Предлагаю ознакомиться с расшифровкой доклада Николая Самохвалова "Промышленный подход к тюнингу PostgreSQL: эксперименты над базами данных"
Shared_buffers = 25% – это много или мало? Или в самый раз? Как понять, подходит ли эта – довольно устаревшая – рекомендация в вашем конкретном случае?
Пришло время подойти к вопросу подбора параметров postgresql.conf "по-взрослому". Не с помощью слепых "автотюнеров" или устаревших советов из статей и блогов, а на основе:
- строго выверенных экспериментов на БД, производимых автоматизированно, в больших количествах и в условиях, максимально приближенных к "боевым",
- глубокого понимания особенностей работы СУБД и ОС.
Используя Nancy CLI (https://gitlab.com/postgres.ai/nancy), мы рассмотрим конкретный пример – пресловутые shared_buffers – в разных ситуациях, в разных проектах и попробуем разобраться, как же подобрать оптимальную настройку для нашей инфраструктуры, БД и нагрузки.

Речь пойдет об экспериментах над базами данных. Это история, которая продолжается чуть больше полугода.

Немножко обо мне. Опыт с Postgres уже больше 14 лет. Ряд компаний основал социально-сетевых. Везде использовался Postgres и используется.
Также группа RuPostgres на Meetup, 2-е место в мире. Приближаемся потихоньку к 2 000 человек. RuPostgres.org.
И в ПК различных конференций, включая Highload, я отвечаю за базы данных, в частности Postgres с самого основания.

И в последние несколько лет я рестартовал мою практику по Postgres-консалтингу в 11 часовых поясах от сюда.

И когда я это сделал несколько лет назад, у меня был некоторый перерыв активной ручной работы с Postgres, наверное, с 2010-го года. Я удивился, насколько мало изменились трудовые будни DBA, насколько нужно по-прежнему много ручного труда использовать. И я сразу подумал, что тут что-то не так, нужно автоматизировать побольше всего.
И так как это все было в удалении, то большинство клиентов было в облаках. И уже много автоматизировано очевидно. Об этом чуть позже. Т. е. все это вылилось в идею, что должно быть ряд инструментов, т. е. некая платформа, которая будет автоматизировать практически все действия DBA, чтобы можно было управлять большим количеством баз.

В этом докладе не будет:
- «Серебряных пуль» и заявлений типа – ставьте 8 GB или 25 % shared_buffers и вам будет хорошо. Про shared_buffers будет не так много.
- Хардкорных «внутренностей».

А что будет?
- Будут принципы оптимизации, которые мы применяем и развиваем. Будут всякие идеи, которые возникают у нас на пути и разные инструменты, которые мы создаем по большей части в Open Source, т. е. мы основу делаем в Open Source. Более того у нас тикеты, все общение практически в Open Source. Вы можете смотреть, что мы сейчас делаем, что будет в следующем релизе и т. д.
- А также будет некоторый опыт использования этих принципов, этих инструментов в ряде компаний: от маленьких стартапов до больших компаний.

Как это все развивается?

Во-первых, основная задача DBA помимо обеспечения создания instances, развертывания бэкапов и т. д., — это поиск узких мест и оптимизация производительности.
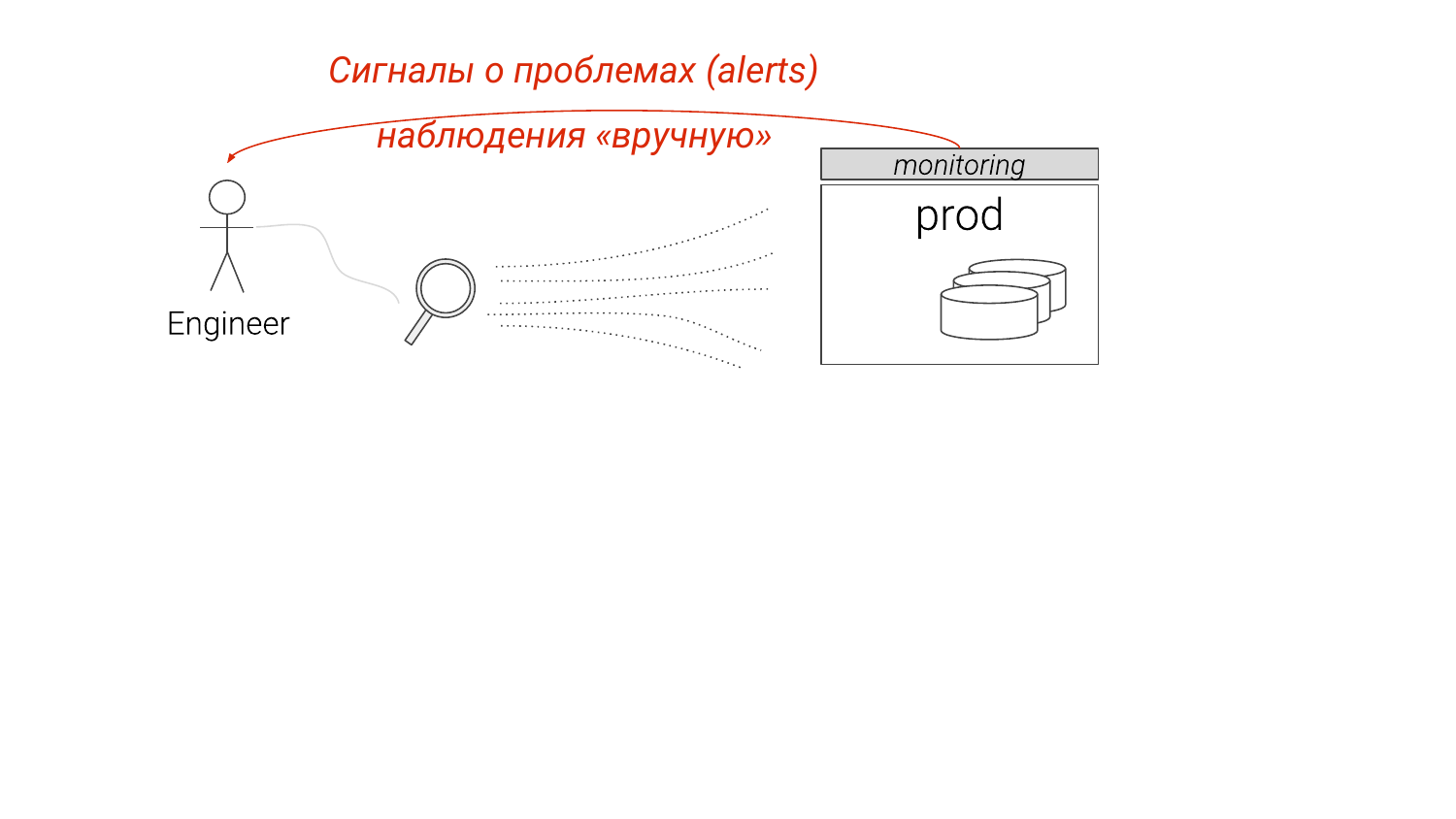
Сейчас это устроено вот таким образом. Мы смотрим мониторинг, что-то видим, каких-то подробностей нам не хватает. Мы начинаем копаться внимательнее, обычно руками и понимаем, что с этим делать так или иначе.
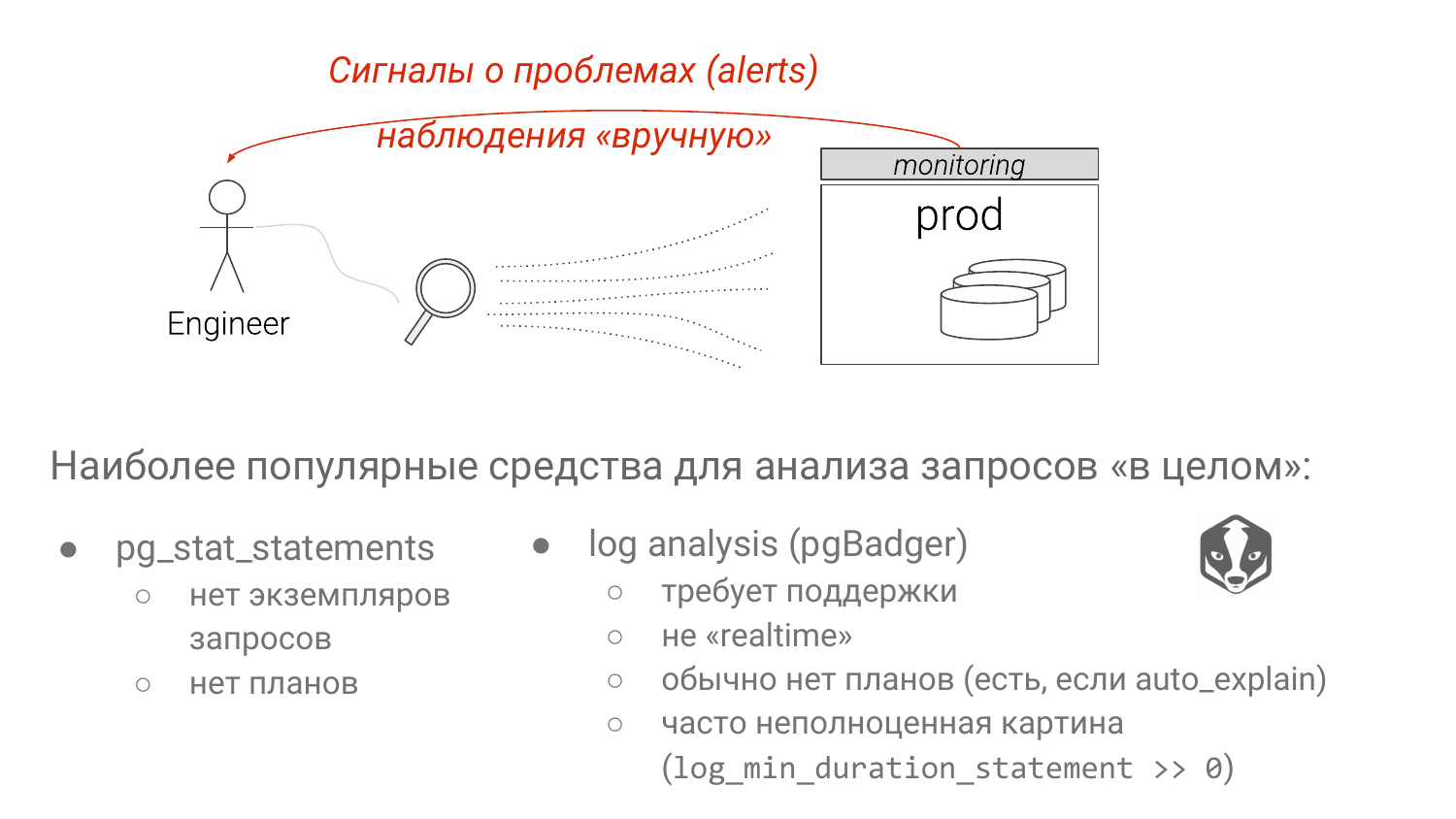
И есть два подхода. Pg_stat_statements – стандартное решение по умолчанию для выявления медленных запросов. И анализ логов Postgres с помощью pgBadger.
У каждого из подходов есть серьезные недостатки. У первого подхода у нас выброшены все параметры. И если мы видим группы SELECT * FROM table where колонка равно знаку «?» или «$» начиная с версии Postgres 10. Мы не знаем – это index scan или seq scan. Очень сильно зависит от параметра. Подставишь туда редко встречаемое значение, будет index scan. Подставишь туда значение, которое занимает 90 % таблицы, будет seq scan очевидно, потому что Postgres знает статистику. И это большой недостаток pg_stat_statements, хотя какие-то работы ведутся.
У анализов логов самый главный недостаток в том, что вы не можете себе позволить «log_min_duration_statement = 0», как правило. И об этом мы тоже поговорим. Соответственно, вы видите не всю картинку. И какой-то запрос, который очень быстрый, может потреблять огромное количество ресурсов, но вы его не увидите, потому что он ниже вашего порога.
Как DBA решают найденные проблемы?

