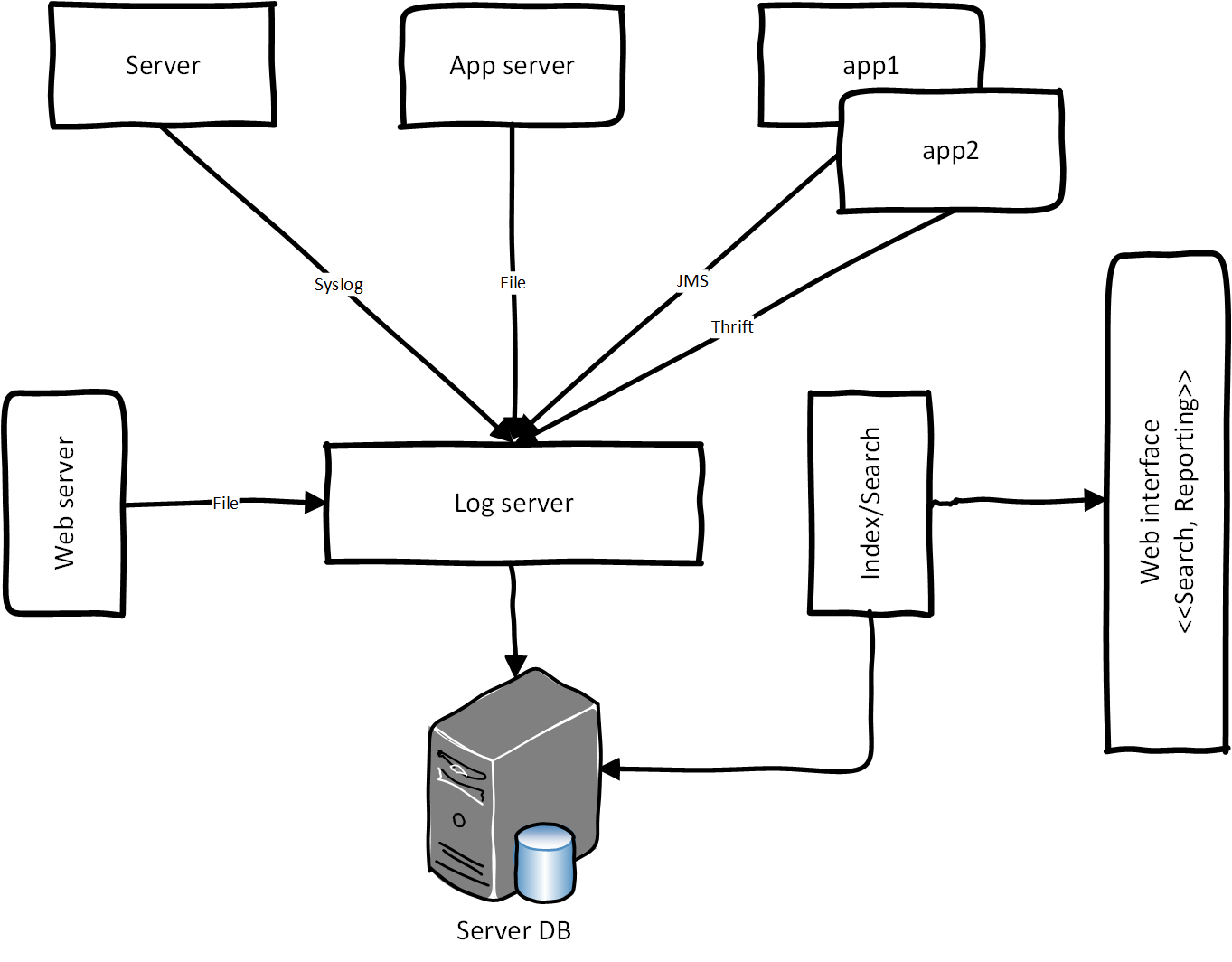
В 2011 году в одном из флагманских проектов Электронного правительства РФ мы столкнулись с проблемой проектирования централизованной системы логирования (протоколирования). ЦСЛ – это логирование для обработки прикладных и системных логов (событий) в едином хранилище. Прикладные логи из сервер-приложения (обращения гражданам к сервису через портал госуслуг), лог балансировки, нагрузки и шина интеграции протоколируют логи через лог сервера, попадают в хранилище, после этого данные индексируется и агрегируются для отчётности. Для формирования отчётности мы использовали систему BI. Ниже — концептуальная архитектура ЦСЛ:

