
Хабр Курсы для всех
РЕКЛАМА
Практикум, Хекслет, SkyPro, авторские курсы — собрали всех и попросили скидки. Осталось выбрать!
F1 score — это синтетический показатель объединяющий пользу от precisions и recall. Его самое хорошее значение вблизи 70%.
Почему 70 % лучше, чем, например, 95 %?
Затем recall — хорошее значение 0.5
А, что? Хорошее значение recall — это единица, когда мы не даем false negative.
Для нашего примера такое, явно недостаточное число порченных персиков в контрольной выборке, может породить сомнение, а так ли все хорошо с обучением? Или все дело в том, что просто мало порченных персиков.
Извините, но порченные персики в контрольной выборке — это просто negative, не обязательно false negative.
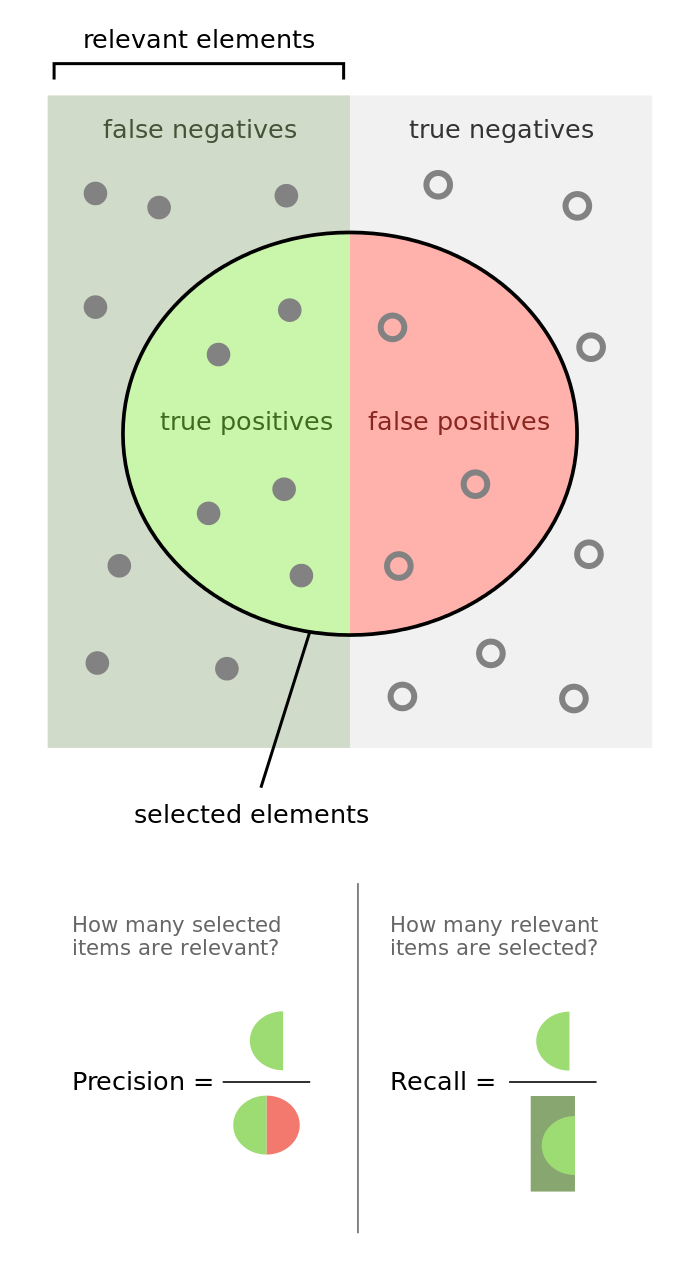
А теперь разберем 4 показателя эффективности ML, в которых бывает путаются. Это true-positive (TP), false-positive (FP), true-negative (TN) и false-negative(FN). Первая половина слова означает совпадение (true) или несовпадение (false) мнения вашей сестры с тайной наклейкой на персике. Вторая половина просто означает контейнер, в который ваша сестра бросила персик (X-хороший — positive, П-плохой — negative). А два слова вместе — это просто число персиков в такой категории.
Затем recall — хорошее значение 0.5 (это значит что обучаемый в равной степени хорошо проверен на способность различать хороший и плохой вариант).
Это не так. У идеального классификатора значение recall = 1.
Если вы откроете хотя бы википедию, то увидите, что идеальное значение F1 также 1.
Простите, а чем вот это всё, которое вы описали, отличается от совершенно не специфических для ML "приемочных критериев"?
Проект ML должен начаться с легитимации метрики валидизации.
Знаете, что занятно? Никогда, ни в какой литературе о ML-проектах я не видел этого термина. Можете дать ссылку на источник?
Важнейшим показателем текущего положения дел в проекте для менеджмента является accuracy.
А с чего бы вдруг? Люди копья ломают, подбирают метрику под конкретную бизнес-задачу — а вы так взяли, и легко выдали "важнейший показатель — accuracy".
Естественно, каждый проект ML в зависимости от своей предметной сферы будет иметь свою собственную метрику валидизации
Зачастую возникает вопрос: зачем менеджеру проекта ML так глубоко знать и понимать все эти показатели. Ответ: это важно для бизнеса. Как менеджеру молочной фермы нужно знать, что такое удои ...
Машинное обучение для менеджеров: таинство сепуления