Например, мы нашли какую-то проблему. Что обычно делается? Если вы разработчик, то вы будете что-то делать на каком-то instance, который не такого размера. Если вы DBA, то у вас есть staging. И он может быть только один. И он отстал на полгода. И вы думаете, что пойдете на production. И даже опытные DBA проверяют потом на production, на реплике. И бывает что создают временный индекс, убеждаются, что он помогают, дропают его и отдают разработчикам, чтобы они его в миграционные файлы засунули. Вот такой бред происходит сейчас. И это беда.
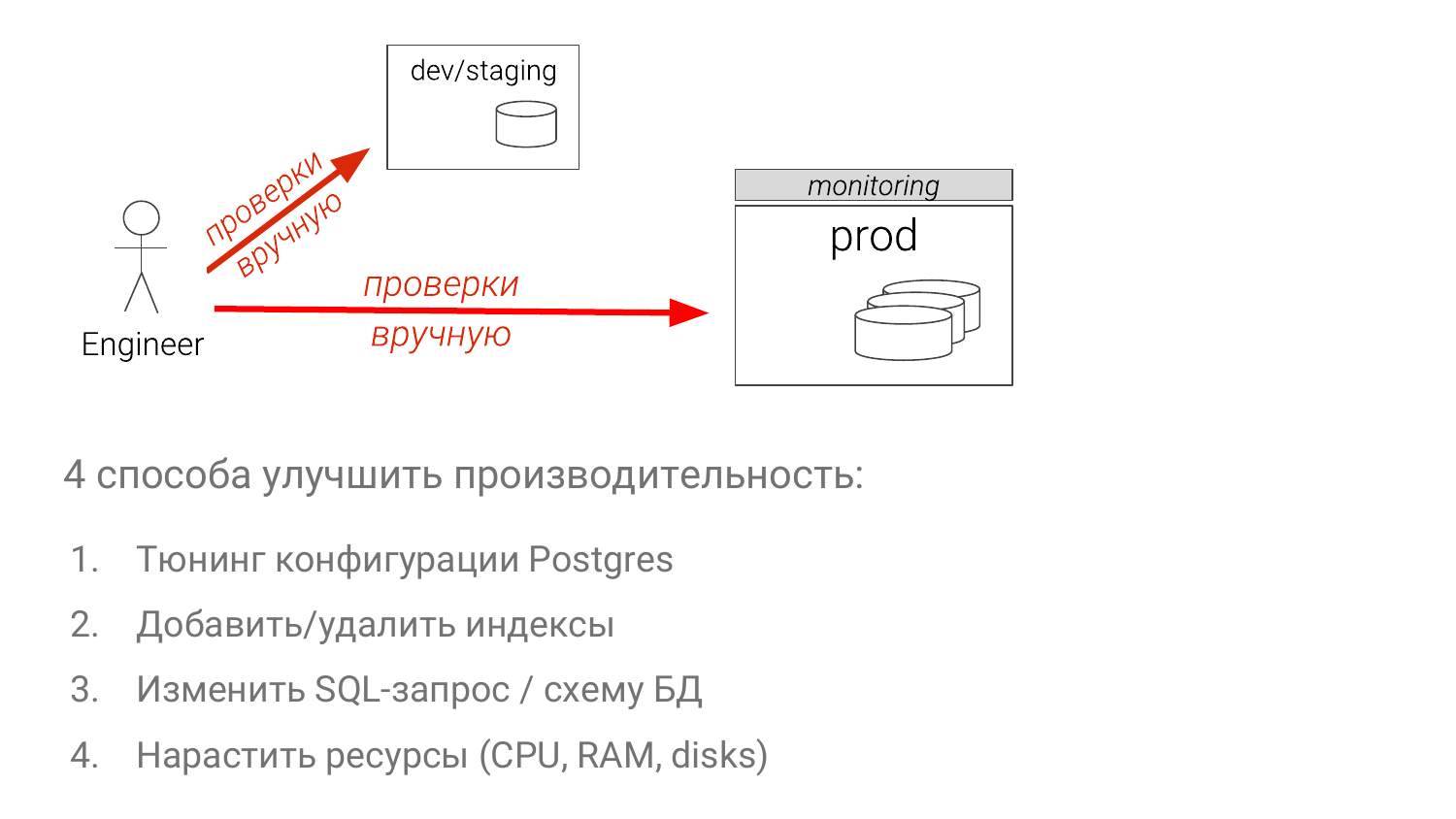
- Тюнить конфигурации.
- Оптимизировать набор индексов.
- Изменять сам SQL-запрос (это самый сложный способ).
- Добавлять мощностей (самый простой способ в большинстве случаев).