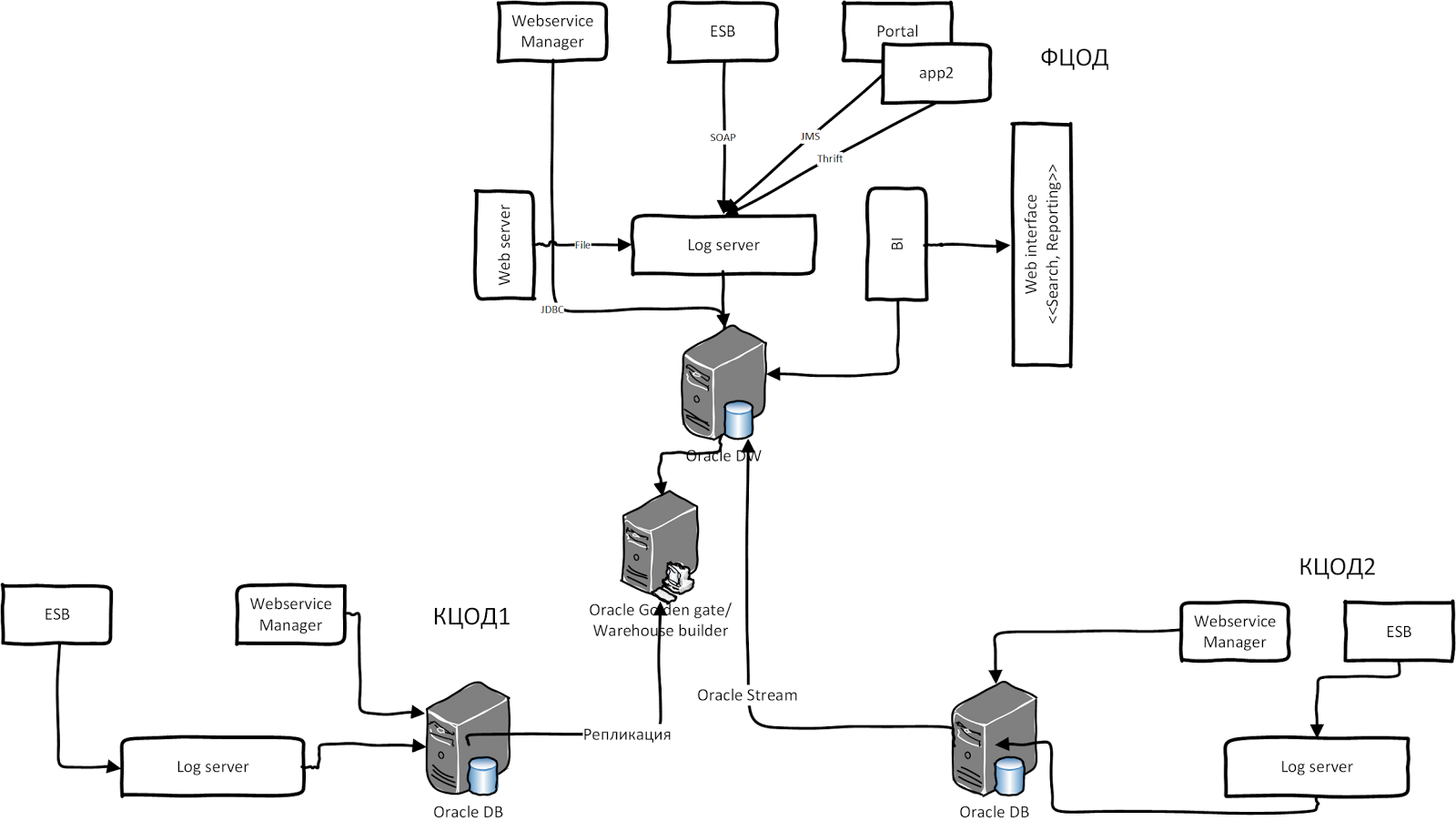
Ситуация усложняется, когда участвуют разные legacy гетерогенные системы со своим хранилищем и системой логирования. Одна из таких систем — СМЭВ (Система межведомственного электронного взаимодействия, архитектура 2011 г.). Она содержит два типа шин интеграции Oracle: WSM и Oracle OSB. Oracle WSM всегда протоколирует сообщения в виде BLOB в собственной схеме БД. Также OSB логирует сообщения в своей схеме, а у других ПО свой подход к логированию. Теперь представьте, что вся эта