
Привет! Меня зовут Марко, я работаю в Badoo в отделе «Платформы». У нас довольно много всего написано на Go, и зачастую это критичные к производительности системы. Именно поэтому сегодня я предлагаю вашему вниманию перевод статьи, которая мне очень понравилась и, я уверен, будет вам очень полезна. Автор пошагово показывает, как он подходил к проблемам производительности и как их решал. В том числе вы познакомитесь с богатым инструментарием, доступным в Go для такой работы. Приятного чтения!
Несколько недель назад я прочитал статью «Хороший код против плохого кода в Go», где автор шаг за шагом демонстрирует рефакторинг реального приложения, решающего реальные бизнес-задачи. Она сфокусирована на превращении «плохого кода» в «хороший код»: более идиоматичный, более понятный, полноценно использующий специфику языка Go. Но автор также заявлял о важности производительности рассматриваемого приложения. Во мне взыграло любопытство: давайте попробуем её ускорить!
Программа, грубо говоря, читает входящий файл, парсит его построчно и заполняет объекты в памяти.
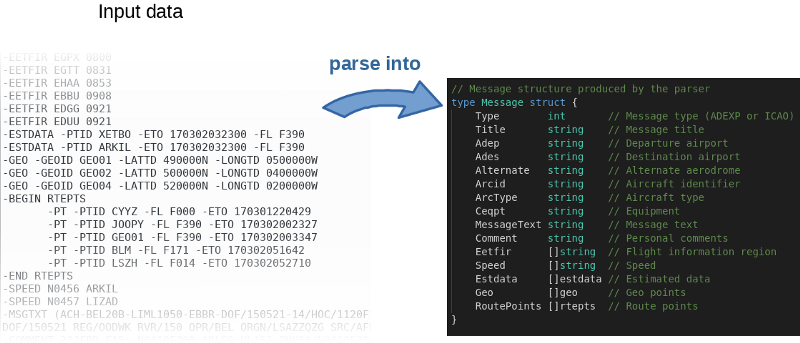
Автор не только выложил исходник на GitHub, но �� написал бенчмарк. Это классная идея. По сути, автор приглашал всех поиграться с кодом и попробовать его ускорить. Воспроизвести результаты автора можно следующей командой:
$ go test -bench=.
μs на вызов (меньше —лучше)
Получается, на моём компьютере «хороший код» на 16% быстрее. Можем ли мы его ускорить?
По моему опыту, существует корреляция между качеством кода и производительностью. Если вы успешно отрефакторили код, сделали его более чистым и менее связанным, вы, скорее всего, сделали его и быстрее, поскольку он стал менее захламлённым (и больше нет лишних инструкций, которые раньше выполнялись зря). Возможно, во время рефакторинга вы заметили какие-то возможности по оптимизации, или теперь просто-напросто появилась возможность их сделать. Но с другой стороны, если вы захотите сделать код ещё более производительным, вам, вероятно, придётся уйти от простоты и добавить различные хаки. Вы и правда скостите миллисекунды, но качество кода пострадает: станет сложнее читать его и рассуждать о нём, он станет более хрупким и гибким.
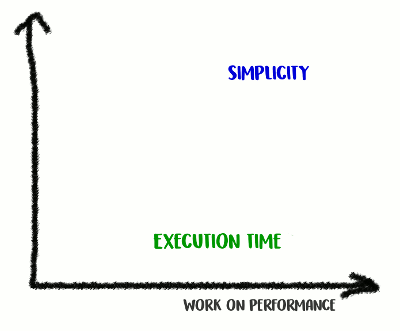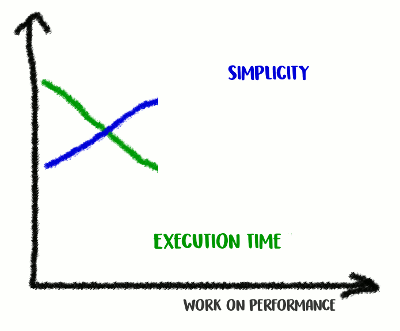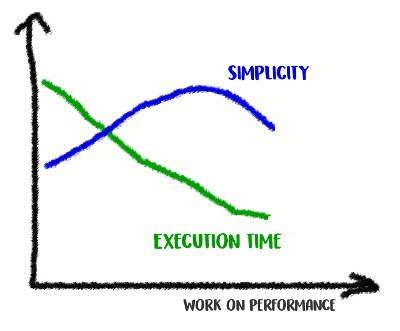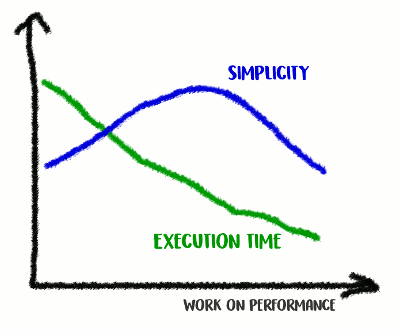
Забираемся на гору Простоты, а затем спускаемся с неё
Это трейд-офф: как далеко вы готовы зайти?
