
Компания Google создала систему искусственного интеллекта, которая играет лучше человека во многие аркадные игры. Программа научилась играть, не зная правил и не имея доступа к коду, а просто наблюдая за картинкой на экране.
Эта разработка не такая легкомысленная, как может показаться. Универсальная самообучаемая система когда-нибудь может найти применение, например, в автономных автомобилях и других проектах, где нужно анализировать состояние окружающих объектов и принимать решения. Скажем, при установке в автономный автомобиль ИИ методом проб и ошибок определит, на какой сигнал светофора лучше проезжать перекрёсток. Если без шуток, то программа способна находить решение для широкого спектра задач, независимо от правил и начальных условий.
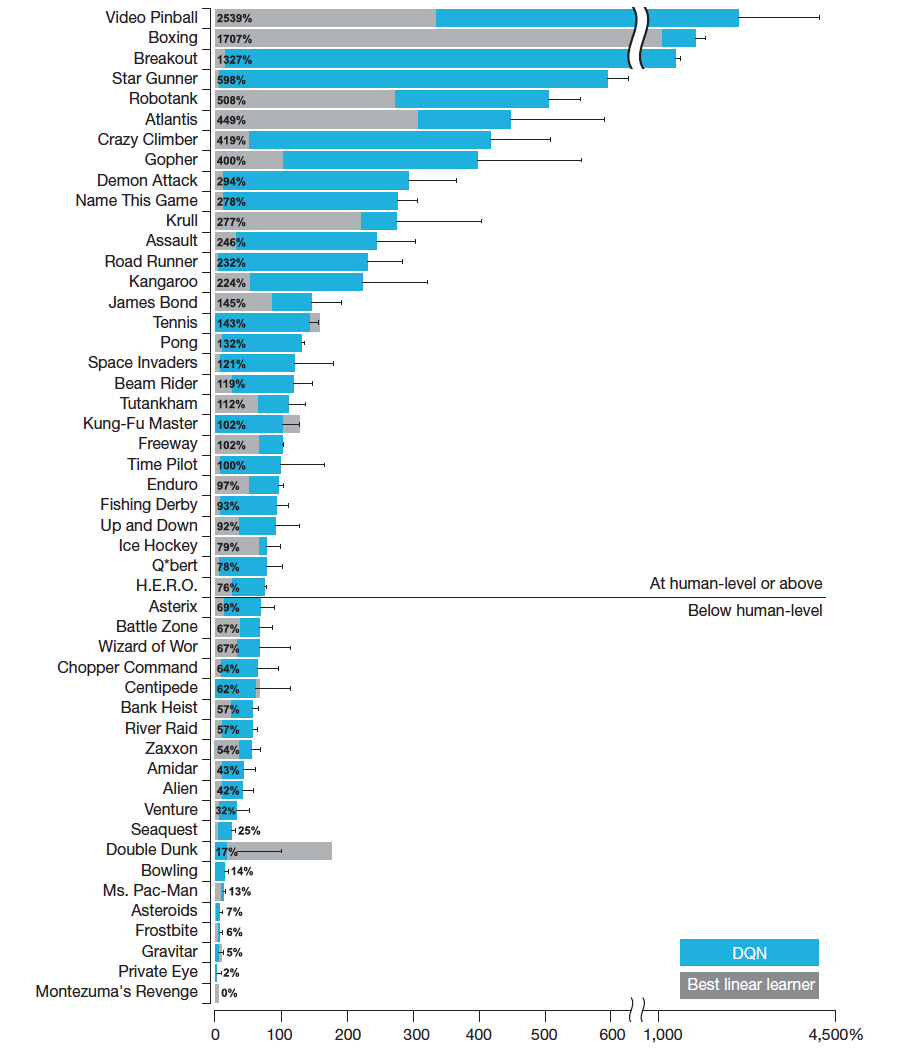
Интересно ещё и то, что в 20 играх ИИ не смог превзойти человека. Например, он серьёзно облажался в игре Pac-Man, так и не научившись планировать свои действия на несколько секунд вперёд. Он также не понял, что съев определённые волшебные шарики можно пожирать призраков. В итоге, программа сумела набрать всего 13% от рекорда, поставленного лучшим профессиональным игроком.
Тренировку нейросети под названием DQN осуществило лондонское подразделение Google DeepMind. Искусственному интеллекту не сообщали правила игры. Нейросеть сама анализировала состояние и искала способ, каким образом набрать максимальное количество очков. При обучении и принятии решения она учитывала только четыре последних кадра.
В результате DQN смогла в 22 из 49 игр превзойти лучший результат людей-игроков и в 43 из 49 игр победить любой другой специализированный компьютерный алгоритм.
«Это действительно первый в мире алгоритм, который соответствует человеческому уровню на большом разнообразии сложных задач», — говорит Демис Хассабис (Demis Hassabis), сооснователь DeepMind.
Результаты исследования опубликованы в журнале Nature.
Обучаемые нейросети часто используют в системах распознавания образов, а DeepMind использовала метод обучения с подкреплением, когда ИИ получает «вознаграждение» за выполнение определённых действий — и самостоятельно улучшает результат по мере накопления опыта.
Программа лучше всего проявила себя в простых играх вроде пинбола (2439% от результата человека), бокса (1607%) и в игре Breakout (1227%), где нужно отбивать мячик, расчищая блоки на экране. Она даже освоили трюк профессиональных игроков, когда в массиве блоков пробивается туннель и шарик запускается в верхнюю часть экрана!
«Это очень удивило нас, — сказал Хассабис. — Такая стратегия полностью вытекает из лежащей в основе игровой механики».
Компьютеры давно используются для управления игровым процессом, но современные системы ИИ вышли на новый уровень. Самообучение DQN предполагало анализ информации на экране в реальном времени, то есть обработку примерно 2 млн пикселей в секунду. Такими темпами ИИ в будущем сможет научиться анализировать окружающую действительность настоящего мира в реальном времени, снимая всё вокруг себя с помощью видеокамер. Это открывает для него совершенно новые области применения.