система устанавливается в нескольких регионах РФ. Данные реплицируется из других ЦОДов в федеральный ЦОД для обработки и агрегаций. После консолидации и агрегации результирующие данные попадают в отчёты через систему BI. В иллюстрации ниже приведена высокоуровневая архитектура СМЭВ 2.0:
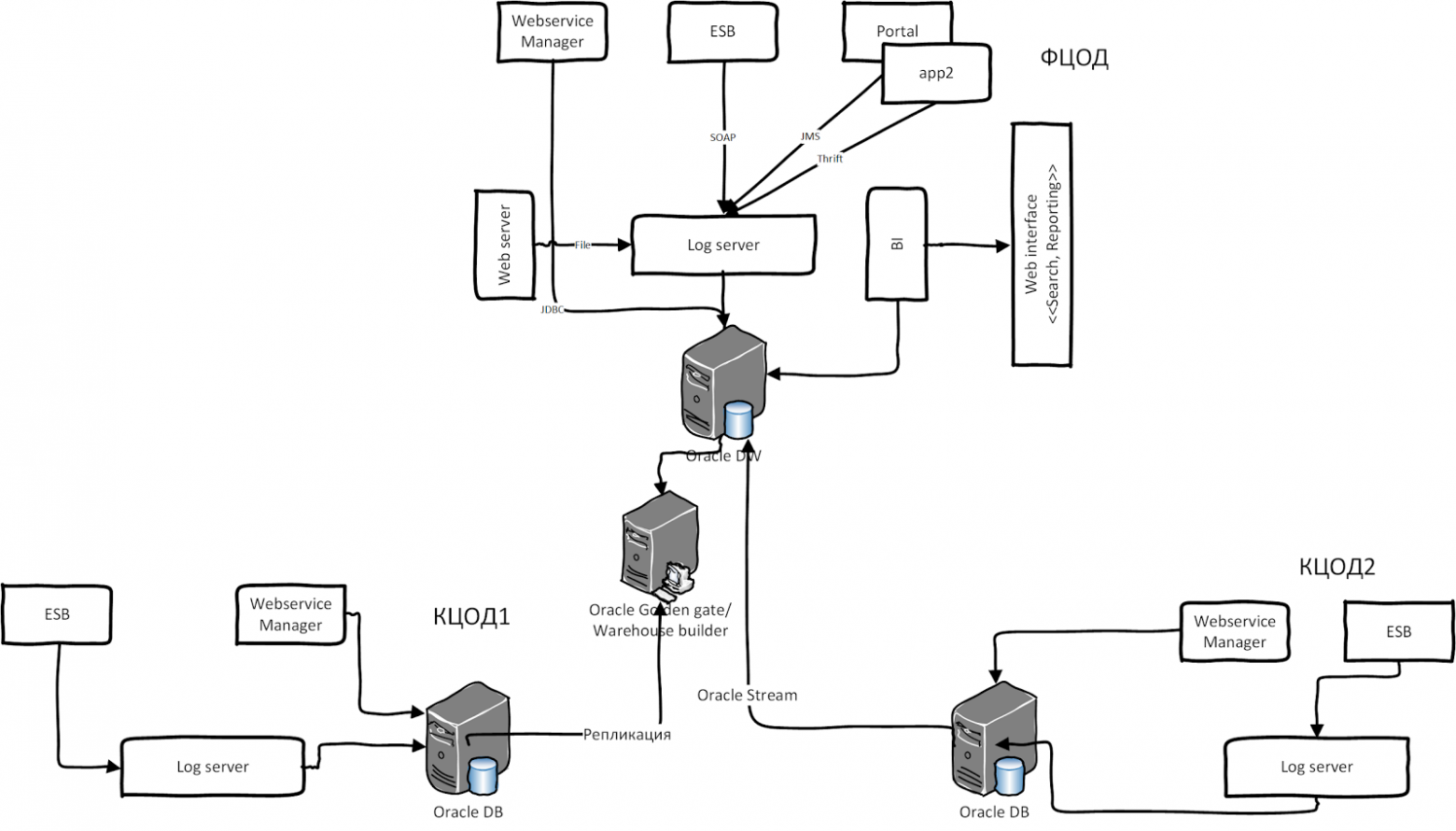
У этой системы был ряд недостатков:
Все эти причины сподвигли нас пересмотреть нашу архитектуру и перейти на NoSQL. После небольшого обсуждения и сравнительного анализа мы решили использовать хранилище Cassandra. Её плюсы были очевидными:
В итоге у нас получилось следующая концептуальная архитектура на базе Cassandra:
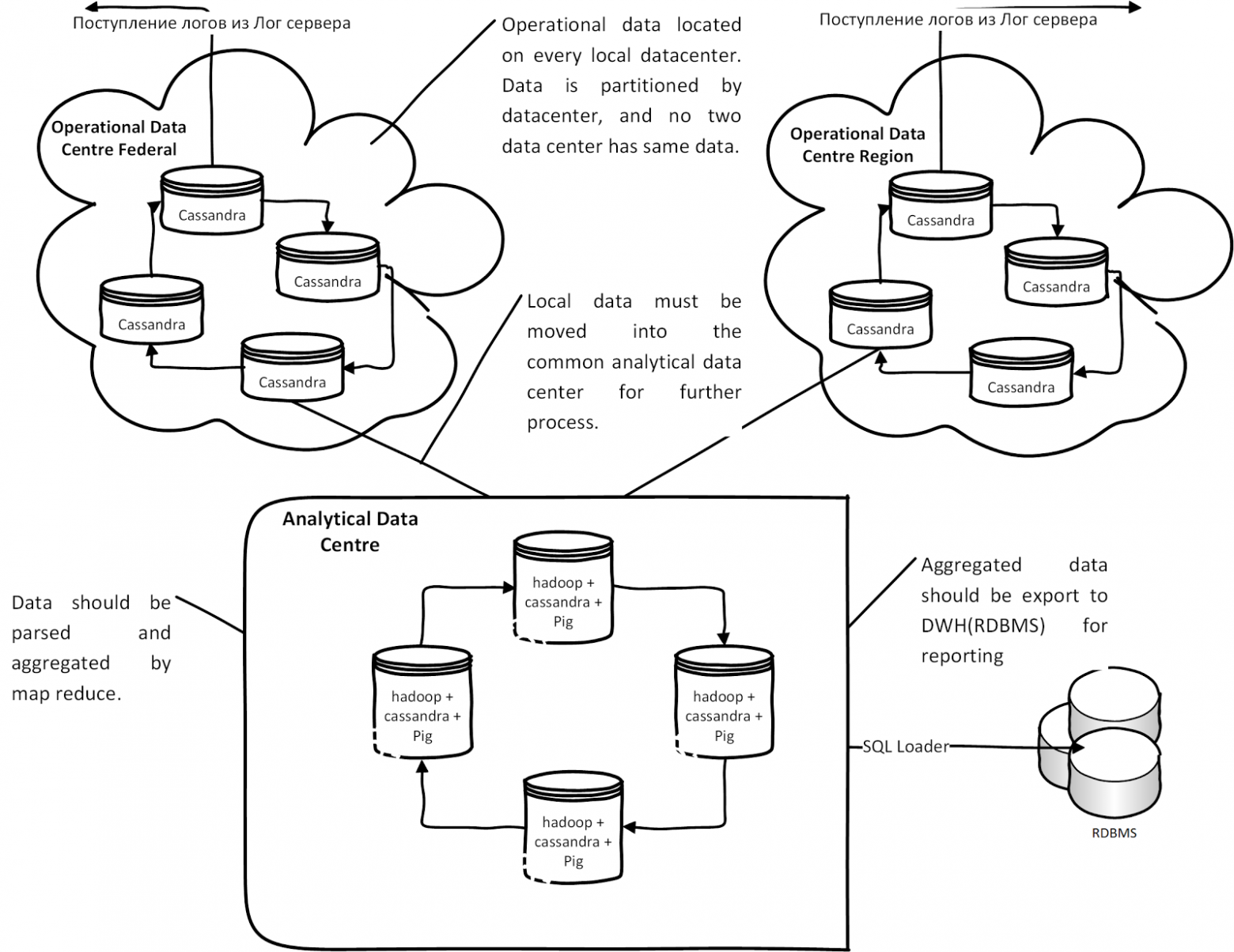
Каждый лог-сервер региона или ЦоД пишет протоколы в своём узле кластера Cassandra. Данные автоматически реплицируются в аналитическом центре для анализа. После анализа и обработки данных в Hadoop Map Reduce данные выгружаются через SQL loader для отчётности в Oracle. Если по каким-то причинам канал связи между аналитическими центрами и ЦоД отсутствует, данные накапливаются (Hinted hands of) в каждом операционном узле Cassandra и при появлении связи, данные из ЦоД попадают в аналитические узлы.
Модель данных — Column Family, состоящая из столбцов и значений. Все столбцы (column) статичные, потому что Pig не умел работать с динамическими столбцами: таким образом, у нас хранится полезная нагрузка soap payload в столбце. Через Hadoop Map Reduce проводится разбор сообщения, и результат сохраняется в таблице Cassandra для построения агрегата. После этого в результирующих метаданных запускается Reduce для построения разных агрегатов. Агрегированные данные экспортируется через Oracle SQL Loader из Hadoop HDFS в Oracle DB.
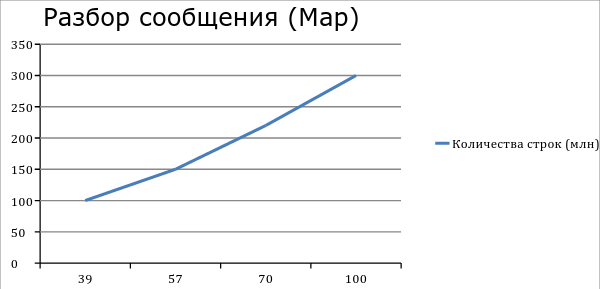
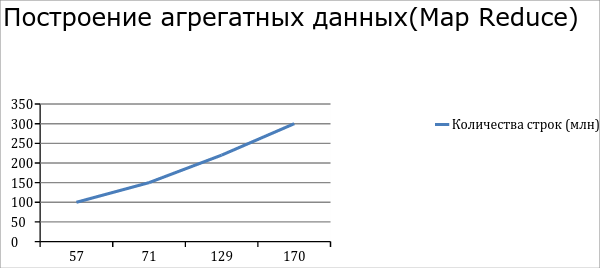
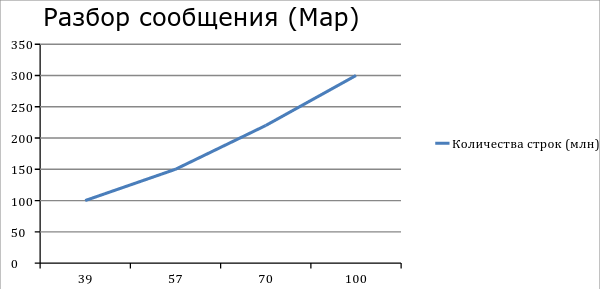
После настройки (fine tuning) Hadoop мы получили такие производительности. Разбор 300 млн строк из Cassandra занимает примерно 100 минут. Построение агрегата на 300 млн записей занимает в среднем 170 мин. Pig cкрипт агрегата данных в нашем случае содержит 3 крупных операторов join, поэтому появляется ещё 3 временных map.
При переходе очень важно понять data-модель и причину перехода. Реляционные базы данных до сих пор лидируют среди хранилищ данных, при помощи реляционной модели можно реализовать почти все домен-модели: например, мы перенесли только не транзакционные данные (прикладные и системные логи). Cassandra нам помогла решить проблему с репликацией между data-центрами, а Hadoop решил вопрос производительности обработки данных.