Чтобы правильно приоритизировать работу над ускорением, оптимальной стратегией является нахождение узких мест и фокусировка на них. Чтобы это сделать, воспользуйтесь инструментами для профилирования. pprof и trace — ваши друзья:
$ go test -bench=. -cpuprofile cpu.prof
$ go tool pprof -svg cpu.prof > cpu.svg
Довольно большой график использования CPU (нажмите для SVG)
$ go test -bench=. -trace trace.out
$ go tool trace trace.out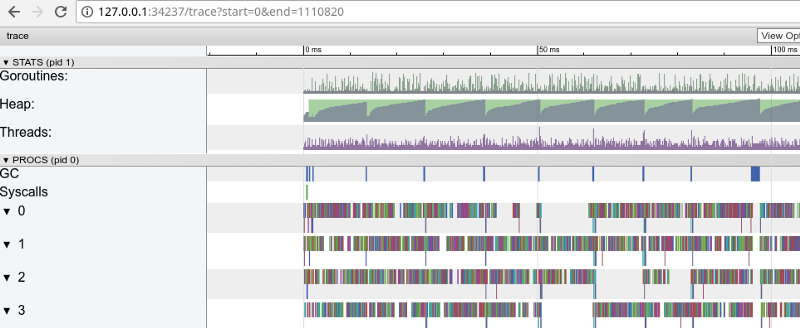
Радужная трассировка: очень много мелких заданий (нажмите, чтобы открыть, работает только в Google Chrome)
Трасcировка подтверждает, что все ядра процессора заняты (строчки внизу 0, 1 и т. д.), и, на первый взгляд, это хорошо. Но также она показывает тысячи маленьких цветных «вычислений» и несколько пустых участков, где ядра простаивали. Давайте увеличим масштаб:
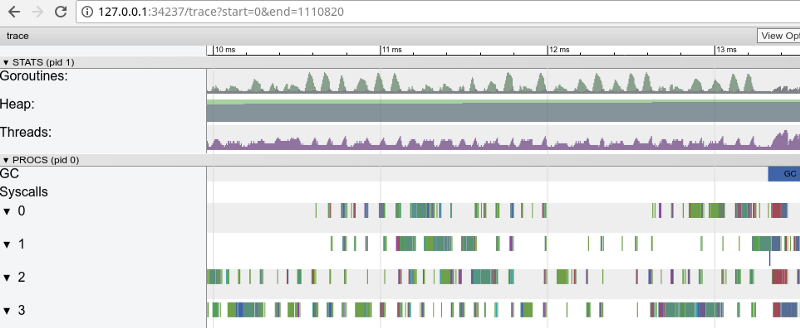
«Окно» в 3 мс (нажмите, чтобы открыть, работает только в Google Chrome)
Каждое ядро довольно много времени простаивает, а также всё время «скачет» между микрозаданиями. Похоже, гранулярность этих заданий не очень оптимальна, что ведёт к большому количеству контекст-свитчей и к конкуренции из-за синхронизаций.
Давайте посмотрим, что нам скажет рейс-детектор. Нет ли проблем в синхронном доступе к данным (если они есть, то у нас гораздо большие проблемы, чем производительность)?
$ go test -race
PASSОтлично! Всё корректно. Дата-рейсы не найдены. Функции для тестирования и функц��и-бенчмарки — разные функции (смотрите документацию), но здесь они вызывают одну и ту же функцию ParseAdexpMessage, так что то, что мы проверяли на дата-рейсы по тестам — это окей.
Конкурентная модель в «хорошей» версии состоит из обработки каждой строки из входящего файла в отдельной горутине (чтобы использовать все ядра). Интуиция автора тут сработала хорошо, так как у горутин репутация лёгких и дешёвых функций. Но как много мы выигрываем за счёт параллельного выполнения? Давайте сравним с тем же самым кодом, но не использующим горутины (просто уберем слово go, которое стоит перед вызовом функции):

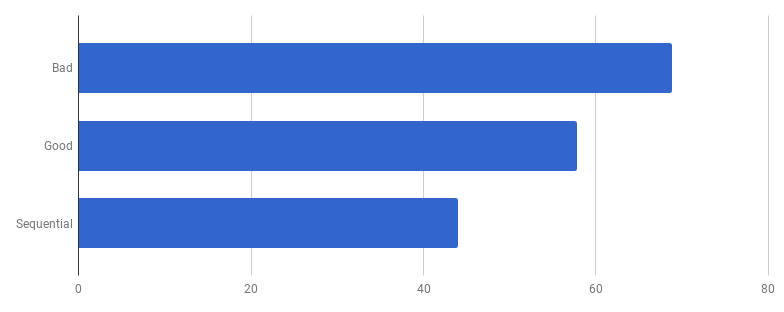
Упс, кажется, код стал быстрее без использования параллелизма. Это означает, что (ненулевой) оверхед на запуск горутин превышает время, которое мы выиграли за счёт использования нескольких ядер одновременно. Естественным следующим шагом должно стать удаление (ненулевого) оверхеда на использование каналов для отправки результатов. Давайте заменим его на обычный слайс:
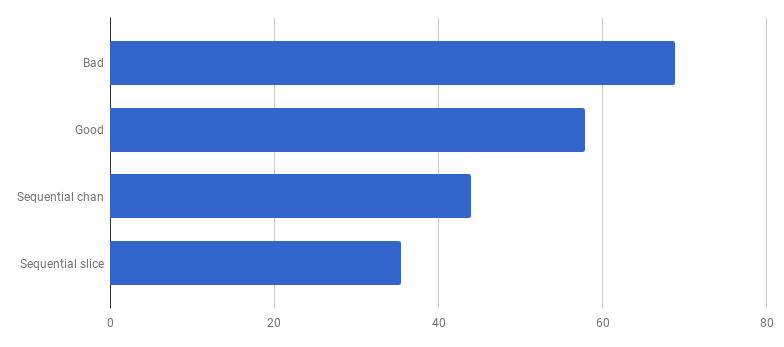
μs на вызов (меньше — лучше)
Мы получили примерно 40%-ускорение по сравнению с «хорошей» версией, упростив код и убрав конкурентность (diff).
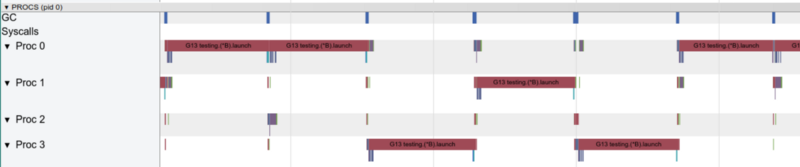
С одной горутиной только одно ядро работает в один момент времени
Давайте теперь посмотрим на горячие функции на pprof-графике:

Ищем узкие места
Бенчмарк текущей версии (последовательная работа, слайсы) тратит 86% времени на парсинг сообщений, и это нормально. Но мы быстро заметим, что 43% времени тратится на использование регулярных выражений и функцию (*Regexp).FindAll.
Несмотря на то, что регулярные выражения — это удобный и гибкий способ достать данные из обычного текста, у них есть недостатки, среди которых использование большого количества ресурсов и процессора, и памяти. Они являются мощным инструментом, но зачастую их применение излишне.
В нашей программе шаблон
patternSubfield = "-.[^-]*"в основном предназначен для выделения команд, начинающихся с тире (—), и в строке их может быть несколько. Это, потюнив немножко код, можно сделать с помощью bytes.Split. Давайте адаптируем код (commit, commit), чтобы поменять регулярные выражения на Split:
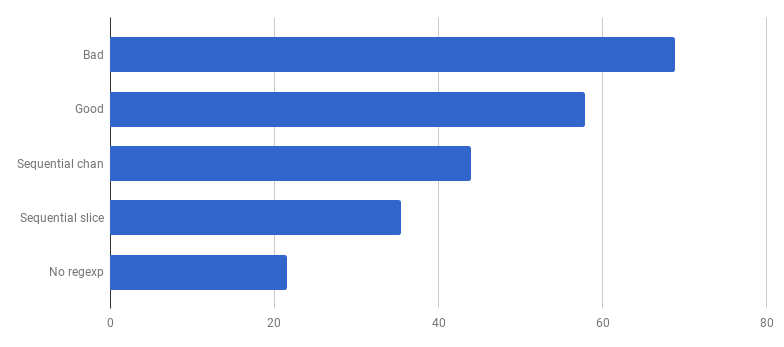
μs на вызов (меньше — лучше)
Вау! Ещё на 40% более производительный код! График потребления CPU теперь выглядит так:

Больше не тратится много времени на регулярные выражения. Значительная его часть (40%) уходит на аллокацию памяти из пяти различных функций. Интересно, что теперь 21% времени тратится на функцию bytes.Trim:

Эта функция меня интригует. Что мы тут можем сделать?
bytes.Trim ожидает строку с символами, которые «срезает» в качестве аргумента, но в качестве этой строки мы передаем строку только с одним символом — пробелом. Это как раз пример того, как можно получить ускорение за счёт усложнения: создадим свою функцию trim вместо стандартной. Наша кастомная функция «trim» будет работать с одним байтом вместо целой строки:

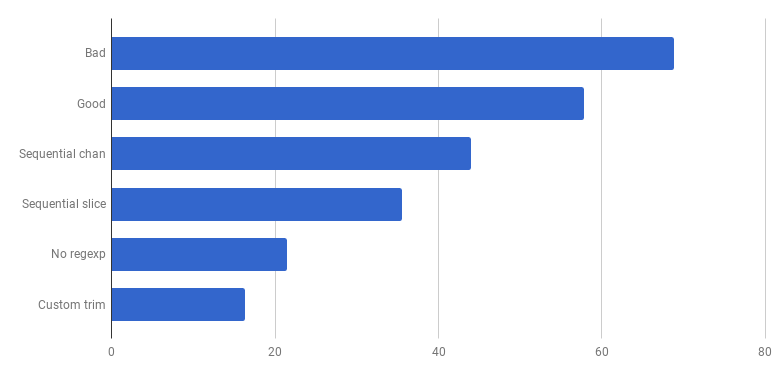
μs на вызов (меньше — лучше)
Ура, ещё 20% отсекли! Текущая версия в четыре раза быстрее оригинальной «плохой» и при этом использует только одно ядро. Неплохо!
Ранее мы отказались от конкурентности на уровне обработки линий, но я утверждаю, что получить ускорение можно, использовав конкурентность на более высоком уровне. Например, обработка 6000 файлов (6000 сообщений) быстрее на моём компьютере, если каждый файл обрабатывается в своей горутине:
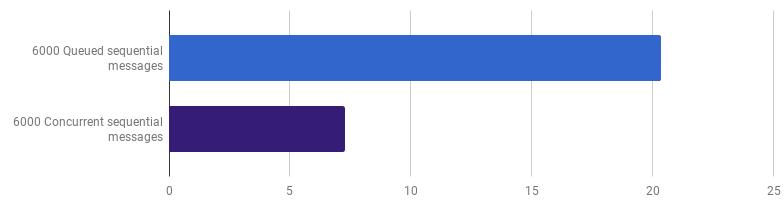
μs на вызов (меньше — лучше; фиолетовый — конкурентное решение)
Выигрыш — 66% (то есть ускорение в три раза). Это хорошо, но не очень, учитывая, что используются все 12 процессорных ядер, что у меня есть. Это может означать, что новый оптимизированный код, обрабатывающий целый файл, — всё ещё «мелкая задача», для которой оверхед по созданию горутины и расходы на синхронизацию не незначительны. Довольно интересно, что увеличение количества сообщений с 6000 до 120 000 не даёт никакого эффекта на однопоточной версии и уменьшает производительность на версии «одна горутина на сообщение». Это происходит, потому что, несмотря на то, что создание такого большого количества горутин возможно и иногда полезно, оно привносит собственный оверхед в области рантайм-шедулера.
Мы можем ещё сократить время выполнения (не в 12 раз, но всё же), создав всего лишь несколько воркеров. Например, 12 долгоживущих горутин, каждая из которых будет обрабатывать часть сообщений:
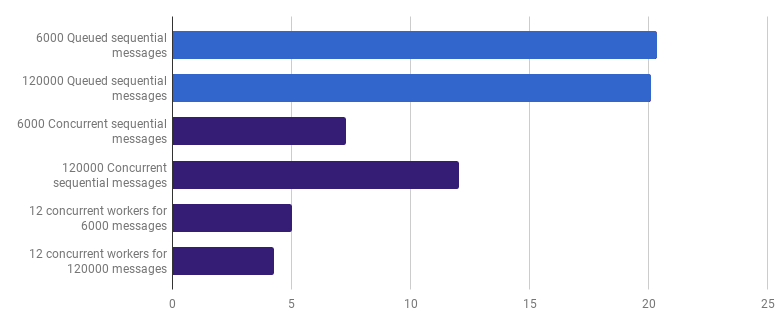
μs на вызов (меньше — лучше; фиолетовый — конкурентное решение)
Такой вариант сокращает время выполнения на 79% по сравнению с однопоточной версией. Заметьте, что эта стратегия имеет смысл, только если у вас много файлов для обработки.
Оптимальное использование всех ядер процессора заключается в использовании нескольких горутин, каждая из которых обрабатывает значительное количество данных без какого-либо взаимодействия или синхронизации до того, как работа будет закончена.
Обычно берут столько процессов (горутин), сколько ядер у процессора, но это не всегда оптимальный вариант: всё зависит от конкретной задачи. Например, если вы считываете что-то с файловой системы или делаете много сетевых вызовов, то для получения большей производительности следует использовать большее количество горутин, чем у вас ядер.
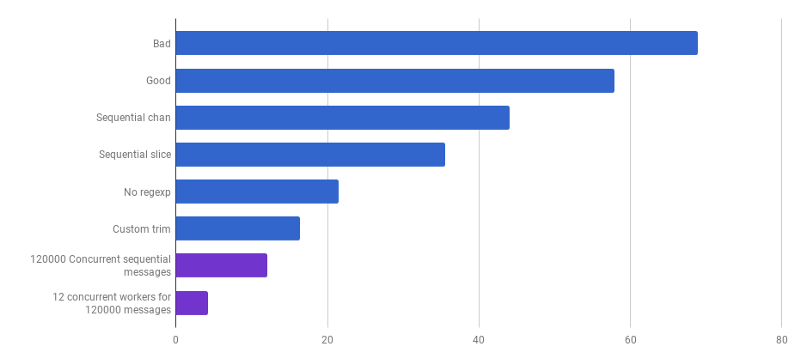
μs на вызов (меньше — лучше; фиолетовый — конкурентное решение)
Мы подошли к моменту, когда производительность парсинга сложно увеличить какими-то локализованными изменениями. Во времени выполнения доминирует время на выделение памяти и сборку мусора. Это звучит логично, так как функции по управлению памятью довольно медленны. Дальнейшая оптимизация процессов, связанных с аллокациями, остаётся в качестве домашнего задания читателям.
Использование других алгоритмов также может приводить к большому выигрышу в производительности.
Тут я вдохновился докладом Lexical Scanning in Go от Rob Pike,
чтобы создать кастомный лексер (source) и кастомный парсер (source). Это пока ещё не готовый код (я не обрабатываю кучу корнер-кейсов), он менее понятный, чем оригинальный алгоритм, и иногда сложно написать корректную обработку ошибок. Но он мелкий и на 30% более быстрый, чем самая оптимизированная версия.
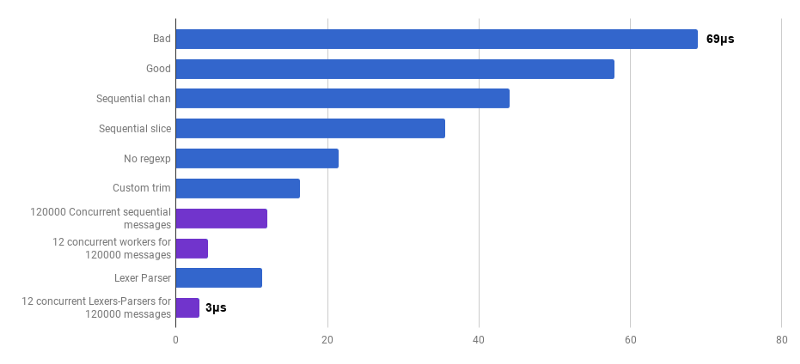
μs на вызов (меньше — лучше; фиолетовый — конкурентное решение)
Да. В итоге мы получили ускорение в 23 раза по сравнению с исходным кодом.
На сегодня всё. Я надеюсь, что вам понравилось это приключение. Вот несколько замечаний и выводов:
- Производительность может быть улучшена на самых разных уровнях абстракций, с использованием разных техник, и выигрыш зачастую увеличивается.
- Тюнить нужно начинать с высокоуровневых абстракций: структуры данных, алгоритмы, правильное развязывание модулей. Займитесь низкоуровневыми абстракциями позднее: I/O, батчинг, конкурентность, использование стандартной библиотеки, работа с памятью, выделение памяти.
- Big O- анализ очень важен, но обычно не самый подходящий инструмент для ускорения программы.
- Написание бенчмарков — тяжёлая работа. Используйте профилирование и бенчмарки, чтобы найти узкие места и получить более широкое понимание происходящего в программе. Держите в уме, что результаты бенчмарка — это не то же самое, что будут испытывать ваши пользователи при реальной работе.
- К счастью, набор инструментов (Bench, pprof, trace, Race Detector, Cover) делает исследование производительности кода доступным и интересным.
- Написание хороших, уместных тестов — задача нетривиальная. Но они чертовски важны, чтобы не уйти в дебри. Вы сможете рефакторить, будучи уверенным в том, что код остался правильным.
- Остановитесь и спросите себя, насколько быстро это «достаточно быстро». Не тратьте своё время на оптимизацию какого-то одноразового скрипта. Не забывайте, что оптимизация не даётся даром: время инженера, сложность, баги и технический долг.
- Думайте дважды, прежде чем усложнять код.
- Алгоритмы со сложностью Ω(n²) и выше обычно слишком дороги.
- Алгоритмы со сложностью O(n) или O(n log n) и ниже обычно окей.
- Различные скрытые факторы нельзя не принимать в расчёт. К примеру, все улучшения в статье были сделаны за счёт уменьшения этих факторов, а не за счёт изменения класса сложности алгоритма.
- I/O — это часто узкое место: сетевые запросы, запросы к базе данных, файловая система.
- Регулярные выражения — зачастую слишком дорогое и ненужное решение.
- Аллокации памяти дороже, чем вычисления.
- Объект, выделенный на стеке, дешевле объекта, выделенного в куче.
- Слайсы полезны в качестве альтернативы дорогому перемещению памяти.
- Строки эффективны, когда используются только для чтения (включая реслайсинг). Во всех остальных случаях []byte более эффективны.
- Очень важно, чтобы данные, которые вы обрабатываете, находились рядом (кеши процессора).
- Конкурентность и параллельность очень полезны, но их сложно готовить.
- Когда вы копаете глубоко и низкоуровнево, помните о «стеклянном полу», который вы не хотите проломить в Go. Если у вас руки чешутся попробовать инструкции ассемблера, SIMD-инструкции, возможно, нужно использовать Go только для прототипирования, а затем переходить на более низкоуровневый язык, чтобы получить полное управление железом и каждой наносекундой!