С этими вещами очень много всего. Там много ручек в Postgres. Нужно много знать. Много индексов в Postgres, благодаря в том числе организаторам этой конференции. И все это нужно знать, и именно это у не DBA вызывает ощущение, что DBA занимаются черной магией. Т. е. нужно лет 10 заниматься, чтобы начать понимать все это нормально.
И я – борец с этой черной магией. Я хочу сделать все так, чтобы была технология, а не было интуиции во всем этом.
Примеры из жизни

Это я наблюдал минимум в двух проектах, включая свой. Очередной пост в блоге сообщает нам, что значение 1 000 для default_statistict_target – это хорошо. Хорошо, давайте попробуем в production.

И тут мы, используя наш инструмент два года спустя с помощью экспериментов над базами данных, о которых сегодня речь, мы можем сравнить что было и что стало.
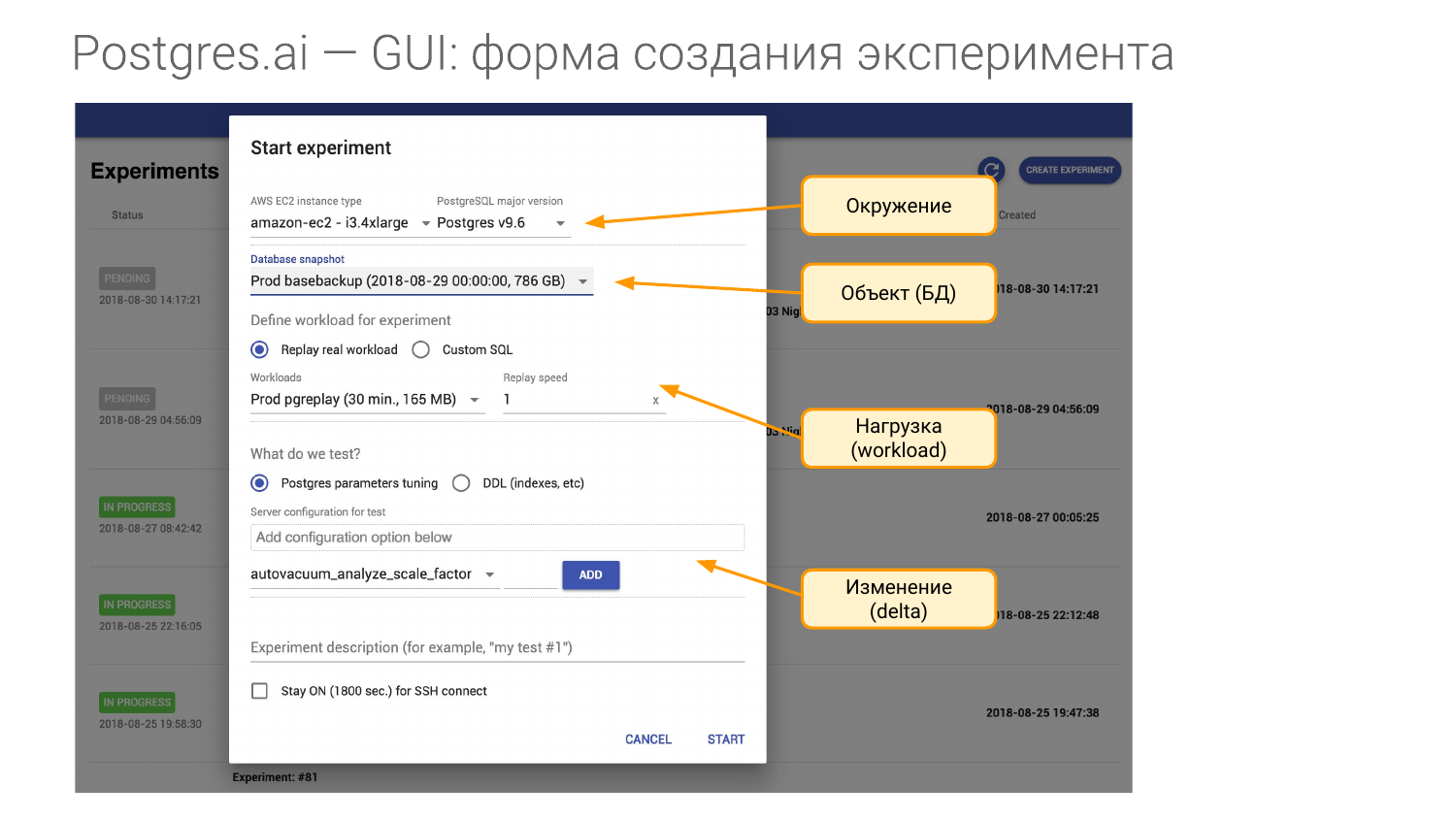
И для этого нам нужно создать эксперимент. Он состоит из четырех частей.
- Первая – это окружение. Нам нужна железка. И когда я прихожу в какую-то компанию и заключаю контракт, то я говорю, чтобы мне дали такую же железку как на production. Для каждого из ваших Мастеров мне нужна хотя бы одна железка такая же. Либо это виртуальная машина instance в Амазоне или в Google, либо мне именно такая же железка нужна. Т. е. я хочу воссоздать окружение. И в понятие окружение мы вкладываем мажорную версию Postgres.
- Вторая часть – это объект наших исследований. Это база данных. Ее можно создать несколькими способами. Я покажу как.
- Третья часть – это нагрузка. Это самый сложный момент.
- И четвертая часть – это то, что мы проверяем, т. е. что с чем сравнивать будем. Допустим, мы можем в конфиге поменять один или несколько параметров, а можем индекс создать и т. д.

Мы запускаем эксперимент. Вот pg_stat_statements. Слева – то, что было. Справа – что стало.

Слева default_statistics_target = 100, справа =1 000. Мы видим, что нам это помогло. На 8 % в целом все лучше стало.
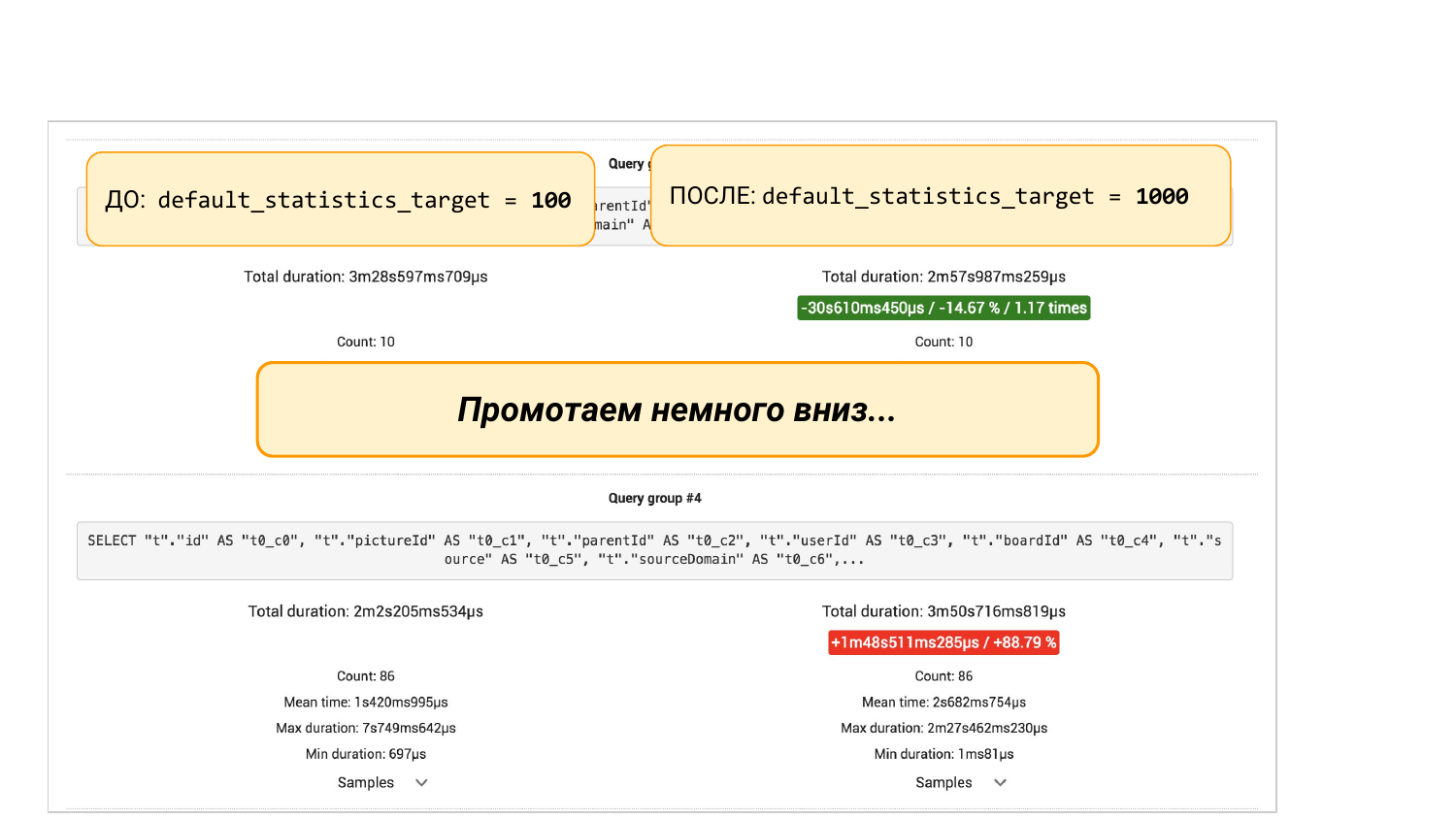
Но если мы промотаем вниз, то там будут группы запросов из pgBadger или из pg_stat_statements. Тут два варианта. Мы увидим, что какой-то запрос просел на 88 %. И тут уже инженерный подход. Мы можем дальше копать внутрь, потому что интересно, почему он просел. Надо понимать, что там было со статистикой. Почему больше бакетов в статистике приводят к худшему результату.
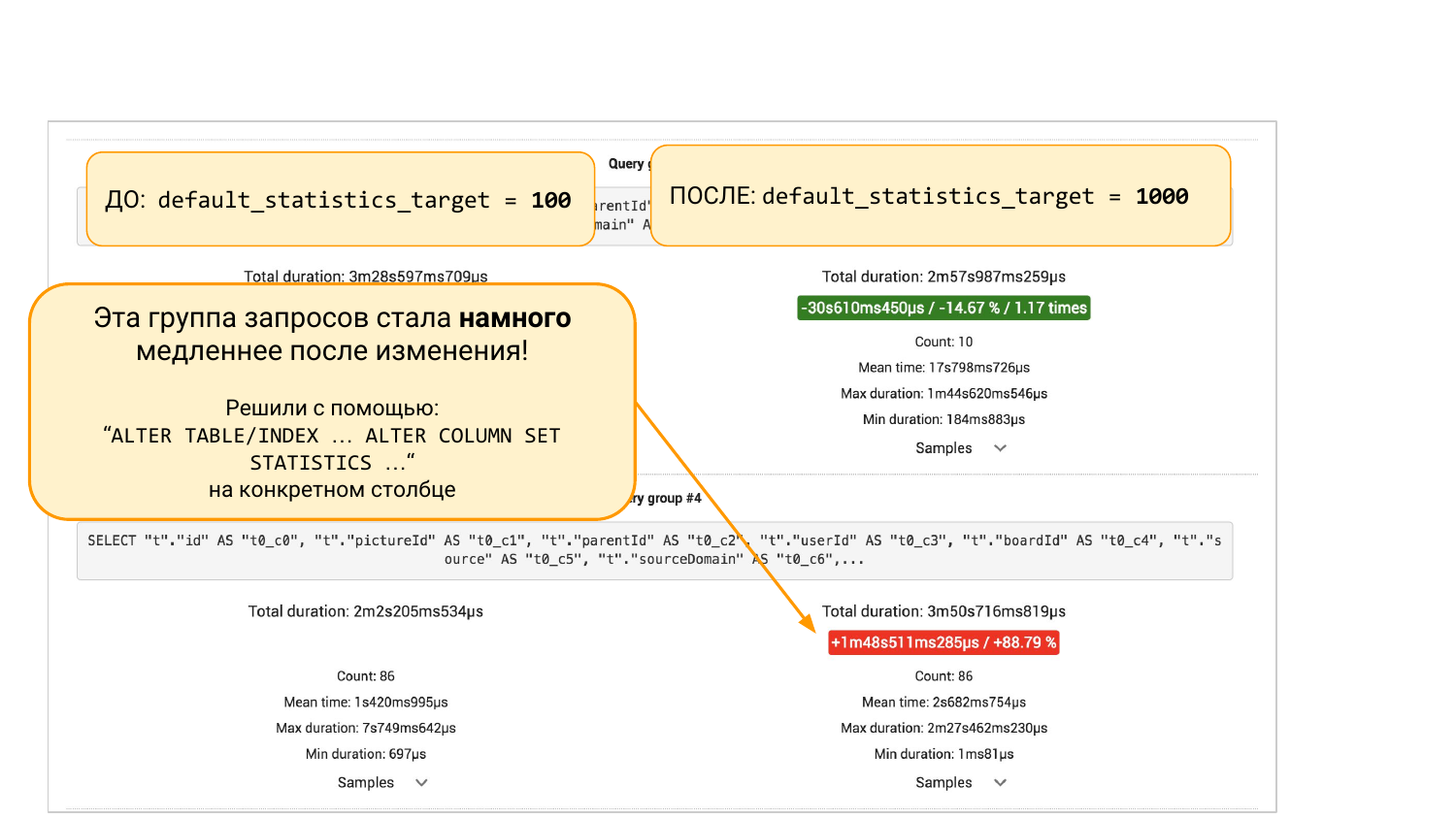
А можем не копать, а сделать «ALTER TABLE … ALTER COLUMN» и ему обратно 100 бакетов вернем в статистику этой колонке. И дальше еще экспериментом мы можем убедиться, что эта заплатка помогла. Все. Вот это инженерный подход, который помогает нам видеть картину и принимать решение на основе данных, а не на основе интуиции.


Пара примеров из других областей. В тестах есть CI-тесты уже много лет. И ни один уже проект в здравом уме не будет жить без автоматических тестов.
В других отраслях: в авиации, в автомобилестроении, когда испытываем аэродинамику, у нас тоже есть возможность делать эксперименты. Мы не будем что-то с чертежа сразу в космос запускать или не будет какую-то машину сразу выводить на трассу. Например, есть аэродинамическая труба.
Из наблюдений за другими отраслями мы можем сделать выводы.

Во-первых, у нас есть специальное окружение. Оно близко к production, но не близко. Главная его особенность в том, что должно быть дешево, повторяемо и максимально автоматизировано. И еще должны быть специальные средства для проведения детального анализа.
Скорее всего, когда мы самолет запустили и летим, у нас меньше возможностей изучать каждый миллиметр поверхности крыла, чем есть в аэродинамической трубе. У нас больше средств для диагностики. Мы можем себе позволить навесить побольше всего тяжелого, что не можем позволить себе навестить на самолет в воздухе. Также и с Postgres. Мы можем в некоторых случаях включить полное логирование запросов при экспериментах. И мы этого на production делать не хотим. Мы, может быть, даже с планами это включим с помощью auto_explain.
И как я уже сказал, высокий уровень автоматизации означает, что мы нажали кнопку и повторили. Вот так должно это быть, чтобы было много экспериментов, чтобы это было на потоке.
Nancy CLI – фундамент «лаборатории БД»

И вот мы сделали такую штуку. Т. е. я об этих идеях рассказывал в июне, почти год назад. И у нас уже есть в Open Source так называемая Nancy CLI. Это фундамент для того, чтобы строить лабораторию базы данных.

Nancy — Это в Open Source, на Gitlab. Можете сказать, можете попробовать. Я дал ссылочку в ��лайдах. На нее можно кликнуть и там будет help по всем параметрам.
Конечно, там многое еще в стадии разработки. Там много количество идей. Но это уже то, что мы применяем практически ежедневно. И когда у нас возникает идея – а что это при delete 40 000 000 строчек у нас все уперлось в IO, то мы можем провести эксперимент и посмотреть подробнее, чтобы понять, что происходит и дальше попытаться исправить это на ходу. Т. е. мы делаем эксперимент. Например, что-то подкручиваем и смотрим, что в итоге получается. И мы это делаем не на production. Это суть идеи.

Где это может работать? Это может работать локально, т. е. можно это делать где угодно, можно даже на MacBook запустить. Нужен докер, поехали. И все. Можно запустить в каком-нибудь instance в железке, либо в виртуалке, где угодно.
И есть еще возможность запускать удаленно в Амазоне в EC2 Instance, в спотах. И это очень классная возможность. Например, вчера мы провели больше 500 экспериментов на i3 instance, начиная с самого младшего и заканчивая i3-16-xlarge. И нам 500 экспериментов встали в 64 доллара. Каждый длился 15 минут. Т. е. за счет того, что там используются споты, это очень дешево – скидка 70 %, посекундная тарификация Амазона. Вы можете делать очень много. Вы можете реальное исследование проводить.
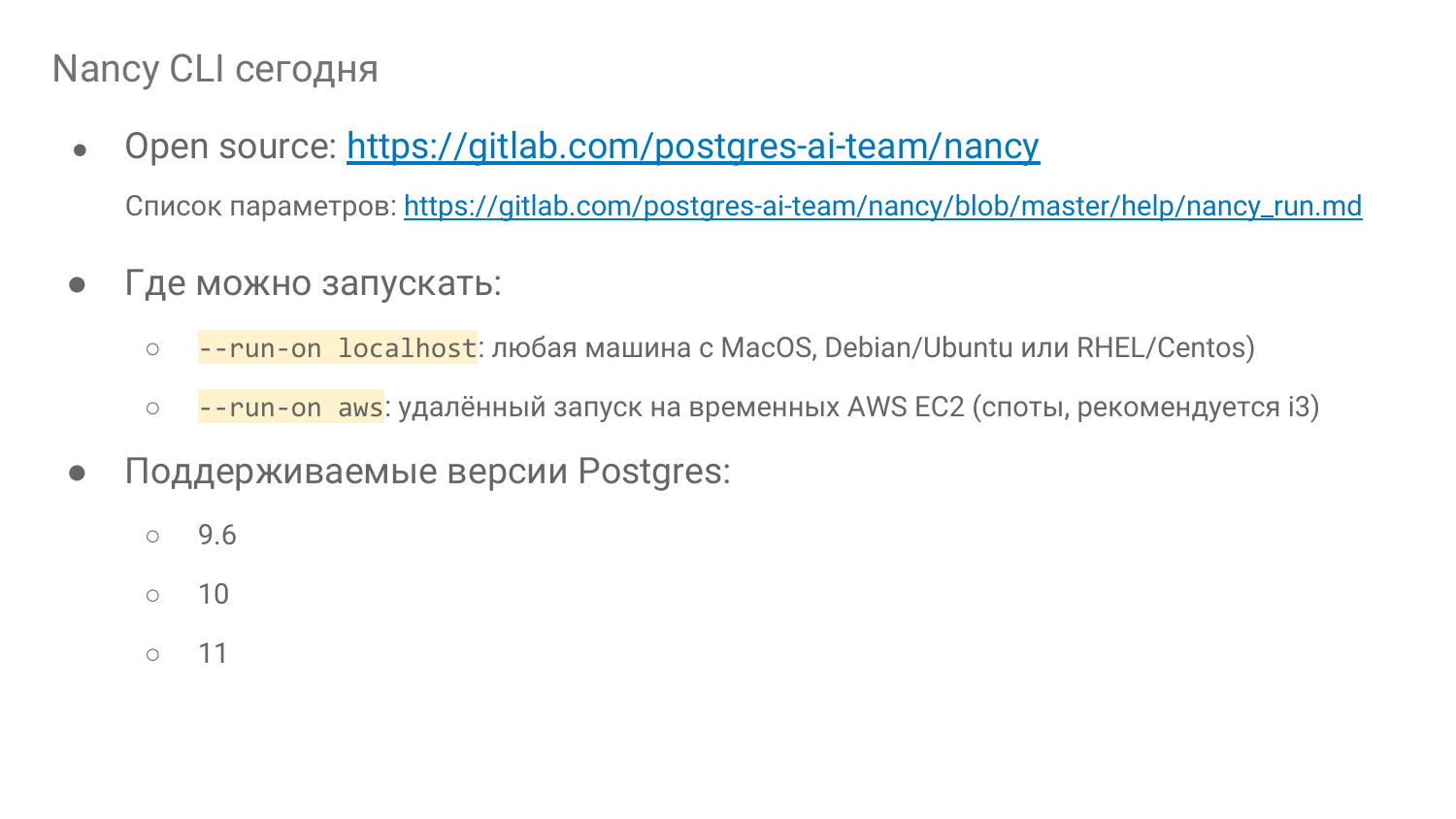
И три мажорные версии Postgres поддерживаются. Не так сложно допилить какие-то старые и новую 12-ую версию тоже.

Объект мы можем тремя способами задавать. Это:
- Dump/sql-файл.
- Главный способ – это клон PGDATA директория. Как правило берется из бэкап-сервера. Если у вас есть бинарные бэкапы нормальные, оттуда можете клоны делать. Если у вас есть облака, то за вас это облачная контора типа Амазона и Google сама будет делать. Это самый главный способ для клонов реального production. Мы таким образом как раз разворачиваем.
- И последний способ подходит для исследований, когда есть желание разобраться, как в Postgres работает какая-то штука. Это pgbench. Вы можете сгенерировать с помощью pgbench. Это просто одна опция «db-pgbench». Говоришь ему, какой scale. И все будет в облаке сгенерировано, как сказано.

И нагрузка:
- Нагрузку мы можем в один поток SQL исполнять. Это самый примитивный способ.
- А можем эмулировать нагрузку. И эмулировать мы прежде всего можем ее следующим образом. Нам нужно собирать все логи. И это болезненно. Я покажу, почему. И с помощью pgreplay проигрываем, который встроен в Nancy.
- Или другой вариант. Так называемая крафтовая нагрузка, которую мы делаем с некоторым количеством усилий. Анализируя нашу текущую нагрузку на боевую систему, мы выдергиваем топовые группы запросов. И с помощью pgbench можем эмулировать эту нагрузку в лаборатории.

- Либо мы SQL какой-то должны выполнить, т. е. миграцию какую-то проверяем, индекс там создаем, ANALAZE там выполняем. И смотрим, что было до вакуума и после вакуума. В общем, любой SQL.
- Либо мы в конфиге меняем один или несколько параметров. Мы можем сказать, чтобы нам проверили, например, 100 значений в Амазоне для нашей терабайтной базы. И через несколько часов у вас будет результат. Как правило, терабайтная база у вас будет разворачиваться несколько часов. Но в разработке есть патч, у нас возможна серия, т. е. вы можете последовательно на одном и том же сервере использовать ту же самую pgdata и проверять. Postgres будет рестартоваться, кэши сбрасываться. И вы можете гонять нагрузку.

- Приезжает директория, в которой куча всяких файликов, начиная от снапшотов pgstat***. И там самое интересное – это pg_stat_statements, pg_stat_kcacke. Это два расширения, которые анализируют запросы. И pg_stat_bgwriter содержит в себе не только pgwriter статистику, а еще и по checkpoint и по тому, как сами бэкенды вытесняют грязные буфера. И это все интересно посмотреть. Например, когда мы shared_buffers настраиваем, то очень интересно посмотреть, сколько там кто повытеснял.
- Также приезжают логи Postgres. Два лога – лог подготовки и лог проигрывания нагрузки.
- Относительно новая фича – это FlameGraphs.
- Также, если вы использовали pgreplay или pgbench варианты проигрывания нагрузки, то будет родной их вывод. И вы будете видеть latency и TPS. Можно будет понять, как они это видели.
- Информация о системе.
- Базовые проверки CPU и IO. Это больше для EC2 instance в Амазоне, когда вы хотите в потоке запустить 100 одинаковых instances и там прогнать по 100 разных прогонов, то у вас будет 10 000 экспериментов. И вам нужно убедиться, что вам не попался ущербный instance, которого уже кто-то притесняет. На этой железке другие активничают и вам ресурса мало остается. Такие результаты лучше отбросить. И как раз с помощью sysbench от Алексея Копытова мы делаем несколько коротеньких проверок, которые приедут и можно сравнить с другими, т. е. вы поймете, как CPU себя ведет и как IO себя ведет.

Какие есть технические сложности на примере разных компаний?

Допустим, мы хотим реальную нагрузку с помощью логов повторять. Отличная идея, если это на Open Source pgreplay написано. Мы его используем. Но, чтобы он хорошо работал, вы должны включить полное логирование запросов с параметрами и таймингом.
Там есть некоторые сложности насчет duration и timestamp. Мы эту кухню всю опустим. Главный вопрос – можете ли вы себе такое позволить или не можете?

https://gist.github.com/NikolayS/08d9b7b4845371d03e195a8d8df43408
Проблема такая, что это может быть недоступно. Вы должны прежде всего понять, какой поток будет в лог писаться. Если у вас есть pg_stat_statements, вы можете вот таким запросом (ссылочка будет в слайдах доступна) понять, сколько примерно байт будет писаться в секунду.
Мы смотрим на длину запроса. Мы пренебрегаем тем фактом, что там нет параметров, но мы знаем длину запроса и знаем, сколько раз в секунду он выполнялся. Таким образом мы можем прикинуть, сколько примерно байт в секунду. Мы можем ошибиться раза в два, но порядок мы точно поймем таким способом.
Мы можем увидеть, что 802 раза в секунду этот запрос выполняется. И мы видим, что bytes_per sec – 300 kB/s будет писаться плюс минус. И, как правило, мы такой поток можем себе позволить.

Но! Дело в том, что есть разные системы логирования. И по умолчанию у людей обычно «syslog».
И если у вас есть syslog, то у вас может быть вот такая картинка. Мы возьмем pgbench, включим логирование запросов и посмотрим, что получается.

Без логирования – это столбик слева. У нас получались 161 000 TPS. С syslog – это в Ubuntu 16.04 в Амазоне у нас получается 37 000 TPS. А если мы изменим на два других способа логирования, то намного лучше ситуация. Т. е. мы ожидали, что просядет, но не настолько же.
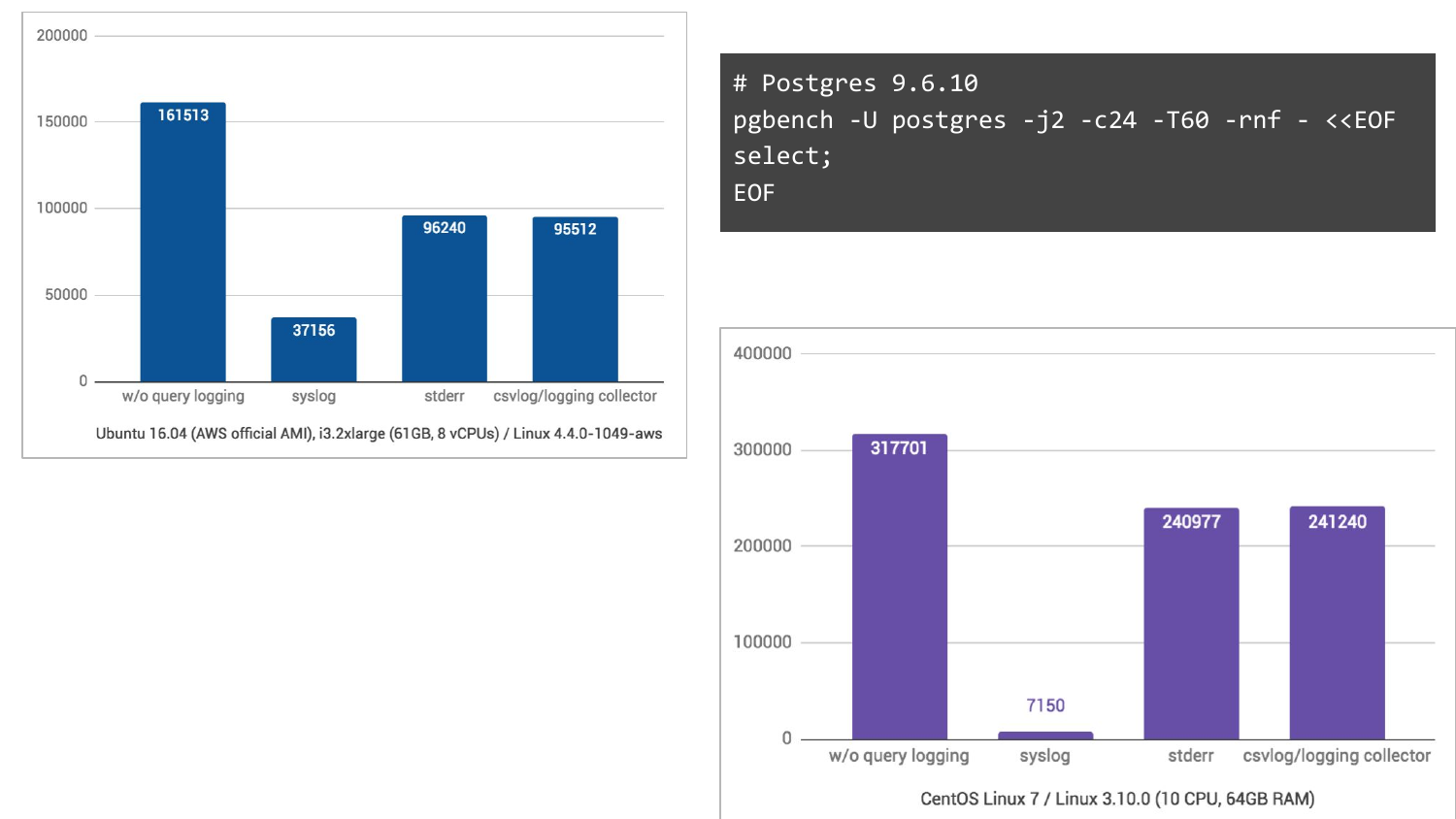
А на CentOS 7, в котором еще journald участвует, превращая логи в бинарный формат для удобного поиска и т. д., то там вообще кошмар, в 44 раза проседаем по TPS.
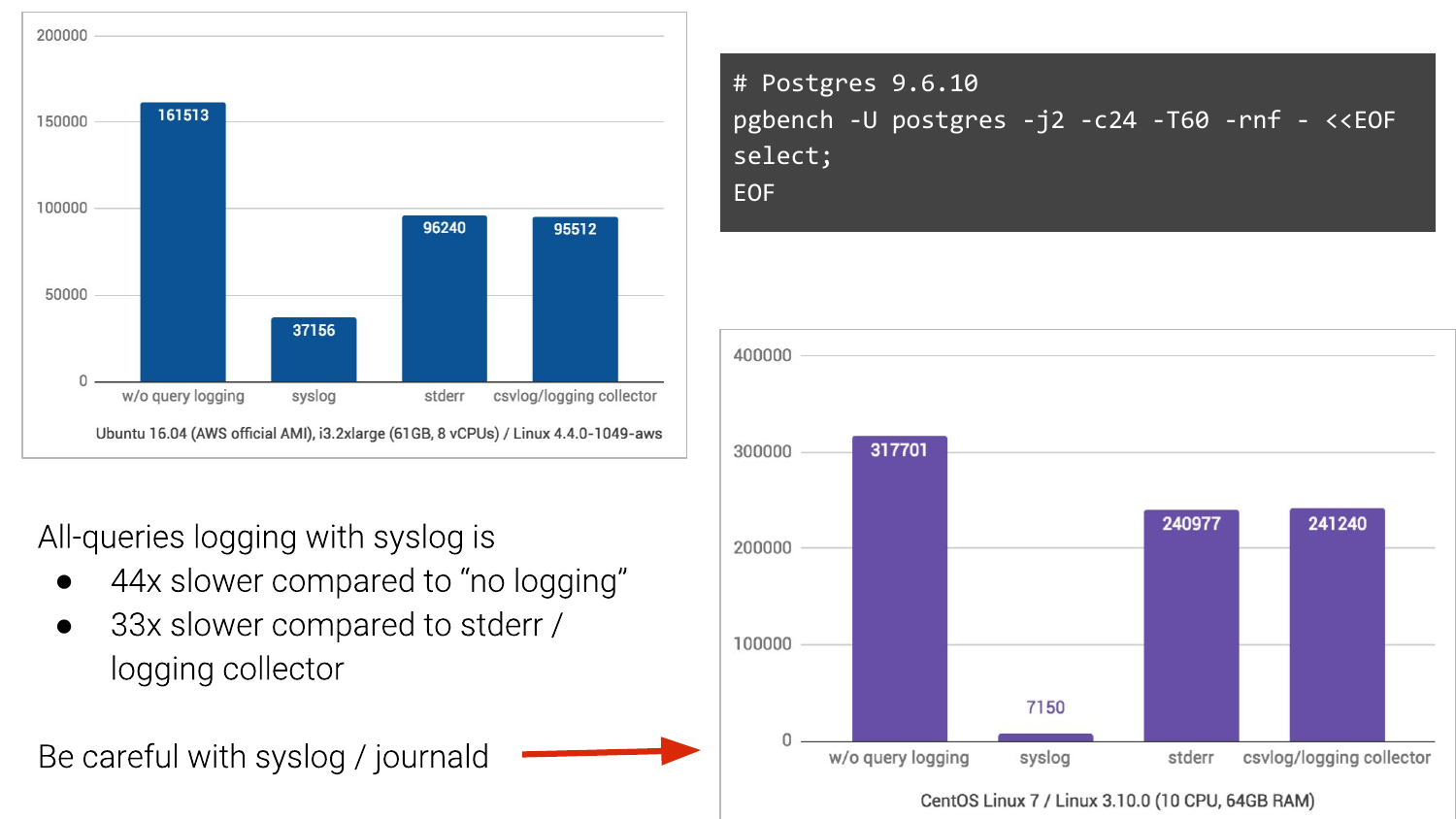
И это то, с чем живут люди. И часто в компаниях, особенно в крупных, это очень сложно поменять. Если вы можете уехать от syslog, то, пожалуйста уезжайте от него.

- Оцените IOPS и поток записи.
- Проверьте свою систему логирования.
- Если прогнозируемая нагрузка чрезмерно велика, рассмотрите вариант с сэмплированием.

У нас есть pg_stat_statements. К��к я сказал, он обязательно должен быть. И мы можем взять и каждую группу запросов специальным образом описать в файлике. И дальше можем использовать очень удобную фичу в pgbench – это возможность подсунуть несколько файликов с помощью опции «-f».
Он понимает много «-f». И можно сказать с помощью «@» в конце, какая доля у каждого файлика должна быть. Т. е. мы можем сказать, что вот это исполняй в 10 % случаях, а этот в 20 %. И это будет приближать нас к тому, что мы видим на production.

А как мы поймем, что у нас на production? Какая доля и чего как? Тут немножко уход в сторону. У нас есть еще один продукт postgres-checkup. Тоже база в Open Source. И мы сейчас активно его развиваем.
Он родился немного по другим причинам. По причинам того, что мониторинга недостаточно. Т. е. вы приходите, смотрите на базу, смотрите на проблемы, которые есть. И, как правило, вы делаете health_check. Если вы опытный DBA, то вы делаете health_check. Посмотрели использование индексов и т. д. Если у вас OKmeter, то отлично. Это классный мониторинг для Postgres. OKmeter.io – пожалуйста, ставьте его, там очень классно все сделано. Он платный.
Если у вас его нет, то, как правило, у вас мало, что есть. В мониторинге обычно есть CPU, IO и то с оговорками, и все. А нам нужно больше. Нам нужно видеть, как работает автовакуум, как работает checkpoint, в io нужно отделить checkpoint от bgwriter и от бэкендов и т. д.
Проблема в том, когда ты помогаешь какой-то крупной компании, они не могут что-то быстро внедрить. Не могут быстро купить OKmeter. Может быть, через полгода купят. Н�� могут быстро поставить какие-то пакеты.
И у нас родилась идея, что нам нужен такой специальный инструмент, который не требует ничего в установке, т. е. вы вообще ничего не должны ставить на production. Ставите себе на ноутбук, либо на observing server, откуда вы будете запускать. И он будет анализировать много чего: и операционную систему, и файловую систему, и сам Postgres, делая какие-то легкие запросы, которые можно гонять прямо на production и ничего не ляжет.
Мы назвали его Postgres-checkup. Если по-медицински, то это регулярная проверка здоровья. Если в автомобильной тематике, то – это как ТО. Вы ТО делаете у машины каждые полгода или год, в зависимости от марки. А делаете ли вы ТО для своей базы? Т. е. делаете ли вы глубокое исследование регулярно? Его надо делать. Если вы делаете бэкапы, то делайте и checkup, это не менее важно.
И у нас есть такой инструмент. Он начал активно зарождаться только месяца три назад. Он еще молодой, но там много чего есть.

Собираем самые «влиятельные» группы запросов – отчет К003 в Postgres-checkup
И там есть группа отчетов К. Три отчета пока. И есть такой отчет К003. Там верхушка от pg_stat_statements, отсортированная по total_time.
Когда мы сортируем по total_time группы запросов, то на верхушке мы видим такую группу, которая грузит нашу систему наибольшим образом, т. е. потребляет большее количество ресурсов. Почему я называю группы запросов? Потому что мы параметры выкинули. Это уже не запросы, а группы запросов, т. е. они абстрагированные.
И если мы будем оптимизировать сверху вниз, мы будем облегчать наши ресурсы и откладывать момент, когда нам будет надо делать апгрейд. Это очень хороший способ сэкономить деньги.
Может быть, это не очень хороший способ в качестве заботы о пользователях, потому что мы, может быть, не видим редкие, но очень досадные случаи, когда человек ждал 15 секунд. В сумме они такие редкие, что мы их не видим, но зато мы ресурсами занимаемся.

Что случилось в этой таблице? Мы сделали два снапшота. Postgres_checkup вам сделает дельту по каждой метрике: по total-time, calls, rows, shared_blks_read и т. д. Все, дельту вычислил. У pg_stat_statements большая проблема в том, что он не помнит, когда был reset. Если pg_stat_database помнит, то pg_stat_statements не помнит. Вы видите, что там 1 000 000 число, а откуда мы считали, мы не знаем.

А здесь мы знаем, здесь у нас есть два снапшота. Мы знаем, что дельта была в этом случае 56 секунд. Очень небольшой промежуток. По total_time отсортировали. И дальше мы можем дифференцировать, т. е. мы все метрики делим на duration. Если мы каждую метрику разделим на duration, у нас будет количество вызовов в секунду.
Дальше total_time per second – это моя любимая метрика. Она измеряется в секундах, в секунду, т. е. сколько секунд потребовалось нашей системы на выполнение этой группы запросов в секунду. Если вы видите там больше секунды в секунду, это означает, что больше одного ядра вам нужно было дать. Это очень хорошая метрика. Вы можете понять, что этому товарищу, например, нужно минимум три ядра.
Вот это наше ноу-хау, я такого нигде не видел. Обратите внимание – это очень простая вещь – секунда в секунду. Иногда, когда у вас CPU 100 %, то полчаса в секунду, т. е. вы полчаса занимались только этим запросов.
Дальше мы видим rows в секунду. Мы знаем, сколько строк в секунду вернула.
И дальше тоже интересная вещь. Сколько мы shared_buffers в секунду прочитали из самого shared_buffers. Хиты уже были там, а ряды мы взяли из кэша операционной системы, либо из диска. Первый вариант быстрый, а второй, может быть, быстрым, а может быть и нет, от ситуации зависит.
И второй способ дифференцирования – мы делим количество запросов в этой группе. Во второй колонке у вас всегда будет один запрос разделить на запрос. А дальше интересно – сколько миллисекунд было в этом запросе. Мы знаем, как в среднем ведет себя этот запрос. 101 миллисекунда требовалось на каждый запрос. Это традиционная метрика, которая нам нужна для понимания.
Сколько строчек каждый запрос вернул в среднем. Мы видим 8 эта группа возвращает. Сколько в среднем из кэша взялось и прочиталось. Мы видим, что все закэшировано классно. Сплошные хиты для первой группы.
И четвертая подстрока в каждой строчке – это сколько процентов от общего количества. У нас есть calls. Допустим, в 1 000 000. И мы можем понять, какой вклад эта группа вносит. Мы видим, что в данном случае первая группа вносит вклад меньше, чем 0,01 %. Т. е. она такая медленная, что мы ее не видим в общей картине. А вторая группа – 5 % по вызовам. Т. е. 5 % из всех вызовов – это вторая группа.
По total_time тоже интересно. На первую группу запросов мы потратили 14 % всего времени работы. А на вторую – 11 % и т. д.
Я в детали не буду углубляться, но там есть тонкости. Мы сверху выводим ошибку, потому что, когда мы сравниваем, снапшоты могут поплыть, т. е. какие-то запросы могут выпасть и во втором уже не могут не присутствовать, а какие-то могут новые появиться. И мы там высчитываем ошибку. Если вы видите 0, то это хорошо. Это ошибок нет. Если показатель ошибки до 20 %, это ОК.

Дальше мы возвращаемся к нашей теме. Мы должны закрафтить workload. Мы берем сверху вниз идем, пока не наберем 80 % или 90 %. Обычно это 10-20 групп. И делаем файлики для pgbench. Там используем random. Иногда это, к сожалению, не получается. И в Postgres 12 будет больше возможностей такой подход использовать.
И дальше мы таким образом набираем 80-90 % по total_time. Что дальше подставлять после «@»? Мы смотрим на calls, смотрим, сколько процентов и понимаем, что мы вот здесь должны столько-то процентов. Из этих процентов мы можем понять, как балансировать каждый из файликов. После этого мы используем pgbench и поехали работать.

Есть еще у нас К001 и К002.
К001 – это одна большая строка с четырьмя подстроками. Это характеристика всей нашей нагрузки. Смотрите вторую колонку и вторую подстроку. Мы видим, что полторы секунды в секунду примерно, т. е. если будет два ядра, то будет хорошо. Будет примерно 75 % загрузка. И это будет так работать. Если у нас будет 10 ядер, то мы вообще будем спокойны. Так мы можем ресурсы оценивать.
К002 – это я называю классы запросов, т. е. SELECT, INSERT, UPDATE, DELETE. И отдельно SELECT FOR UPDATE, потому что он лочит.
И здесь мы можем сделать вывод, что SELECT обычные читающие – 82 % от всех вызовов, но при этом – 74 % по total_time. Т. е. они много вызываются, но поменьше потребляют ресурс.

И возвращаемся к вопросу: «Как нам правильно подобрать shared_buffers?». Я наблюдаю, что большинство бенчмарков строятся на идее – давайте посмотрим, какой throughput будет, т. е. какой будет пропускная способность. Она в TPS обычно измеряется или QPS.
И мы стараемся выжать от тачки с помощью параметров от тюнинга как можно больше транзакций в секунду. Здесь как раз 311 в секунду для select.

Но никто не ездит на работу и обратно домой на машине на полной скорости. Это глупо. Так и с базами данных. Мы не должны ездить на полной скорости, да никто этого и не делает. Никто не живет в production, у которого 100% CPU. Хотя, может, кто-то и живет, но это нехорошо.
Идея такая, что мы ездим обычно процентах на 20 от возможности, желательно не выше 50 %. И мы стараемся время отклика оптимизировать для наших пользователей прежде всего. Т. е. мы должны наши ручки крутить так, чтобы было минимальное latency при 20%-ой скорости, условно. Это такая идея, которую мы тоже стараемся использовать в наших экспериментах.
И в завершении рекомендации:
- Обязательно сделайте Database Lab.
- По возможности сделайте on demand, чтобы разворачивалось на какое-то время – поиграли и выбросили. Если у вас облака, то это само собой, т. е. имейте много standing.
- Будьте любознательными. И если что-то не так, то проверяйте экспериментами, как оно себя ведет. Nancy можно использовать, чтобы обучать себя, чтобы проверять, как работает база.
- И прицеливайтесь на минимальное время отклика.
- И не бойтесь исходников Postgres. Когда вы работаете с исходниками, вы должны знать английский. Там очень много комментариев, там все объяснено.
- И проверяйте здоровье базы регулярно, хотя бы раз в три месяца руками, либо Postgres-checkup.

Вопросы
Спасибо большое! Очень интересная штука.
Две штуки.
Да, две штуки. Только я не совсем понял. Когда мы с Nancy работаем, мы только один параметр можем подкручивать или целую группу?
У нас дельта-конфиг параметр. Вы можете туда сколько угодно сразу крутануть. Но надо понимать, когда вы меняете много всего, вы можете неправильные выводы сделать.
Да. Почему я спросил? Потому что сложно проводить эксперименты, когда у тебя есть только один параметр. Ты его подкручиваешь, посмотрел, как работает. Выставил его. Потом следующий начинаешь.
Можно одновременно подкручивать, но зависит от ситуации, конечно. Но лучше одну идею проверять. У нас вчера возникла идея. У нас была очень близкая ситуация. Было два конфига. И мы не могли понять, почему большая разница. И возникла идея, что нужно использовать дихотомию, чтобы последовательно понять и найти в чем отличие. Можно сразу половину параметров сделать одинаковыми, потом четверть и т. д. Все гибко.
И еще есть вопрос. Проект молодой, развивается. Документация уже готова, есть подробное описание?
Я там специально ссылку сделал на описание параметров. Это есть. Но много чего нет еще пока. Я ищу единомышленников. И я их нахожу, когда выступаю. Это очень круто. Кто-то уже со мной работает, кто-то помог и что-то там сделал. И если вам интересна эта тема, дайте обратную связь – что не хватает.
Как сделаем лабораторию, может быть, будет обратная связь. Посмотрим. Спасибо!
Здравствуйте! Спасибо за доклад! Я увидел, что есть поддержка Амазона. Планируется ли поддержка GSP?
Хороший вопрос. Начали делать. И пока заморозили, потому что мы хотим экономить. Т. е. есть поддержка с помощью run on localhost. Вы можете сами создать instance и работать локально. Кстати, так мы делаем. В Getlab я так делаю, там на GSP. Но делать именно такую оркестрацию мы пока не видим смысл, потому что у Google нет спотов дешевый. Там есть ??? instances, но у них ограничения. Во-первых, у них всегда только скидка в 70 % и там нельзя поиграть с ценой. Споты мы увеличиваем на 5-10 % цену, чтобы понизить вероятность, что вас кильнут. Т. е. споты вы экономите, но у вас могут в любой момент забрать. Если вы немножко цену выше, чем у других делаете, вы будете попозже убиты. У Google совсем другая специфика. И еще очень нехорошее ограничение есть – они только 24 часа живут. А иногда мы хотим 5 дней гонять эксперимент. Но спотах это делать можно, споты иногда месяцами живут.
Здравствуйте! Спасибо за доклад! Вы упомянули про checkup. Как вы высчитываете ошибки stat_statements?
Очень хороший вопрос. Я могу очень подробно показать и рассказать. Коротко – мы смотрим, как поплыл набор групп запросов: сколько отвалилось и сколько новых появилось. И дальше мы смотрим две метрики: total_time и calls, поэтому там две ошибки. И смотрим, какой вклад у поплывших групп. Там две подгруппы: уехавшая и приехавшая. Смотрим, какой у них вклад в общую картину.
А вы не боитесь, что она там провернется два-три раза за время между снапшотами?
Т. е. они заново зарегистрировались или как?
Например, этот запрос один раз уже вытеснился, потом пришел и снова вытеснился, потом еще раз пришел и снова вытеснился. И вы тут что-то посчитали, и где это все?
Хороший вопрос, надо смотреть.
Я аналогичную штуку делал. Попроще, конечно, я делал ее один. Но мне пришлось сбрасывать, сделать reset stat_statements и ориентироваться в момент снапшота, что там меньше определенной доли, что все равно не дошло до потолка, сколько там stat_statements может накопить. И я ориентируюсь, что, скорее всего, не вытеснилось ничего.
Да-да.
Но как по-другому сделать достоверно я не понимаю.
Я, к сожалению, точно не помню – используем ли мы там текст запроса или queryid с pg_stat_statements и на него ориентируемся. Если мы ориентируемся на queryid, то по идее, мы сравниваем сравнимые вещи.
Нет, он же может вытесниться несколько раз между снапшотами и приехать опять.
С этим же id?
Да.
Мы это поизучаем. Хороший вопрос. Надо изучить. Но пока то, что мы видим, у нас либо 0 пишется…
Это, конечно, редкий случай, но меня тряхануло, когда я узнал, что stat_statemetns там может вытеснить.
В Pg_stat_statements может быть много чего. Мы сталкивались с тем, что если у вас track_utility = on, то у вас сеты тоже трекаются.
Да, конечно.
И если у вас java hibernate, который рандомный, то там начинается лочится хеш-таблица. И как только вы отключаете очень нагруженное приложение, у вас становится 50-100 групп. И там более-менее стабильно все. Один из способов борьбы с этим – это pg_stat_statements.max увеличить.
Да, но надо знать, насколько. И как-то за ним надо следить. Я так и делаю. Т. е. у меня есть pg_stat_statements.max. И смотрю, что я на момент снапшота не дошел процентов 70 %. Хорошо, значит, мы ничего не потеряли. Делаем reset. И копим снова. Если в следующем снапшоте меньше 70, то значит, скорее всего, снова ничего не потеряли.
Да. По умолчанию сейчас 5 000. И очень многим этого хватает.
Обычно – да.
Видео:
P.S. От себя добавлю что если в Postgres находятся конфедициальные данные и им нельзя попадать в тестовое окружение, то можно воспользоваться PostgreSQL Anonymizer. Схема примерно следующая:


