Поговорим о горизонтальном масштабировании. Допустим, ваш проект вырос до размеров, когда один сервер не справляется с нагрузкой, а возможностей для вертикального роста ресурсов уже нет.
В этом случае дальнейшее развитие инфраструктуры проекта обычно происходит за счет увеличения числа однотипных серверов с распределением нагрузки между ними. Такой подход не только позволяет решить проблему с ресурсами, но и добавляет надежности проекту — при выходе из строя одного или нескольких компонентов его работоспособность в целом не будет нарушена.
Большую роль в этой схеме играет балансировщик — система, которая занимается распределением запросов/трафика. На этапе ее проектирования важно предусмотреть следующие ключевые требования:
- Отказоустойчивость. Нужно как минимум два сервера, которые одновременно занимаются задачей распределения запросов/трафика. Без явного разделения ролей на ведущего и резервного.
- Масштабирование. Добавление новых серверов в систему должно давать пропорциональную прибавку в ресурсах.
Фактически, это описание кластера, узлами которого являются серверы-балансеры.
В этой статье мы хотим поделиться рецептом подобного кластера, простого и неприхотливого к ресурсам, концепцию которого успешно применяем в собственной инфраструктуре для балансировки запросов к серверам нашей панели управления, внутреннему DNS серверу, кластеру Galera и разнообразными микросервисам.
Договоримся о терминах:
— Серверы, входящие в состав кластера, будем называть узлами или балансерами.
— Конечными серверами будем называть хосты, на которые проксируется трафик через кластер.
— Виртуальным IP будем называть адрес, “плавающий” между всеми узлами, и на который должны указывать имена сервисов в DNS.
Что потребуется:
— Для настройки кластера потребуется как минимум два сервера (или вирт.машины) с двумя сетевыми интерфейсами на каждом.
— Первый интерфейс будет использоваться для связи с внешним миром. Здесь будут настроены реальный и виртуальный IP адреса.
— Второй интерфейс будет использоваться под служебный трафик, для общения узлов друг с другом. Здесь будет настроен адрес из приватной (“серой”) сети 172.16.0.0/24.
Вторые интерфейсы каждого из узлов должны находиться в одном сегменте сети.
Используемые технологии:
VRRP, Virtual Router Redundancy Protocol — в контексте этой статьи, реализация "плавающего" между узлами кластера виртуального IP адреса. В один момент времени такой адрес может быть поднят на каком-то одном узле, именуемом MASTER. Второй узел называется BACKUP. Оба узла постоянно обмениваются специальными heartbeat сообщениями. Получение или неполучение таких сообщений в рамках заданных промежутков дает основания для переназначения виртуального IP на “живой” сервер. Более подробно о протоколе можно прочитать здесь.
LVS, Linux Virtual Server — механизм балансировки на транспортном/сеансовом уровне, встроенный в ядро Linux в виде модуля IPVS. Хорошее описание возможностей LVS можно найти здесь и здесь.
Суть работы сводится к указанию того, что есть определенная пара “IP + порт” и она является виртуальным сервером. Для этой пары назначаются адреса реальных серверов, ответственных за обработку запросов, задается алгоритм балансировки, а также режим перенаправления запросов.
В нашей системе мы будем использовать Nginx как промежуточное звено между LVS и конечными серверами, на которые нужно проксировать трафик. Nginx будет присутствовать на каждом узле.
Для настроек VRRP и взаимодействия с IPVS будем использовать демон Keepalived, написанный в рамках проекта Linux Virtual Server.
КОНЦЕПЦИЯ
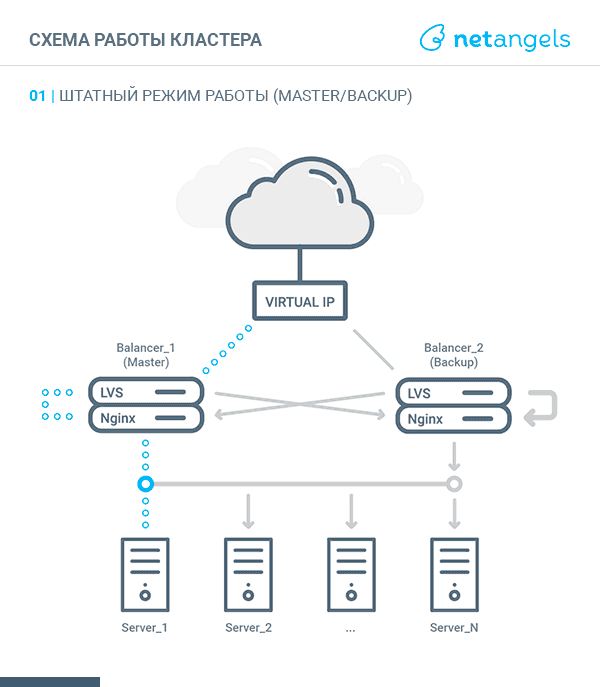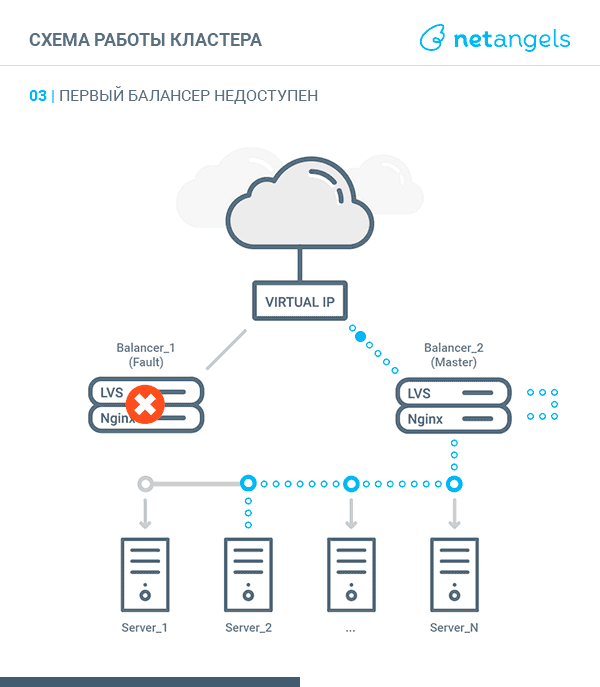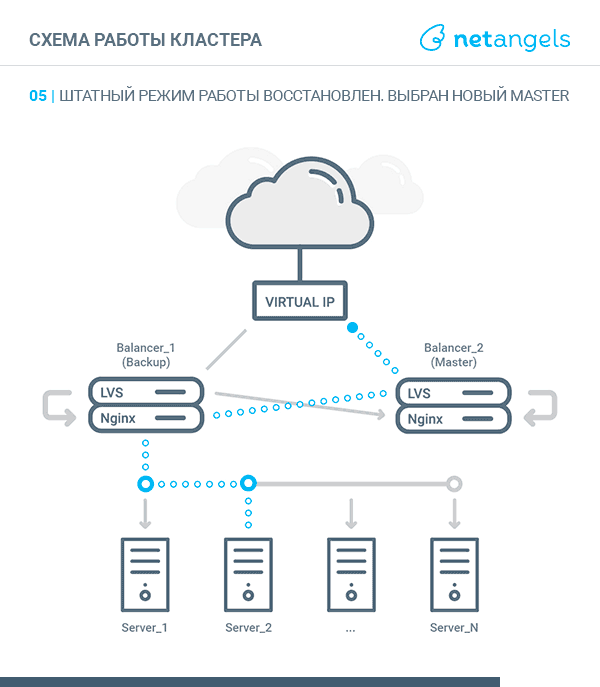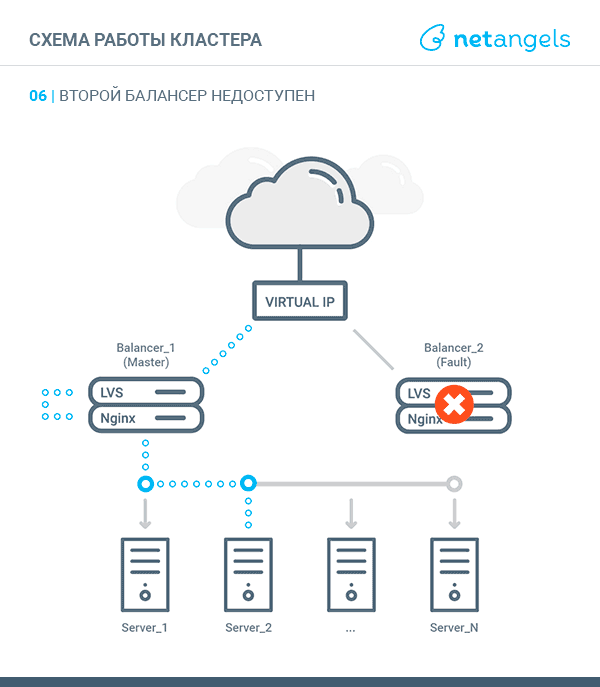
Система будет представлять собой связку из двух независимых друг от друга равнозначных узлов-балансеров, объединенных в кластер средствами технологии LVS и протокола VRRP.
Точкой входа для трафика будет являться виртуальный IP адрес, поднятый либо на одном, либо на втором узле.
Поступающие запросы LVS перенаправляет к одному из запущенных экземпляров Nginx — локальному или на соседнем узле. Такой подход позволяет равномерно размазывать запросы между всеми узлами кластера, т.е. более оптимально использовать ресурсы каждого балансера.
Работа Nginx заключается в проксировании запросов на конечные сервера. Начиная с версии 1.9.13 доступны функции проксирования на уровне транспортных протоколов tcp и udp.
Каждый vhost/stream будет настроен принимать запросы как через служебный интерфейс с соседнего балансера так и поступающие на виртуальный IP. Причем даже в том случае, если виртуальный IP адрес физически не поднят на данном балансере (Keepalived назначил серверу роль BACKUP).
Таким образом, схема хождения трафика в зависимости от состояния балансера (MASTER или BACKUP) выглядит так:
MASTER:
- запрос приходит на виртуальный IP. IPVS маршрутизирует пакет на локальный сервер;
- поскольку локальный Nginx слушает в том числе виртуальный IP, он получает запрос;
- согласно настройкам проксирования для данного виртуального IP Nginx отправляет запрос одному из перечисленных апстримов;
- полученный ответ отправляется клиенту.
BACKUP:
- запрос приходит на виртуальный IP. IPVS маршрутизирует пакет на соседний сервер;
- на соседнем балансере этот виртуальный IP не поднят. Поэтому dst_ip в пакете нужно заменить на соответствующий серый IP из сети текущего балансера. Для этого используется DNAT;
- после этого локальный Nginx получает запрос на серый IP адрес;
- согласно настройкам проксирования для данного виртуального IP Nginx отправляет запрос одному из перечисленных апстримов;
- полученный ответ отправляется клиенту напрямую с src_ip равным виртуальному IP (при участии conntrack)
РЕАЛИЗАЦИЯ:
В качестве операционной системы будем использовать Debian Jessie с подключенными backports репозиториями.
Установим на каждый узел-балансер пакеты с необходимым для работы кластера ПО и сделаем несколько общесистемных настроек:
apt-get update
apt-get install -t jessie-backports nginx
apt-get install keepalived ipvsadmНа интерфейсе eth1 настроим адреса из серой сети 172.16.0.0/24:
allow-hotplug eth1
iface eth1 inet static
address 172.16.0.1 # На втором балансере -- 172.16.0.2
netmask 255.255.255.0Виртуальный IP адрес прописывать на интерфейсе eth0 не нужно. Это сделает Keepalived.
В файл /etc/sysctl.d/local.conf добавим следующие директивы:
net.ipv4.ip_nonlocal_bind = 1
net.ipv4.vs.drop_entry = 1
net.nf_conntrack_max = 4194304Первая включает возможность слушать IP, которые не подняты локально (это нужно для работы Nginx). Вторая включает автоматическую защиту от DDoS на уровне балансировщика IPVS (при нехватке памяти под таблицу сессий начнётся автоматическое вычищение некоторых записей). Третья увеличивает размер conntrack таблицы.
В /etc/modules включаем загрузку модуля IPVS при старте системы:
ip_vs conn_tab_bits=18Параметр conn_tab_bits определяет размер таблицы с соединениями. Его значение является степенью двойки. Максимально допустимое значение — 20.
Кстати, если модуль не будет загружен до старта Keepalived, последний начинает сегфолтиться.
Теперь перезагрузим оба узла-балансера. Так мы убедимся, что при старте вся конфигурация корректно поднимется.
Общие настройки выполнены. Дальнейшие действия будем выполнять в контексте двух задач:
- Балансировка http трафика между тремя веб-серверами;
- Балансировка udp трафика на 53 порт двух DNS серверов.
Вводные данные:
- В качестве виртуального IP адреса будем использовать
192.168.0.100; - У веб-серверов будут адреса
192.168.0.101,192.168.0.102и192.168.0.103соответственно их порядковым номерам; - У DNS серверов
192.168.0.201и192.168.0.202.
Начнем с конфигурации Nginx.
Добавим описание секции stream в /etc/nginx/nginx.conf:
stream {
include /etc/nginx/stream-enabled/*;
}И создадим соответствующий каталог:
mkdir /etc/nginx/stream-enabledНастройки для веб-серверов добавим в файл /etc/nginx/sites-enabled/web_servers.conf
upstream web_servers {
server 192.168.0.101:80;
server 192.168.0.102:80;
server 192.168.0.103:80;
}
server {
listen 172.16.0.1:80 default_server; # На втором балансере -- 172.16.0.2
listen 192.168.0.100:80 default_server;
location / {
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_pass http://web_servers;
proxy_redirect default;
}
}Настройки для DNS-серверов добавим в файл /etc/nginx/stream-enabled/dns_servers.conf
upstream dns_servers {
server 192.168.0.201:53;
server 192.168.0.202:53;
}
server {
listen 172.16.0.1:53 udp reuseport; # На втором балансере -- 172.16.0.2
listen 192.168.0.100:53 udp reuseport;
proxy_pass dns_servers;
}Далее остается сконфигурировать Keepalived (VRRP + LVS). Это немного сложнее, поскольку нам потребуется написать специальный скрипт, который будет запускаться при переходе узла-балансера между состояниями MASTER/BACKUP.
Все настройки Keepalived должны находиться в одном файле — /etc/keepalived/keepalived.conf. Поэтому все нижеследующие блоки с конфигурациями VRRP и LVS нужно последовательно сохранить в этом файле.
Настройки VRRP:
vrrp_instance 192.168.0.100 {
interface eth1 # Интерфейс на котором будет работать VRRP
track_interface { # Если на одном из этих интерфейсов пропадет линк или
eth0 # он будет выключен, балансер перейдет в состояние
eth1 # FAULT, т.е. с него будет удален виртуальный IP и
# все настройки LVS
}
virtual_router_id 1 # Должен совпадать на обоих узлах
nopreempt # Не менять роль текущего балансера на BACKUP
# если в сети появился сосед с более высоким приоритетом
priority 102 # Приоритет. Может отличаться на разных узлах
authentication {
auth_type PASS
auth_pass secret # Здесь нужно установить свой пароль
}
virtual_ipaddress {
192.168.0.100/24 dev eth0
}
notify /usr/local/bin/nat-switch
}Скрипт, который упоминался выше — /usr/local/bin/nat-switch. Он запускается каждый раз, когда у текущего VRRP инстанса меняется состояние. Его задача заключается в том, чтобы балансер, находящийся в состоянии BACKUP, умел корректно обработать пакеты, адресованные на виртуальный IP. Для решения этой ситуации используются возможности DNAT. А именно, правило вида:
-A PREROUTING -d 192.168.0.100/32 -i eth1 -j DNAT --to-destination ${IP_on_eth1}При переходе в состояние MASTER, скрипт удаляет это правило.
Здесь можно найти вариант скрипта nat-switch, написанный для данного примера.
Настройки LVS для группы веб-серверов:
virtual_server 192.168.0.100 80 {
lb_algo wlc # Алгоритм балансировки
# wlc -- больше запросов к серверам с меньшим кол-вом
# активных соединений.
lb_kind DR # Режимы перенаправления запросов. Direct routing
protocol TCP
delay_loop 6 # Интервал между запусками healthchecker'а
real_server 172.16.0.1 80 {
weight 1
TCP_CHECK { # Простая проверка доступности локального
connect_timeout 2 # и соседнего экземпляров Nginx
}
}
real_server 172.16.0.2 80 {
weight 1
TCP_CHECK {
connect_timeout 2
}
}
}Настройки LVS для группы DNS-серверов:
virtual_server 192.168.0.100 53 {
lb_algo wlc
lb_kind DR
protocol UDP
delay_loop 6
real_server 172.16.0.1 53 {
weight 1
MISC_CHECK {
connect_timeout 2
misc_path "/bin/nc -zn -u 172.16.0.1 53"
}
}
real_server 172.16.0.2 53 {
weight 1
MISC_CHECK {
connect_timeout 2
misc_path "/bin/nc -zn -u 172.16.0.2 53"
}
}
}В завершении перезагрузим конфигурацию Nginx и Keepalived:
nginx -s reload && /etc/init.d/keepalived reloadТЕСТИРОВАНИЕ:
Посмотрим как балансировщик распределяет запросы к конечным серверам. Для этого на каждом из веб-серверов создадим index.php с каким-нибудь простым содержимым:
<?php
sleep(rand(2, 8));
echo("Hello from ".gethostname()." !");
?>И сделаем несколько запросов по http к виртуальному IP 192.168.0.100 :
for i in $(seq 10); do
printf 'GET / HTTP/1.0\n\n\n' | nc 192.168.0.100 80 | grep Hello
doneРезультат:
Hello from server-1 !
Hello from server-2 !
Hello from server-2 !
Hello from server-3 !
Hello from server-3 !
Hello from server-1 !
Hello from server-1 !
Hello from server-2 !
Hello from server-2 !
Hello from server-3 !Если в процессе выполнения этого цикла посмотреть на статистику работы LVS (на MASTER узле), то мы можем увидеть следующую картину:
ipvsadm -LnРезультат:
IP Virtual Server version 1.2.1 (size=262144)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 192.168.0.100:80 wlc
-> 172.16.0.1:80 Route 1 1 3
-> 172.16.0.2:80 Route 1 1 3
UDP 192.168.0.100:53 wlc
-> 172.16.0.1:53 Route 1 0 0
-> 172.16.0.2:53 Route 1 0 0 Здесь видно как происходит распределение запросов между узлами кластера: есть два активных соединения, которые обрабатываются в данный момент и 6 уже обработанных соединений.
Статистику по все соединениям, проходящим через LVS, можно посмотреть так:
ipvsadm -LncРезультат:
IPVS connection entries
pro expire state source virtual destination
TCP 14:57 ESTABLISHED 192.168.0.254:59474 192.168.0.100:80 172.16.0.1:80
TCP 01:49 FIN_WAIT 192.168.0.254:59464 192.168.0.100:80 172.16.0.1:80
TCP 01:43 FIN_WAIT 192.168.0.254:59462 192.168.0.100:80 172.16.0.1:80
TCP 14:59 ESTABLISHED 192.168.0.254:59476 192.168.0.100:80 172.16.0.2:80
TCP 01:56 FIN_WAIT 192.168.0.254:59468 192.168.0.100:80 172.16.0.1:80
TCP 01:57 FIN_WAIT 192.168.0.254:59472 192.168.0.100:80 172.16.0.2:80
TCP 01:50 FIN_WAIT 192.168.0.254:59466 192.168.0.100:80 172.16.0.2:80
TCP 01:43 FIN_WAIT 192.168.0.254:59460 192.168.0.100:80 172.16.0.2:80Здесь, соответственно, видим то же самое: 2 активных и 6 неактивный соединений.
ПОСЛЕСЛОВИЕ:
Предложенная нами конфигурация может послужить отправным пунктом для проектирования частного решения под конкретный проект со своими требованиями и особенностями.
Если у вас возникли вопросы по статье или что-то показалось спорным — пожалуйста, оставляйте свои комментарии, будем рады обсудить.
