В данной статье я бы хотел рассказать о собственном опыте оптимизации выполнения множества регулярных выражений при помощи системы hyperscan. Так вышло, что при разработке своего спам-фильтра rspamd я столкнулся с необходимостью портировать большой объем старых правил, написанных для spamassassin за несколько лет работы. Моим первым решением было написать плагин, который бы читал эти правила и строил из них синтаксическое дерево. Затем на этом дереве выполнялись различные оптимизации, чтобы сократить общее время выполнения (об этом я даже делал небольшую презентацию).
К сожалению, в ходе эксплуатации выяснилось, что pcre все равно являются узким местом, и на больших письмах этот набор правил работает слишком медленно. Выяснилось, например, что на письме размером в мегабайт pcre проверяет около гигабайта (!) текста. Различные трюки, вроде ограничения количества текста для регулярных выражений, оказывали негативное влияние на срабатывания правил, а оптимизации pcre путем интенсивного использования jit fast path через pcre_jit_exec оказались слишком опасными — некоторые старые выражения были откровенно некорректными и в сочетании с некорректным входным текстом, например, содержащим «битые» UTF8 символы, приводили к воспроизводимым багам с повреждением стека программы. Однако на конференции highload мы поговорили со Вячеславом Ольховченковым, и он мне посоветовал посмотреть на hyperscan. Далее я перейду к сути и расскажу, что из этого получилось.
Hyperscan — это проект с достаточно длинной историей, и создавался он для продажи deep packets introspection (DPI) решений. Но в октябре уже прошлого года Intel решил открыть его исходный код, да еще и под BSD лицензией. Проект написан на C++ с достаточно интенсивным использованием boost'а, что вызывает определенные проблемы при портировании (но об этом далее). Внутри себя hyperscan представляет из себя non-backtracking движок регулярных выражений на базе недетерминированного конечного автомата (NFA). В принципе, все современнные движки регулярных выражений, ориентированных на производительность, написаны, используя ту же самую теорию и отказываясь от backtracking полностью (что, конечно же, вполне рационально, если хочется обеспечить линейную скорость поиска). Самой важной для меня «фишкой» hyperscan'а была возможность одновременного выполнения многих регулярных выражений над каким-то текстом. Наивный подход сделать то же самое в pcre — это попробовать объединить несколько выражений оператором | в этакую «колбасу»:
Hyperscan состоит из двух частей: компилятора и, собственно, движка. Компилятор — это очень большая часть библиотеки, которая умеет взять пачку выражений, составить для нее NFA и преобразовать этот NFA в ассемблерный код с использованием, например, векторных инструкций, в частности, AVX2. Эта задача трудная и ресурсозатратная, поэтому компилятор также позволяет сериализовать полученный код для его последующего использования. Движок поиска — это более маленькая библиотека, и она, собственно, предназначена для выполнения NFA на определенном тексте. Для приложений, которые используют только прекомпилированные наборы выражений, можно использовать отдельную библиотеку libhs_runtime, которая намного меньше объединенной библиотеки compiler+engine libhs. Для начала я попробовал собрать hyperscan, что оказалось довольно несложной задачей, если для системы есть достаточно свежий boost (минимальная версия 1.57). Единственным замечанием, пожалуй, является то, что при сборке с отладочными символами библиотека получается просто гигантской — около 200Mb на моем макбуке. А так как по умолчанию собирается только статическая библиотека, то при подключении ее размер бинарников также получается в районе 200Mb. Если отладочные символы не нужны, то лучше собирать hyperscan без них, указав
Затем я попробовал сравнить hyperscan и pcre, написав очень грубый прототип, который вы можете посмотреть под спойлером (предупреждаю — это код прототипа, который написан впопыхах без особых претензий к качеству).
Результат оказался довольно-таки впечатляющим: на мегабайтном спамерском письме и наборе из ~1000 регулярных выражений я получил следующие результаты:
Одной из самых впечатляющих возможностей hyperscan является возможность работы в качестве предварительного фильтра. Этот режим полезен, когда в выражении есть неподдерживаемые конструкции, например, тот же backtracking. В данном режиме hyperscan создает выражение, являющееся гарантированным надмножеством заданного неподдерживаемого выражения. То есть, новое выражение срабатывает гарантированно на всех случаях срабатыванния исходного, но может срабатывать и в других случаях, давая false positive срабатывания. Поэтому результат нужно проверять на традиционном движке регулярных выражений, например, pcre (хотя в этом случае не надо прогонять весь текст, а нужно проверить его от начала до точки вхождения предвыражения). Наглядно это представлено на следующей схеме:

К сожалению, выяснились и два неприятных момента. Первый из них заключается во времени компиляции — она занимает просто нереально долгое время в сравнении с pcre. Второй момент связан с тем, что некоторые выражения в ходе компиляции их в pre-filter просто зависают. Самым простым «крышесносным» выражением было, например, такое:
В итоге я сделал, что перед компиляцией выражений все pre-filter выражения вначале проверяются в отдельном форке процесса. И если выражение компилируется слишком долго, то этот процесс прибивается, а выражение помечается как безнадежное, то есть, для него всегда используется pcre. Таких выражений из 4-х тысяч нашлось около десятка. Все они пришли из горячо любимого мной spamassassin'а и являются достаточно характерными продуктами болезни под названием «perl головного мозга». После некоторого общения с инженерами Intel они исправили бесконечную компиляцию, но приведенный выше regexp все равно компилируется порядка минуты, что неприемлимо для практических целей.
Для работы hyperscan также оказалось нужным разбивать наборы выражений на так называемые «классы» — это тип входного текста, который проверяется через регулярные выражения из набора, например, заголовок письма с определенным именем или полное тело письма, или только текстовые части. Такие классы показаны на следующей схеме:
Для компиляции же я использовал следующий подход:
Такой подход позволил начать проверять почту сразу же после старта (при помощи pcre), а не ждать дорогой и долгой компиляции hyperscan'а, а по завершению компиляции сразу же перейти с pcre на hyperscan (что называется, не отходя от кассы). А использование наборов бит для проверенных и сработавших регулярных выражений позволяет также не нарушать при переключении работы уже запущенных в проверку писем.
В ходе работы rspamd+hyperscan я получил примерно такие результаты:
Было:
Стало:
Большее число regexps matched в версии hyperscan вызвано оптимизациями синтаксического дерева, которые выполняются для pcre, но бесполезны в случае hyperscan (т.к. проверяются все выражения одновременно).
Hyperscan версия уже работает в продакшене, и включена в новую версию rspamd. Я могу достаточно уверенно посоветовать hyperscan для критичных к производительности проектов для проверки регулярных выражений (DPI, прокси итд), а также для применений для поиска статических строк в тексте.
Для последней задачи я делал сравнение hyperscan с традиционно используемым для таких целей алгоритмом aho-corasick. Я сравнивал самую быструю известную мне имплементацию от Mischa Sandberg.
Результаты сравнения для 10 тысяч статических строк на мегабайтном письме c большим количеством таких строк (то есть, худшие возможные условия для aho-corasic, имеющего сложность O(M+N), где M — число найденных строк):
К сожалению, также выяснилось, что количество попаданий не сошлось из-за ошибки в ac-trie коде, в то время как hyperscan не ошибся ни разу.
Также материалы этой статьи доступны в презентации. Код же можно посмотреть в проекте rspamd на гитхабе
К сожалению, в ходе эксплуатации выяснилось, что pcre все равно являются узким местом, и на больших письмах этот набор правил работает слишком медленно. Выяснилось, например, что на письме размером в мегабайт pcre проверяет около гигабайта (!) текста. Различные трюки, вроде ограничения количества текста для регулярных выражений, оказывали негативное влияние на срабатывания правил, а оптимизации pcre путем интенсивного использования jit fast path через pcre_jit_exec оказались слишком опасными — некоторые старые выражения были откровенно некорректными и в сочетании с некорректным входным текстом, например, содержащим «битые» UTF8 символы, приводили к воспроизводимым багам с повреждением стека программы. Однако на конференции highload мы поговорили со Вячеславом Ольховченковым, и он мне посоветовал посмотреть на hyperscan. Далее я перейду к сути и расскажу, что из этого получилось.
Кратко о hyperscan
Hyperscan — это проект с достаточно длинной историей, и создавался он для продажи deep packets introspection (DPI) решений. Но в октябре уже прошлого года Intel решил открыть его исходный код, да еще и под BSD лицензией. Проект написан на C++ с достаточно интенсивным использованием boost'а, что вызывает определенные проблемы при портировании (но об этом далее). Внутри себя hyperscan представляет из себя non-backtracking движок регулярных выражений на базе недетерминированного конечного автомата (NFA). В принципе, все современнные движки регулярных выражений, ориентированных на производительность, написаны, используя ту же самую теорию и отказываясь от backtracking полностью (что, конечно же, вполне рационально, если хочется обеспечить линейную скорость поиска). Самой важной для меня «фишкой» hyperscan'а была возможность одновременного выполнения многих регулярных выражений над каким-то текстом. Наивный подход сделать то же самое в pcre — это попробовать объединить несколько выражений оператором | в этакую «колбасу»:
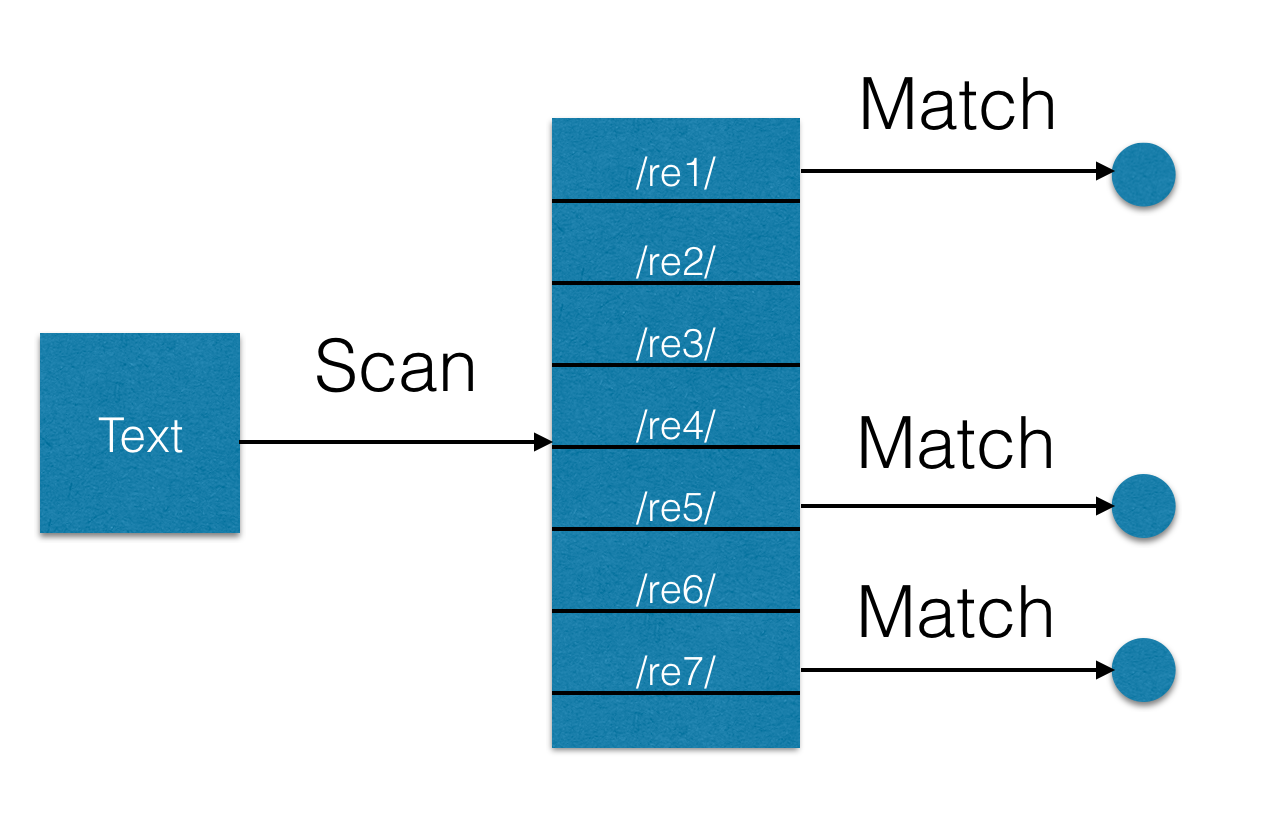
(?:re1)|(?:re2)|...|(?:reN). К сожалению, такой подход не сработает — ведь задача найти все вхождения из заданного набора выражений, а не только те, что сработали раньше. Hyperscan работает же не так — для каждого найденного выражения он вызывает callback функцию с позицией в тексте (правда, только последнего символа вхождения), что можно продемонстрировать на следующей схеме:
Архитектура hyperscan
Hyperscan состоит из двух частей: компилятора и, собственно, движка. Компилятор — это очень большая часть библиотеки, которая умеет взять пачку выражений, составить для нее NFA и преобразовать этот NFA в ассемблерный код с использованием, например, векторных инструкций, в частности, AVX2. Эта задача трудная и ресурсозатратная, поэтому компилятор также позволяет сериализовать полученный код для его последующего использования. Движок поиска — это более маленькая библиотека, и она, собственно, предназначена для выполнения NFA на определенном тексте. Для приложений, которые используют только прекомпилированные наборы выражений, можно использовать отдельную библиотеку libhs_runtime, которая намного меньше объединенной библиотеки compiler+engine libhs. Для начала я попробовал собрать hyperscan, что оказалось довольно несложной задачей, если для системы есть достаточно свежий boost (минимальная версия 1.57). Единственным замечанием, пожалуй, является то, что при сборке с отладочными символами библиотека получается просто гигантской — около 200Mb на моем макбуке. А так как по умолчанию собирается только статическая библиотека, то при подключении ее размер бинарников также получается в районе 200Mb. Если отладочные символы не нужны, то лучше собирать hyperscan без них, указав
-DCMAKE_BUILD_TYPE=MinSizeRelна этапе конфигурации через cmake.
Тестовый код
Затем я попробовал сравнить hyperscan и pcre, написав очень грубый прототип, который вы можете посмотреть под спойлером (предупреждаю — это код прототипа, который написан впопыхах без особых претензий к качеству).
Код сравнения pcre и hyperscan
#include <iostream> #include <string> #include <fstream> #include <vector> #include <stdexcept> #include <algorithm> #include <set> #include "pcre.h" #include "hs.h" #include <time.h> #ifdef __APPLE__ #include <mach/mach_time.h> #endif using namespace std; double get_ticks(void) { double res; #if defined(__APPLE__) res = mach_absolute_time() / 1000000000.; #else struct timespec ts; clock_gettime(CLOCK_MONOTONIC, &ts); res = (double)ts.tv_sec + ts.tv_nsec / 1000000000.; #endif return res; } struct pcre_regexp { pcre* re; pcre_extra* extra; pcre_regexp(const string& pattern) { const char* err; int err_off; re = pcre_compile(pattern.c_str(), PCRE_NEWLINE_ANYCRLF, &err, &err_off, NULL); if (re == NULL) { throw invalid_argument(string("cannot compile: '") + pattern + "' error: " + err + " at offset: " + to_string(err_off)); } extra = pcre_study(re, PCRE_STUDY_JIT_COMPILE, &err); if (extra == NULL) { throw invalid_argument(string("cannot study: '") + pattern + "' error: " + err + " at offset: " + to_string(err_off)); } } }; struct cb_context { set<int> approx_re; vector<pcre_regexp> pcre_vec; }; struct cb_data { struct cb_context* ctx; vector<int> matched; const std::string* str; }; bool remove_uncompileable(const string& s, int id, struct cb_context* ctx) { hs_compile_error_t* hs_errors; hs_database_t* hs_db; if (hs_compile(s.c_str(), HS_FLAG_ALLOWEMPTY, HS_MODE_BLOCK, NULL, &hs_db, &hs_errors) != HS_SUCCESS) { cout << "pattern: '" << s << "', error: " << hs_errors->message << endl; if (hs_compile(s.c_str(), HS_FLAG_ALLOWEMPTY | HS_FLAG_PREFILTER, HS_MODE_BLOCK, NULL, &hs_db, &hs_errors) != HS_SUCCESS) { cout << "completely bad pattern: '" << s << "', error: " << hs_errors->message << endl; return true; } else { ctx->approx_re.insert(id); } } else { hs_free_database(hs_db); } return false; } int match_cb(unsigned int id, unsigned long long from, unsigned long long to, unsigned int flags, void* context) { auto cbdata = (struct cb_data*)context; auto& matched = cbdata->matched; if (cbdata->ctx->approx_re.find(id) != cbdata->ctx->approx_re.end()) { int ovec[3]; auto re = cbdata->ctx->pcre_vec[id]; auto* begin = cbdata->str->data(); auto* p = begin; auto sz = cbdata->str->size(); while (pcre_exec(re.re, re.extra, p, sz - (p - begin), 0, 0, ovec, 3) > 0) { p = p + ovec[1]; matched[id]++; } } else { matched[id]++; } return 0; } int main(int argc, char** argv) { ifstream refile(argv[1]); vector<string> re_vec; double t1, t2, total_ticks = 0; struct cb_context ctx; int ls; pcre_config(PCRE_CONFIG_LINK_SIZE, &ls); cout << ls << endl; for (std::string line; std::getline(refile, line);) { re_vec.push_back(line); } string re_pipe; const char** pats = new const char*[re_vec.size()]; unsigned int i = 0, *ids = new unsigned int[re_vec.size()]; //re_vec.erase(remove_if(re_vec.begin(), re_vec.end(), remove_uncompileable), re_vec.end()); for (i = 0; i < re_vec.size(); i++) { const auto& r = re_vec[i]; remove_uncompileable(r, i, &ctx); pats[i] = r.c_str(); ids[i] = i; re_pipe = re_pipe + string("(") + r + string(")|"); } // Last | re_pipe.erase(re_pipe.size() - 1); total_ticks = 0; for (const auto& r : re_vec) { t1 = get_ticks(); ctx.pcre_vec.emplace_back(r); t2 = get_ticks(); total_ticks += t2 - t1; } cout << "PCRE compile time: " << total_ticks << endl; ifstream input(argv[2]); std::string in_str((std::istreambuf_iterator<char>(input)), std::istreambuf_iterator<char>()); hs_compile_error_t* hs_errors; hs_database_t* hs_db; hs_platform_info_t plt; hs_populate_platform(&plt); unsigned int* flags = new unsigned int[re_vec.size()]; for (i = 0; i < re_vec.size(); i++) { if (ctx.approx_re.find(i) != ctx.approx_re.end()) { flags[i] = HS_FLAG_PREFILTER; } else { flags[i] = 0; } } t1 = get_ticks(); if (hs_compile_multi(pats, flags, ids, re_vec.size(), HS_MODE_BLOCK, &plt, &hs_db, &hs_errors) != HS_SUCCESS) { cout << "BAD pattern: '" << re_vec[hs_errors->expression] << "', error: " << hs_errors->message << endl; return -101; } t2 = get_ticks(); cout << "Hyperscan compile time: " << (t2 - t1) << "; approx re: " << ctx.approx_re.size() << "; total re: " << re_vec.size() << endl; char* bytes = NULL; size_t bytes_len; t1 = get_ticks(); if (hs_serialize_database(hs_db, &bytes, &bytes_len) != HS_SUCCESS) { cout << "BAD" << endl; return -101; } t2 = get_ticks(); cout << "Hyperscan serialize time: " << (t2 - t1) << "; size: " << bytes_len << " bytes" << endl; hs_database_t* hs_db1 = NULL; t1 = get_ticks(); if (hs_deserialize_database(bytes, bytes_len, &hs_db1) != HS_SUCCESS) { cout << "BAD1" << endl; return -101; } t2 = get_ticks(); cout << "Hyperscan deserialize time: " << (t2 - t1) << "; size: " << bytes_len << " bytes" << endl; auto matches = 0; total_ticks = 0; for (const auto& re : ctx.pcre_vec) { int ovec[3]; auto* begin = in_str.data(); auto* p = begin; auto sz = in_str.size(); t1 = get_ticks(); while (pcre_exec(re.re, re.extra, p, sz - (p - begin), 0, 0, ovec, 3) > 0) { p = p + ovec[1]; matches++; } t2 = get_ticks(); total_ticks += t2 - t1; } //cout << re_pipe << endl; cout << "Time for individual re: " << total_ticks << "; matches: " << matches << endl; //cout << "Time for piped re: " << (t2 - t1) << endl; hs_scratch_t* scratch = NULL; int rc; if ((rc = hs_alloc_scratch(hs_db1, &scratch)) != HS_SUCCESS) { cout << "bad scratch: " << rc << endl; return -102; } struct cb_data cbdata; cbdata.ctx = &ctx; cbdata.matched = vector<int>(re_vec.size(), 0); cbdata.str = &in_str; t1 = get_ticks(); if ((rc = hs_scan(hs_db1, in_str.data(), in_str.size(), 0, scratch, match_cb, &cbdata)) != HS_SUCCESS) { cout << "bad scan: " << rc << endl; return -103; } t2 = get_ticks(); matches = 0; for_each(cbdata.matched.begin(), cbdata.matched.end(), [&matches](int elt) { matches += elt; }); cout << "Time for hyperscan re: " << (t2 - t1) << "; matches: " << matches << endl; return 0; }
Результат оказался довольно-таки впечатляющим: на мегабайтном спамерском письме и наборе из ~1000 регулярных выражений я получил следующие результаты:
PCRE compile time: 0.0138553 Hyperscan compile time: 4.94309; approx re: 191; total re: 971 Hyperscan serialize time: 0.00312218; size: 5242956 bytes Hyperscan deserialize time: 0.00359501; size: 5242956 bytes Time for individual re: 0.440707; matches: 7 Time for hyperscan re: 0.0770988; matches: 7
Предварительный фильтр
Одной из самых впечатляющих возможностей hyperscan является возможность работы в качестве предварительного фильтра. Этот режим полезен, когда в выражении есть неподдерживаемые конструкции, например, тот же backtracking. В данном режиме hyperscan создает выражение, являющееся гарантированным надмножеством заданного неподдерживаемого выражения. То есть, новое выражение срабатывает гарантированно на всех случаях срабатыванния исходного, но может срабатывать и в других случаях, давая false positive срабатывания. Поэтому результат нужно проверять на традиционном движке регулярных выражений, например, pcre (хотя в этом случае не надо прогонять весь текст, а нужно проверить его от начала до точки вхождения предвыражения). Наглядно это представлено на следующей схеме:
Проблемы компиляции
К сожалению, выяснились и два неприятных момента. Первый из них заключается во времени компиляции — она занимает просто нереально долгое время в сравнении с pcre. Второй момент связан с тем, что некоторые выражения в ходе компиляции их в pre-filter просто зависают. Самым простым «крышесносным» выражением было, например, такое:
<a\s[^>]{0,2048}\bhref=(?:3D)?.?(https?:[^>"'\# ]{8,29}[^>"'\#:\/?&=])[^>]{0,2048}>(?:[^<]{0,1024}<(?!\/a)[^>]{1,1024}>){0,99}\s{0,10}(?!\1)https?[^\w<]{1,3}[^<]{5}
В итоге я сделал, что перед компиляцией выражений все pre-filter выражения вначале проверяются в отдельном форке процесса. И если выражение компилируется слишком долго, то этот процесс прибивается, а выражение помечается как безнадежное, то есть, для него всегда используется pcre. Таких выражений из 4-х тысяч нашлось около десятка. Все они пришли из горячо любимого мной spamassassin'а и являются достаточно характерными продуктами болезни под названием «perl головного мозга». После некоторого общения с инженерами Intel они исправили бесконечную компиляцию, но приведенный выше regexp все равно компилируется порядка минуты, что неприемлимо для практических целей.
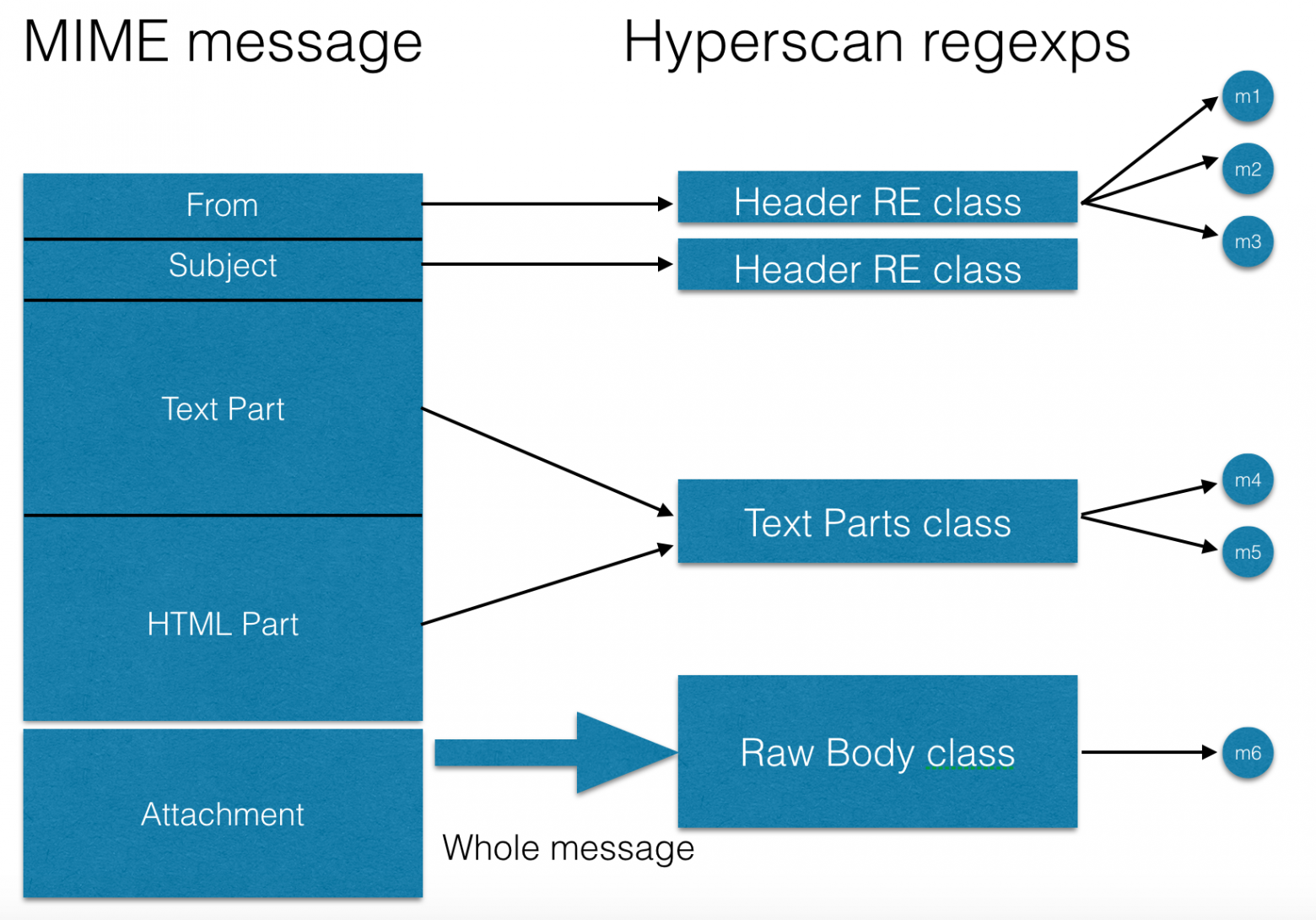
Для работы hyperscan также оказалось нужным разбивать наборы выражений на так называемые «классы» — это тип входного текста, который проверяется через регулярные выражения из набора, например, заголовок письма с определенным именем или полное тело письма, или только текстовые части. Такие классы показаны на следующей схеме:
Для компиляции же я использовал следующий подход:
- В отдельном процессе запустить проверку классов выражений, и для каждого класса искать, нет ли уже скомпилированного и валидного файла для него.
- Если такого файла нет или же он содержит неверный набор выражений (проверяется по хешу от паттерна выражения), то скомпилировать его, проверяя время компиляции предварительных фильтров.
- Когда все выражения скомпилированы в кеше, то послать всем процессам сканерам сообщение, получив которое сканеры загружают кешированные выражения и переключаются с pcre на hyperscan.
Такой подход позволил начать проверять почту сразу же после старта (при помощи pcre), а не ждать дорогой и долгой компиляции hyperscan'а, а по завершению компиляции сразу же перейти с pcre на hyperscan (что называется, не отходя от кассы). А использование наборов бит для проверенных и сработавших регулярных выражений позволяет также не нарушать при переключении работы уже запущенных в проверку писем.
Выводы
В ходе работы rspamd+hyperscan я получил примерно такие результаты:
Было:
len: 610591, time: 2492.457ms real, 882.251ms virtual regexp statistics: 4095 pcre regexps scanned, 18 regexps matched, 694M bytes scanned using pcre
Стало:
len: 610591, time: 654.596ms real, 309.785ms virtual regexp statistics: 34 pcre regexps scanned, 41 regexps matched, 8.41M bytes scanned using pcre, 9.56M bytes scanned total
Большее число regexps matched в версии hyperscan вызвано оптимизациями синтаксического дерева, которые выполняются для pcre, но бесполезны в случае hyperscan (т.к. проверяются все выражения одновременно).
Hyperscan версия уже работает в продакшене, и включена в новую версию rspamd. Я могу достаточно уверенно посоветовать hyperscan для критичных к производительности проектов для проверки регулярных выражений (DPI, прокси итд), а также для применений для поиска статических строк в тексте.
Для последней задачи я делал сравнение hyperscan с традиционно используемым для таких целей алгоритмом aho-corasick. Я сравнивал самую быструю известную мне имплементацию от Mischa Sandberg.
Результаты сравнения для 10 тысяч статических строк на мегабайтном письме c большим количеством таких строк (то есть, худшие возможные условия для aho-corasic, имеющего сложность O(M+N), где M — число найденных строк):
actrie compile time: 0.0743811 Hyperscan compile time: 0.1547; approx re: 0; total re: 7400 Hyperscan serialize time: 0.000178297; size: 1250856 bytes Hyperscan deserialize time: 0.000312379; size: 1250856 bytes Time for hyperscan re: 0.117938; matches: 3001024 Time for actrie: 0.100427; matches: 3000144
К сожалению, также выяснилось, что количество попаданий не сошлось из-за ошибки в ac-trie коде, в то время как hyperscan не ошибся ни разу.
Также материалы этой статьи доступны в презентации. Код же можно посмотреть в проекте rspamd на гитхабе