Ссылки:

В 2011 году в одном из флагманских проектов Электронного правительства РФ мы столкнулись с проблемой проектирования централизованной системы логирования (протоколирования). ЦСЛ – это логирование для обработки прикладных и системных логов (событий) в едином хранилище. Прикладные логи из сервер-приложения (обращения гражданам к сервису через портал госуслуг), лог балансировки, нагрузки и шина интеграции протоколируют логи через лог сервера, попадают в хранилище, после этого данные индексируется и агрегируются для отчётности. Для формирования отчётности мы использовали систему BI. Ниже — концептуальная архитектура ЦСЛ:
Ситуация усложняется, когда участвуют разные legacy гетерогенные системы со своим хранилищем и системой логирования. Одна из таких систем — СМЭВ (Система межведомственного электронного взаимодействия, архитектура 2011 г.). Она содержит два типа шин интеграции Oracle: WSM и Oracle OSB. Oracle WSM всегда протоколирует сообщения в виде BLOB в собственной схеме БД. Также OSB логирует сообщения в своей схеме, а у других ПО свой подход к логированию. Теперь представьте, что вся эта система устанавливается в нескольких регионах РФ. Данные реплицируется из других ЦОДов в федеральный ЦОД для обработки и агрегаций. После консолидации и агрегации результирующие данные попадают в отчёты через систему BI. В иллюстрации ниже приведена высокоуровневая архитектура СМЭВ 2.0:
У этой системы был ряд недостатков:
- Плохая масштабируемость: первой проблемой стала динамика роста регистраций и использование сервисов во всех органах власти. В начале 2011 года было зарегистрировано всего 4 000 сервисов, а уже во втором квартале 2013 года – более 10 000. В каждом ЦОДе были зарегистрированы примерно по 1 000 soap-сервисов в шине интеграции, а в федеральном ЦОДе — около 2 000 сервисов. Таким образом, потребность в сервисе выросла почти в 6 раз: на федеральном уровне количество логов достигало 21 млн в день, а по всей России – примерно 41 млн записей, в час-пик RPS (Request per second) — 1375. Конечно, по сравнению с высокой нагрузочной системой это крохотные цифры. Весь процесс обработки данных и отчётности реализован на основе PL/SQL, т.е. обработка сообщения и консолидация данных были реализованы на PL/SQL, которая не была достаточно производительной. После большого апдейта мы могли разобрать 450 тысяч сообщений за 110 минут, когда нам на вход поступало несколько миллионов сообщений в день.
- Второй сильно повлиявший фактор – это репликация данных между ЦОД, которая проводилась через разные гетерогенные инструменты: WHB, Oracle Goldengate, Oracle Stream. Если канал связи по каким-то причинам отсутствовал, их приходилось запускать повторно, чтобы избежать ошибок.
- Масштабирование Oracle RAC: также при увеличении роста потребности в сервисе, необходимо было масштабировать БД, что было очень дорого и сложно.
- Дорогостоящие лицензии на ПО Oracle.
Все эти причины сподвигли нас пересмотреть нашу архитектуру и перейти на NoSQL. После небольшого обсуждения и сравнительного анализа мы решили использовать хранилище Cassandra. Её плюсы были очевидными:
- Автоматическая репликация данных между датацентрами;
- Шардинг данных «из коробки»;
- Линейное масштабирование кластера Cassandra;
- Отсутствие единой точки отказа;
- модель данных на основе Google Big Table;
- СПО (open source).
В итоге у нас получилось следующая концептуальная архитектура на базе Cassandra:
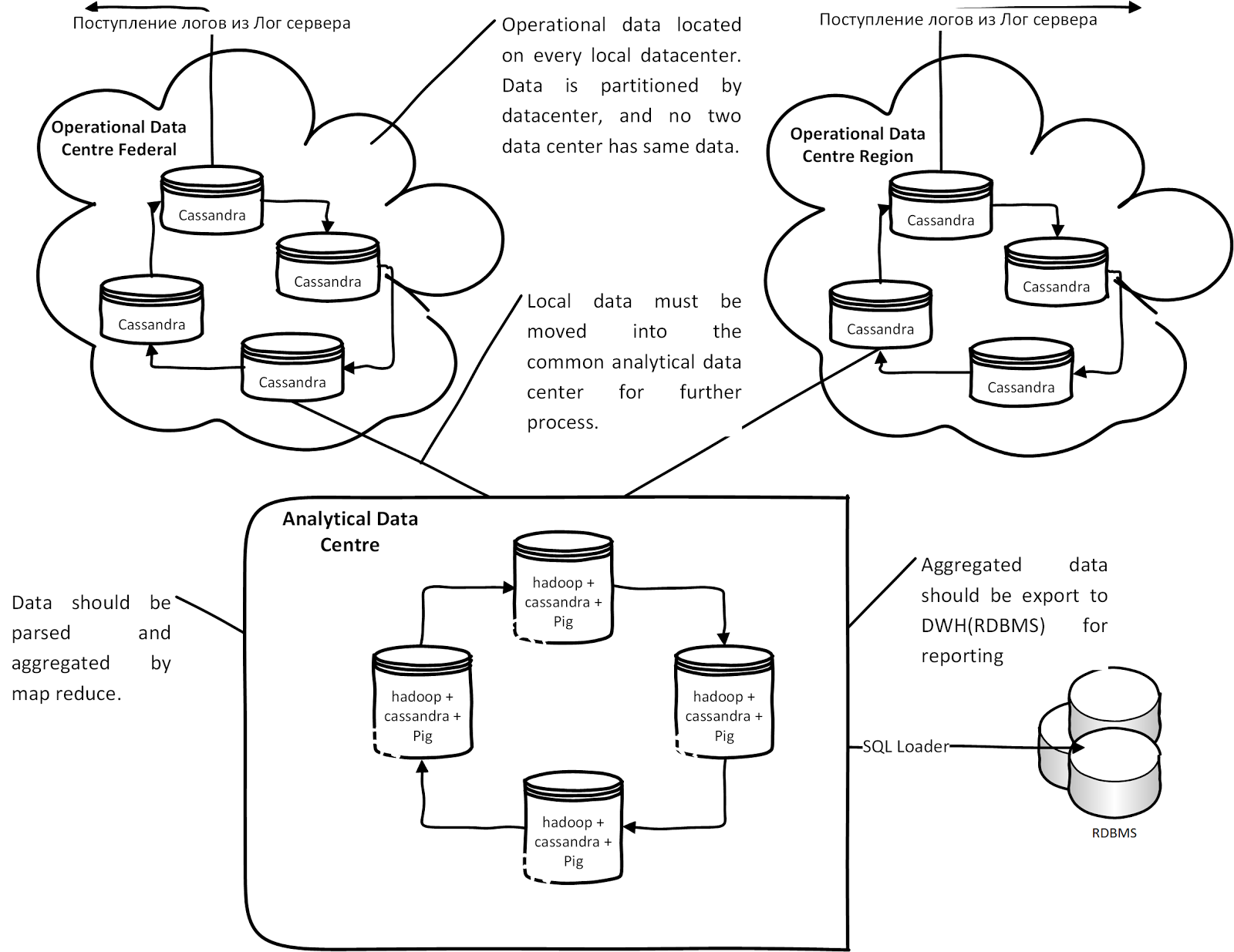
Каждый лог-сервер региона или ЦоД пишет протоколы в своём узле кластера Cassandra. Данные автоматически реплицируются в аналитическом центре для анализа. После анализа и обработки данных в Hadoop Map Reduce данные выгружаются через SQL loader для отчётности в Oracle. Если по каким-то причинам канал связи между аналитическими центрами и ЦоД отсутствует, данные накапливаются (Hinted hands of) в каждом операционном узле Cassandra и при появлении связи, данные из ЦоД попадают в аналитические узлы.
Стек ПО
- Cassandra 1.1.5
- Hadoop 1.0.3
- Apache pig 0.1.11
- AzKaban
Модель данных и их обработки
Модель данных — Column Family, состоящая из столбцов и значений. Все столбцы (column) статичные, потому что Pig не умел работать с динамическими столбцами: таким образом, у нас хранится полезная нагрузка soap payload в столбце. Через Hadoop Map Reduce проводится разбор сообщения, и результат сохраняется в таблице Cassandra для построения агрегата. После этого в результирующих метаданных запускается Reduce для построения разных агрегатов. Агрегированные данные экспортируется через Oracle SQL Loader из Hadoop HDFS в Oracle DB.
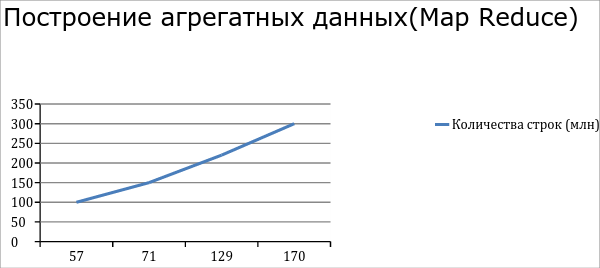
Производительность
После настройки (fine tuning) Hadoop мы получили такие производительности. Разбор 300 млн строк из Cassandra занимает примерно 100 минут. Построение агрегата на 300 млн записей занимает в среднем 170 мин. Pig cкрипт агрегата данных в нашем случае содержит 3 крупных операторов join, поэтому появляется ещё 3 временных map.
Итоги
При переходе очень важно понять data-модель и причину перехода. Реляционные базы данных до сих пор лидируют среди хранилищ данных, при помощи реляционной модели можно реализовать почти все домен-модели: например, мы перенесли только не транзакционные данные (прикладные и системные логи). Cassandra нам помогла решить проблему с репликацией между data-центрами, а Hadoop решил вопрос производительности обработки данных.
Ссылки:
