
Хабр Курсы для всех
РЕКЛАМА
Практикум, Хекслет, SkyPro, авторские курсы — собрали всех и попросили скидки. Осталось выбрать!
А если чуть-чуть накинуть памяти? Например, если нужно 18Гб памяти.
Время выполнения на celeron-300 24Гб памяти — 2 дня 30 минут.
Время выполнения на m1 — бесконечность.
(чем меньше, тем лучше)
Я к тому, что эппл срезала угол, который считалось всегда плохо срезать — расширяемая память. Более того, срезала довольно низенько (я как раз себе домашнюю машину подбираю и в глубоких сомнениях — 1x32 или 2x16 в свете 4х слотов и возможного апдейта в будущем...).
Ну вот как раз разработчикам 16GB мало.
Смотря каким разработчикам и чего. Я вот добавил 16 Гб к имеющимся 16 только когда начал локально запускать кластеры на десятки сервисов и пяток СУБД.
плюс эмуляторы девайсов.с эмуляторами андроид девайсов наверняка станет получше — всё-таки apple silicon это ARM.
А почему синкпад, а не xps?
Спасибо)
Толстенный такой)
Дизайн — субьективно, понимаю. О клаве xps ничего плохого не слышал.
О клаве xps ничего плохого не слышал.
Она какая-то неполноценная. На Thinkpad t15p клавиатура занимает всё доступное ей место, даже цифровой блок влез. На XPS 15 же по 3-4 см слева и справа пустого места, как будто взяли клаву от 10-12" нетбука. В итоге PgUp/PgDown/Home/End — только через Fn. Ну и стрелки, к которым невозможно привыкнуть. Короче, XPS сразу в помойку, не глядя — это не ноутбук для программиста.
даже цифровой блок влез
оу. А зачем он? Без этого блока у вас клавиатура используется симметрично относительно центра экрана. С же ним руки будут лежать больше в левой плоскости.
На XPS 15 же по 3-4 см слева и справа пустого места, как будто взяли клаву от 10-12" нетбука. В итоге PgUp/PgDown/Home/End — только через Fn
Как на маке (:
Не, ну есть же компромиссные варианты, например, MSI PS63 15" — дополнительный ряд справа для клавиш навигации. Раньше ASUS примерно так же клавиши располагал.
Как на маке (:
И? Там вся экосистема под такую раскладку заточена.
даже цифровой блок влез
оу. А зачем он?
В итоге PgUp/PgDown/Home/End — только через Fnтем не менее уж лучше через fn+стрелки, чем когда backspace/delete/home/end в радиусе миссклика от кнопки выключения. Лишь бы сами стрелки были удобными (вот прям не нравится мне вверх/вниз половинчатой высоты при полной высоте вправо/влево).
И? Там вся экосистема под такую раскладку заточена.сомнительный аргумент. Вам всё равно как программисту нужны кнопки а-ля «переход в начало/конец строки» и иже с ними.
тем не менее уж лучше через fn+стрелки, чем когда backspace/delete/home/end в радиусе миссклика от кнопки выключения.
Эта проблема решается нормальной реализацией кнопки выключения, а не удалением "ненужных" кнопок.
Что до нампада — никогда не пользовался им на ноуте и имо лучше без него
Согласен. Но без клавиш навигации ещё хуже.
Согласен. Но без клавиш навигации ещё хуже.скажем так: меня не особо смущало fn+стрелочки вместо отдельных кнопок home/end, прожимать привык быстро. Другое дело что в macos home/end имеют несколько иной смысл и кидают не в начало/конец строки, а в начало/конец текста. В IDE'шке настроил конечно же, в других приложухах до сих пор не могу привыкнуть к такому поведению
Дурная, да. Но я и не сказал "всем разработчикам". Из моих знакомых разработчиков большинство в 16GB уже упирались, кто-то добавил памяти, кто-то нет. В целом проблема в том, что проекты только добавляются, равно как и их требования. Всё в облаке гонять не получается, уж точно не на любом проекте. Иногда нужны виртуалки. Иногда поднять тяжёлые сервисы. Иногда кучку браузеров. Смотря чем разработчик занимается и в какой области. Но в целом, если смотреть в исторической перспективе, требования к памяти на машине разработчика только растут, причём довольно быстро. И они всегда были выше, чем к машине обычного юзера, раза в полтора-два где-то минимум. Соответственно я к этому отношусь как к тезису про бэкапы "те, кто не делают, и те, кто УЖЕ делают" — "те, кому 16GB пока ещё хватает, и те, кому УЖЕ не хватает", вот и всё.
Статья пытается оценивать применимость для разработчиков — я именно с этой точки зрения и комментировал, что ограничение в 16GB для этой целевой аудитории очень некстати. А то, что бывают разработчики, которым 16GB ПОКА хватает — я и не спорю. Просто высока вероятность, что скоро и они упрутся в 16GB, и вот тогда этот M1 сильно их огорчит.
Фаза "16 Гб уже не хватает" не монолитна, есть градации от "не хватает, но терпимо, почти не влияет на производительность и/или мотивацию разработчика" через "сильно не хватает, производительность и/или мотивация разработчика заметно падает" до "заметную часть рабочих задач выполнить невозможно — памяти на билд не хватает, например".
И длина фазы "терпимо" и способ выхода из неё сильно зависят от двух вещей: своя техника или работодатель/заказчик предоставляет и общее мировоззрение по вопросу: можно ли закрывать глаза на неудобства в работе, если их можно избежать регулярной тратой относительно небольших средств (скажем, не более 5% годового дохода) и/или сменой работодателя/заказчика.
Это всё корректно если вырвать фразу из контекста. А у нас тут вполне конкретный контекст: разработчик думает перейти на M1. Это автоматически подразумевает, что он хочет выжать максимальную скорость, т.е. получить максимальный комфорт при разработке. В этой ситуации фаза "не хватает, но терпимо" означает потерю того комфорта, ради которого затевается переход. Поэтому в данном контексте длина этой фазы примерно равна нулю и она сразу переходит в следующую "работать стало некомфортно, нужно обновить железо на более мощное". :)
16Гб памяти не однозначно свидетельствует что уже не хватает, тем более что докера или кубера под М1 пока нет.
Мне вот на текущем проекте должно хватать, если нет особых потребностей у АРМ, типа Хром жрёт в 2 раза больше памяти. На прошлом не хватало 16, но терпимо, если не держать сотню вкладок и 5 IDE открытыми постоянно. Хотя всё равно добавил на личный ноут до 32, когда карантин начался.
Хотя всё равно добавил на личный ноут до 32, когда карантин начался.
Вот я именно об этом. И так делает большинство. И как, лично у Вас есть желание даунгреднуться до 16GB?
P.S. Лично я поставил на себе эксперимент когда упёрся в 16GB и поставил 24GB. Не экономии ради, а просто из любопытства — упрусь/не упрусь. За последние пару лет упёрся только один раз — у меня Gentoo, и он непотребно много жрал памяти при сборке чего-то, вроде chromium. (Решилось сносом chromium, потому что он не только много памяти жрал, но и компилировался уже около 12 часов, а это перебор, мне комп не для того нужен, чтобы хромиум компилировать круглосуточно.) В остальном 24GB лично мне пока вполне хватает, и на виртуалки, и на контейнеры, и на всё остальное.
Я в свой комп воткнул 16 гигов памяти ещё в 2011 году.
Нехватку памяти начал ощущать где-то 2-3 года назад, когда для того, чтобы поиграть в GTA V, приходилось закрывать браузер, ну или задействовать своп.
И это я ещё не затронул рабочие моменты: виртуалочки, IDE, машинное обучение (обучение небольшой нейросетки вообще 10+ гигов может отъесть). Да даже сраный Teams — уже гиг памяти сразу после запуска.
Прямо сейчас эта проблема нивелируется свопом на SSD, но через пару лет потребление памяти софтом будет ещё выше. Короче, в новый комп я бы пихал минимум 32 гига, а лучше 64.
И как, лично у Вас есть желание даунгреднуться до 16GB?
С тех пор я сменил проект и не запускаю локально кластеры. Правда стал запускать Телеграм :) Посмотрел использование прямо сейчас: 20 Гб занято, из них Хромом около 10. Наверное замечу даунгрейд, даже проверю на днях, если найду время новый рабочий ноут засетапить
Вчера кстати запустил docker-Compose на пяток сервисов. Отлично заработал. Ожидал что буду до до марта ждать или неделю с бубном плясать
ARM образы или x86 через эмулятор?
Мне не хватило только один раз, когда пытался подебужить 400К строк генерированного Го-кода. А так норм: GoLand, пара базок, вроде всё более-менее, в своп не выходил при нескольких открытых проектах (что само по себе редкость, хочу заметить, обычно только один проект — просто цепляюсь к дев-стенду). Это на десктопе со стареньким i5 4670K.
А недавно прикупил Макбук про этот, на М1. На самом деле потом куплю машинку помощнее, с микролед (или минилед, смотря что у них будет) с большим объёмом памяти, всё же 16Гб всё равно впритык сейчас.
Ну вот. Штука приятная, мне нравится. Возможность запускать ипадос приложения один раз прямо выручила, производительность, разумеется, очень хорошая — EAP Intellij Ultimate ворочается заметно шустрее чем на старом десктопе. Там, где на нём приходилось ждать, например, переиндексации исходников после перегенерации кода сейчас происходит практически мгновенно. И он очень тихий. Всякий веб-электроновый шлак хоть и медленее натива или иос/ипадос приложений, но всё же заметно шустрее чем на старом линупс-десктопе. Компиляция побыстрее, хотя и не очень разница не такая большая как в вебе.
В общем, неплохая машинка. Когда будут с большим объёмом памяти всё вообще будет шоколадно. Кроме х86_64 приложений в докере через qemu, разумеется )
Хотя, учитывая самый частый юзкейс для разработчиков в использовании докера — гонять там базки, всё не так уж плохо: больших объёмов там нет, просто разработка, отладка. И образы с популярным базками собранными для арм64 так или иначе появятся, поэтому вообще терпимо.
Хотя, учитывая самый частый юзкейс для разработчиков в использовании докера — гонять там базки, всё не так уж плохо
А сам разрабатываемый код, тесты? Хотя, если CI на целевую платформу настроена и базовые образы стэка для ARM есть, то костыльками можно сделать, чтобы локально под МакОсь арм-образы были, когда будет докер под неё.
Суперскалярность, менее строгий доступ к памяти, 8-канальная память.
Осталось подождать, пока найдётся какая-нибудь фундаментальная проблема с безопасностью по типу spectre/meltdown, и костыльный фикс съест весь прирост в производительности.
Так-то оно так, но достаточно один раз продемонстрировать подготовленную атаку на домашний компьютер, чтобы поднялся шум, и Apple была вынуждена применить фикс для всех.
Разумееся, она не является проблемой. Ну и что, что таб с малварной рекламой может прочитать куку от банк-клиента в соседнем табе.
… Не является проблемой.
Простите, вы про какую из атак? Meltdown был вполне быстрый.
https://www.youtube.com/watch?v=RbHbFkh6eeE
Чтение по конкретному адресу. Показывается производительность, достаточная, чтобы спереть известное по известному месту.
Теперь возникает вопрос: а как мы узнаем "где известное"? Правильно, прочитав другое известное. Указатели и т.д. При том, что есть ASLR… Стоп, это же эппл. Может, у них и нету. В любом случае, ASLR ломали с помощью spectre какой-то там вариации, так что это не панацея. Вопрос за сколько хопов можно дойти до "вкусного" — это интересный вопрос для исследования.
Но большинство людей совершенно не удивятся, что у них какой-то из процессов браузера, вдруг, 100% cpu сожрал (и продолжил на другом сайте с продолжением малвари из той же баннерной сети).
Если есть возможность читать любую память то ничто не мешает просто ходить по указателям
Для этого нужно иметь возможность запустить вредоносный код на атакуемой системе. То есть пользователь должен, для начала, поставить себе на компьютер троян.
Есть потенциальный вектор атаки через выполнение JavaScript, но вот возможности читать любую память из него нет, существуют методы борьбы на уровне самого движка JS, поэтому я не верю в возможность стащить куку из браузера таким способом.
Вот вы не верите, а люди, которые патчи пишут, верят. И страдают.
Если совсем не верите, вот вам mlfa: noibrs noibpb nopti nospectre_v2 nospectre_v1 l1tf=off nospec_store_bypass_disable no_stf_barrier mds=off tsx=on tsx_async_abort=off mitigations=off
На ваш страх и риск.
Применил это к своей системе, прогнал тесты из своей статьи: https://habr.com/ru/post/532442/
Результаты оказались идентичными. Возможно, в каких-то сценариях они оказывают эффект, но эти сценарии уж очень редки.
Эм, вы используете его не так. Разница во времени выполнения системных вызовов. Если у вас львиная работа в userspace с агрессивным кешированием, то разницы не будет. Если же у вас сплошные системные вызовы, разница будет очень ощутимой.
Худшее, что я видел в полу-синтетике (это была синтетика, но не для спектре а для другого бенчмарка) — около 20%. При использовании реального железа стало медленее и влияние упало куда-то до 10%.
(Речь про блочное IO).
т.к. на других-то ARM-ах существующих это не так
Так ARM — это просто система команд, а реализация может быть различной.
мне вот почему-то кажется, что там основной профит производительности как раз из-за интегрированной памяти
ну т.е. не верится в то, что просто архитектура ARM vs x86 настолько оптимальнее, т.к. на других-то ARM-ах существующих это не так
интересно, исследует ли кто-то эту гипотезу
Так вот и вопрос, за счёт чего быстрые-то вдруг? Чудес-то не бывает.
По какой причине вам так кажется? Латентность там такая же как и у Интел.
Зато 8 каналов, а не 2.
Память — это лишь один из факторов. Ну и Snapdragon 8cx имеет достаточно неплохую производительность (пока, правда, по заявлениям).
Память — это лишь один из факторов.
Snapdragon 8cx имеет достаточно неплохую производительность
Думаю, в основном ты прав, так как промахи кэша в разы замедляют работу структур на указателях типа деревьев поиска, а однокристальная память должна иметь очень низкую латентность
должна иметь очень низкую латентность
measuring 96ns at 128MB full random test depth, compared to 102ns on the A14.
Вспомнилось про бензопилу и суровых сибирских мужиков
Я просто оставлю это здесь: https://twitter.com/panzer/status/1328700636926332928
И это тоже впечатляет. Впрочем, ничто не мешает процессору Intel ограничить частоту и сделать андервольтинг. Производительность упадёт на 20-30%, зато энергопотребление снизится в разы. Я как-то забыл зарядку для своего ноутбука — в итоге 6 часов программирования в Rider обошлись мне в 60% аккумулятора без особого дискомфорта.
Ну, тут M1 бьёт интел и по производительностью, и по энергопотреблению одновременно, так что интел не может пожертвовать чем-то, чтобы улучшить свои позиции :) хотя, безусловно, тут речь о старых поколениях.
я сосредоточился на тестах реальных задач разработки
И вместе с тем вообще все бенчмарки кроме последнего — это синтетика для серверных задач (который с огромной вероятностью будет x86_64)
Мне кажется секрет в том что по сути «десктопное ядро» запихнули в мобильные устройства, снабдив быстрой памятью. 5нм поспособствовали как снижением энергопотребления, так и большей плотностью. Вопрос теперь что будет на десктопах если учесть что пока еще не было массовых arm с частотой больше ~3ггц. Вполне может получиться что решение масштабируется только вширь через наращивание ядер и никакой революции не случится.
Райзену 3900x уже больше года, было бы актуальнее сравнить с чем-то на zen3. Да и у Интела скоро новое поколение выходит.

Райзену 3900x уже больше года, было бы актуальнее сравнить с чем-то на zen3. Да и у Интела скоро новое поколение выходит.ну нет у человека zen3, что поделать. Так то 3900X всё еще в совершенно другой категории, это же десктопный проц.
Может бэнчи кривые, на гитхабе есть тесты сборок iOS проектов, там mini всегда на 10% бежит быстрее air.ну вообще нет, обычно mini и air бегут наравне в рамках погрешности (я думаю она как раз здесь и влияет), кроме стресс тестов под продолжительной нагрузкой, там air может просесть процентов на 15.
Mac mini 2020 16 GB (Apple M1 8-core) — 116 seconds
Mac mini 2020 16 GB (Apple M1 8-core) — 121 seconds
Mac mini 2020 8 GB (Apple M1 8-core) — 131 seconds
MacBook Pro 13" 2020 16 GB (Apple M1 8-core) — 119 seconds
MacBook Pro 13" 2020 8 GB (Apple M1 8-core) — 121 seconds
MacBook Air 13" 2020 16 GB (Apple M1 8c (8c GPU)) — 128 seconds
MacBook Air 13" 2020 8 GB (Apple M1 8c (7c GPU)) — 137 seconds
MacBook Air 13" 2020 8 GB (Apple M1 8c (7c GPU)) — 134 seconds
MacBook Air 13" 2020 8 GB (Apple M1 8c (7c GPU)) — 130 seconds
Иногда выручает таки возможность полчасика без света поработать.
Он работает от батареи 20 часов 23 минуты. Razer на 5 часов меньше. Да, разница есть, но ее трудно назвать большой.
в среднем под нагрузкой (29 дБ против 32.1 у Apple).
но революцией это назвать язык не поворачивается
Не работает нормально внешний экран — опять же, ноутбук для меня бесполезенА с каких пор внешние мониторы к макам не подключаются?
Я верю, что у кого-то получается работать на 13.3" экранчике, но мне платят гораздо больше и ожидают большей эффективности.
И там же сказано, что достаточно выключить сглаживание шрифтов (библиотека сглаживания не портирована ещё). На экране Macbook или на внешнем 4k мониторе вполне комфортно работается без сглаживания.
Я сейчас использую этот EAP, и он работает на Mac Mini M1 ощутимо отзывчивей, чем на рабочем MBP15 2017 (i7-7700HQ) и домашнем десктопе (i5-6600k).
Да, это немного отличается от того что нам рассказывают всякие «независимые» видеоблоггеры.видеоблоггеры просто говорят что продукты JB пока не адаптированы под M1. Обсуждение которое вы выложили про баги бета версии под M1. А такой лаг, который видно на видео, есть и на intel mac и, полагаю, даже под виндой.
Запустить Intellij IDEA?
Не работает нормально внешний экран — опять же, ноутбук для меня бесполезен. Не работает стабильно Bluetooth мышь или клавиатура?
Не смог запуститься Docker? Зачем лично мне такой ноутбук?
Я верю, что у кого-то получается работать на 13.3" экранчике, но мне платят гораздо больше и ожидают большей эффективности.
но частота обновления составляет всего 30 Гц.
Для работы это не приемлемо.
Apple исправит и даже заменит бесполезный тачбар на нормальные клавиши
Я уже молчу о том, что эмуляция x86 на системе с процессором ARM в разы медленнее. Производительность может быть ниже в 3-5 раз, что тоже неприемлемо.
Но говорить что это плохой ноут потому что он вам не подходит — глупо.
Плохой-хороший — оценки, субъективные по определению. Вы вот сказали, что для вас лучший. Никто же с этим не спорит.
В том-то и дело, что даже если по многим, то не по всем. И то, что важно для вас, например, автономность, для меня значащим фактором выбора становится только при равных важных для меня, типа стабильной работы докера и/или возможности установить линукс без танцев с бубнами. Типа если нет разницы в важных факторах, то пускай будет большая автономность, а если есть, то пускай будет её на полчаса, но чтоб то, что мне дейсттвительно нужно работало стабильно.
Ну да, разница между 15 и 20 часами
так что можно с утречка залипать там в ноут, подключённый к зарядке.
а вот между 30 и 60 — даже на скроллинге текста или обычной работе в IDE легко заметить.
Удивительный фанатизм. Всё, что умеет эппл — неоспоримые, нужные всем преимущества, всё, что не умеет — да это всё не нужно!но… вы же сами сейчас утверждаете, что то, что умеет apple (конкретно более долгое время автономной работы) не нужно, а то, что не умеют (60 fps на некоторых мониторах) — неоспоримое, нужное всем преимущество?
Я не утверждаю, что всё, что умеет apple, не нужно, а всё, что не умеет — нужно.ну да, вы утверждаете что:
Ну да, разница между 15 и 20 часами куда важнее, чем разница между 30 и 60 герцами у экрана. (сарказм, прим.)где… ну давайте постараемся быть объективными — вероятность наткнуться на дисплей BenQ кажется несколько ниже вероятности наткнуться на нехватку батарейки
Не знаю, как вы это оцениваете, но вот мониторы BenQ у меня были на прошлой работе полтора года назад, а на нехватку батареи я натыкался даже не помню когда.ну оценивать мониторы сравнительно легко — речь идет о 4K мониторах BenQ, работающих по thunderbolt. Грубо говоря, это пересечение ~26% доли thunderbolt-мониторов, ~15% доли рынка BenQ и ~40% доли рынка 4K мониторов. То есть скажем для трех случайных мониторов хотя бы один будет проблемным с вероятностью сильно ниже 5%, и это по верхней границе оценок.
Если нет, то апостериорная вероятность нарваться на монитор с thunderbolt куда ближе к 100%и даже в этом случае вероятность наткнуться на проблемный монитор сравнима с погрешностью оценки оной. И даже если вы на него наткнетесь, софтовый фикс (вроде как) уже есть. В общем, не стоит раздувать из мухи слона. И наоборот, как вы пытаетесь преуменьшить значимость автономности, тоже не стоит
Без гирлянд из переходников, конечно же.Кабель, у которого на одном конце USB type C, а на другом, скажем, HDMI, а не второй USB type C — это уже гирлянда, или ещё нет?
Я не утверждаю, что всё, что умеет apple, не нужно, а всё, что не умеет — нужно.
Что касается батареи, то производители ноутбуков стараются увеличить время жизни
Ну да, заметно: вместо увеличения ёмкости аккумуляторов производители уменьшают габариты и вес ноутбуков, при этом под нож идёт клавиатура и порты, которые больше не помещаются в корпусе.
Ну да, заметно: вместо увеличения ёмкости аккумуляторов производители уменьшают габариты и вес ноутбуковкак будто вес и габариты не важны для мобильного устройства.
при этом под нож идёт клавиатура и порты, которые больше не помещаются в корпусе.а казалось бы еще вчера народ жаловался про вырезанные VGA и CD-ROM…
Что касается батареи, то производители ноутбуков стараются увеличить время жизни, потому как ноутбуки созданы чтобы быть мобильными.
Мобильность и автономность немного разные понятия. Десктоп на прошлом проекте был нифига не мобильным, но автономность около часа была. А ноутбук личный мобильный, но под нагрузкой автнономность около получаса.
Удивительный фанатизм.
что не умеет — да это всё не нужно
но вот мониторы BenQ у меня были на прошлой работе полтора года назад
У меня за полтора года работы на машине с пингом в десяток мс не адаптировался.
Кстати, сколько процентов людей действительно требует 15- или 20-часовой работы от батарей?ну например мой юзкейс — летом люблю иногда поработать снаружи, а вот таскать в офис зарядку не люблю (заряжаю по thunderbolt). В итоге моя работа снаружи ограничена автономностью ноута в весьма интенсивном режиме работы (clion + огромный проект + браузер). И ноут, способный продержаться так часов пять, вместо пары, точно бы не повредил.
Кстати, сколько процентов людей действительно требует 15- или 20-часовой работы от батарей?
О, что вы, никаких гуёв. ssh и vim внутри.
А можно теперь что-нибудь такое про linux + x11 + nvidia-drivers + konsole в нём?
«А для остального вообще разницы нет»
Я тоже не использую ноуты как десктопы, но потребности в десятках часов без батареи не было.
Интересно, что эти же люди говорят, что «да беспроводные наушники, которые надо заряжать раз в 4-8 часов, норм».
прошло 29 мс, до появления символа — ещё 8 мс.
я не смог найти ноут с ryzen 7 4xxx и IPS и разрешением больше full hdУ вас, наверное, ещё какие-то требования кроме упомянутых? Размер экрана, например? Потому что вот у меня ноутбук с 1440р и, вроде бы, IPS Правда, с Ryzen 9, но это потому что я хотел и выжидал R9, R7 при этом в свободной продаже были.
Я искал именно 7, потому что это прямой конкурент M1, а ноуты типа которых вы скинули живут при аналогичной нагрузке в 2 раза меньше
сильно дороже и вообще не в категории условных эйров.Ну, вот у вас и нарисовались не названные ранее параметры.
Вообще есть 1 ноут c 1440p и ryzen 7 но это этот зефир, который сильно дорожеТам листалка вправо есть на странице спеков, вы её потыкали? Там много таких.
А вообще я так понял это какая-то модификация TN с маркетинговым название EWVСудя по постам в интернете и обзору на NotebookCheck, в одной и той же модели и комплектации может стоять и IPS, и WV. У меня на коробке указан WQHD WV.
Что значит не названые, я же написал «Ryzen 7 4xxx и IPS» в первом сообщении, какой параметр я утаил?Вот эти:
живут при аналогичной нагрузке в 2 раза меньше
сильно дороже
на хотлайне
в Украине
те обзоры где указывают модель матрицы, которые я нагуглил, указывают одну и ту же EWV/LTPS матрицу.Это обзоры конкретной комплектации с R7?
Проблема в том что для матрицы 1440p есть спеки, которые выглядят весьма подробно и в них нет никаких IPSА есть другие, в которых IPS есть. Причём, вы ссылаетесь на обзоры, в которых прямом текстом пишут «IPS», но вы не верите, и специально ищете такие спеки, в которых написано что-нибудь другое.
Фулл хд матрицу (LM140LF-1F01) вообще не могу нагуглить, но есть на том же сайте, похожая по номеру и параметрам (ссылка).Интересное у вас «не могу нагуглить». У меня первая же ссылка ведёт на спеки, причём, ссылку я эту уже приводил, и там написано «Optical Technology: IPS». Вы же, зачем-то, вместо спецификации на матрицу смотрите «матрицы с похожим номером» и ссылаетесь на их тип.
Я ничего не ищу, эти ссылки — первые по запросу B140QAN02.3.А по запросу «AUOE68C» будут другие.
хммм, кому же мне доверить, сайту на котором 30 параметров описано для другой матрицы или 3, но для нужной.Исправил вас, не благодарите.
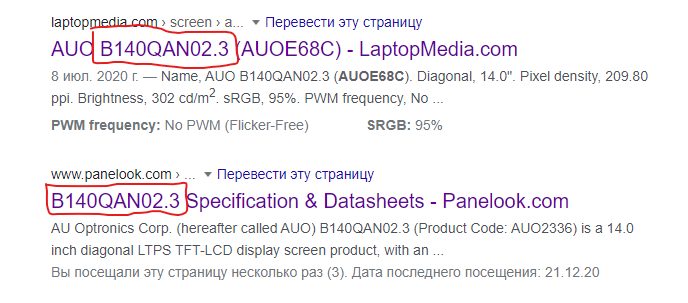 сООвсем другая матрица.
сООвсем другая матрица.Разница: вторая ссылка для 2017 модели, первая для 2019. Это в принципе не важно так как тесты всё равно скорее всего проводились для 2019, что означает что скорее всего (из-за того что характеристики и углы плохие) особо ничего не поменялось, особенно технология.Это всё про картинку, или что? Если про неё, то по верхней ссылке будет написано IPS. Ещё вопросы?
Я живу в Украине, мне ноуты искать в США, Китае, или раше?В мире. Вы так написали, будто их не существует вообще. И да: кто-то и с Амазона заказывает, и с Computeruniverse. И в Россию, и в Украину.
Смотрел и к сожалению по фоткам не возможно увидеть если ли искажения цветов под углами.Теперь вам уже и IPS не годится? Вот прямо в спекшите для запчасти указанный?
Для чистоты картины нужно на оба Linux поставить и сравнить. Я вот жду таких сравнений чтобы серьёзно задуматься о покупке. Всё равно МакОсь так только, поиграться с ней "нужна".
Забыл добавить "мне", сорри.
Я про свой комментарий https://habr.com/en/post/533232/#comment_22442508
но тот же Razer Book 13 работает примерно столько же, если верить измерениям Notebookcheckа если верить другим измерениям, то в полные 2.5 раза меньше. При этом даже в некоторых не оптимизированных под ARM задачах M1 заметно шустрее, ну и дальше целый список по мелочи — разрешение выше, динамики субъективно сильно лучше, палитра лучше (это заметно прям в обзоре), само собой тачпад. Уступает MBP только в скорости чтения с SSD, не намного, но заметно. И M1 MBP еще и дешевле.
придется покупать новые устройства на М1Потом придётся. Пока что интел-варианты не только поддерживаются, но и даже продаются.
Сервера на АРМ уже есть. Рабочие станции — очень широкое понятие. Корпсектор тоже: одни с XP сидят, у других все на маках кроме бухглатерии )
По производительности аналогичные решения от AMD в полтора раза быстрее.
iPhone 6s и далее поддерживают iOS 14.
Последним XCode собирать можно приложения с минимальной целевой версией iOS 9: https://developer.apple.com/support/xcode/
Хотя я не понимаю конечно чего все удивляются? Компания самая богатая в мире, инженеров у неё толковых хватает.
В ее силах вполне успешно можно сделать хороший процессор. Я бы больше удивился если бы они его не сделали.
Где-то сейчас грустит один Intel :)
Что значит 8 и 4 инструкции за такт? Количество инструкций (точнее, uOps) за такт в идеальном случае равно длине конвейера (если нет stall'ов). Согласно wikichip у Ice Lake (у того же Tiger нет ещё информации) это 14-19 стадий конвейера.
L2 общий только для производительных CPU ядер. Под ним ещё уровень кэша, который как раз общий с GPU и всеми остальными блоками, и уже через него идёт доступ в память. Anandtech пишет об этом, хотя и без подробностей
Кажется, написал фигню. Похоже, это кэш для SSD.
В случае с М1 мы имеем 8Мб кеша второго уровня для 4 больших ядер и 4 Мб для маленьких.
Самое забавное, что латентность L2 кеша на M1 выше чем L3 на ZEN 3 — 96.83 нс против 78.87 нс на full random.
L2 кеш на Zen 3 имеет в 8 раз меньшие задержки — около 10нс, а L2 кеш на Zen 3 работает примерно на скорости L1 кеша М1. Задержки L1 для Zen 3 составляют около 1.6нс.
Иными словами, в плане скорости работы с памятью Zen 3 гораздо лучше.
У них есть кастомные регистры. Также, у них есть переключатель режима работы с памятью для ускорения работы Rosetta 2.
Слышал (на youtube канале) что лицензия у Apple позволяет это делать.
Мне, как конечному пользователю всё равно,
Вы слышали что-то не то. Допускается такое только в M-профайле.кажется, не совсем: "Arm Custom Instructions are a standard feature of the Armv8-M architecture, in particular the Arm Cortex-M33 CPU, which is optimized for cost and power-sensitive microcontrollers for embedded and IoT applications". Выглядит так, словно это фича лицензии на Armv8-M архитектуру либо лицензии на ядро cortex-M33, и насколько я понимаю, у apple есть та самая лицензия на архитектуру.
От того что к «универсальному» процессору добавлены команды, он не становится менее «универсальным».вопрос наверно в том, весь ли спектр ARM инструкций поддерживается в apple silicon. По идее конечно же должен, но мало ли, вдруг через пару лет весь андроид мир будет использовать кастомные расширения от qualcomm, например.
Проблема в том, что новые команды из новых ревизий архитектуры могу занять опкоды, которые используются для поддержки кастомных инструкций «без спроса». И это сломает совместимость.там разве не отдельный диапазон выделен под кастомные инструкции?
Выглядит так, словно это фича лицензии на Armv8-M архитектуру
вопрос наверно в том, весь ли спектр ARM инструкций поддерживается в apple silicon.
Думаю, поймать эти различия ещё нужно постараться, а сами они будут багами.
За добавление поддержки Apple M1 и адаптацию всей инфраструктуры клиенты платить не станут.
За поддержку Apple x86 бывало платили, когда понимали, что это позволит сделать проект более привлекательным для кандидатов.
Нет, ещё потому что клиент хочет, чтобы этот разработчик работал на него. Даже при найме клиенты бывают пересматривают различные политики на проекты, когда не могут уговорить подходящих по скиллам специалистов принять оффер.
Если они смогут на нем макпро выкатить в течении года после объявления, который будет сравним с рязанькой 4хххH и при этом энегроэффективнее. Тогда я просто офигею) Потому что сделать эффективнее на малых частотах — это одно (особенно, когда сравнивают с интелом, которые немного отстал). А вот после задрать частоты и нарастить ядра, но при этом не уйти в кипятильник — это другое. Далеко не факт, что это легко будет сделать уже имея отличный смартфонный проц.
Ну там 2600s в ноуте тысяч за 100
Ну тогда 16 гигов оперативы давайте… а, их в РФ не заявлено на сайте эпла, максимум 8/512
Это неправда. Выбираете модель и дальше настраивается всё.
Это у них считается разными "базовыми моделями", хотя различие, не устраняемое конфигуратором, есть только в GPU у Air. Маркетинговые заморочки.
А цены на технику Apple в России действительно немного безумные, тут сложно спорить.
А цены на техникуAppleв России действительно немного безумные, тут сложно спорить.
По моим прикидкам приблизительные аналоги по ТТХ ("белые", от сопопоставимого по известности и "крутости" вендора) стоят плюс-минус столько же или даже заметно дороже, если прямого аналога (с 17" дисплеем, например), нет, но вариант должен быть не хуже.
Честное сравнение будет M1 vs Ryzen 5900X vs i9 10900K.ноутбучный процессор с потреблением порядка 30 Вт против десктопных с потреблением до 160/250 ватт соответственно? Честное сравнение.
openbenchmarking.org/result/2012212-HA-APPLEM1PR00чет прям очень удивительный набор результатов. Один из процов «VirtualApple @ 2.40GHz (8 Cores)», то есть эмулированный через rosetta2, а остальные три выдают практически идентичные результаты в большинстве бенчмарков. А в некоторых кейсах он даже выигрывает относительно других M1. Складывается впечатление, что весь набор тестов не адаптирован под apple silicon. По крайней мере другие одноядерные веб бенчмарки обычно дают очень существенный перевес в пользу M1.
Да, можно вспомнить о том, что Ryzen 7 5800X потребляет до 125 Вт, но через две недели должны выйти мобильные чипы Ryzen 7 5800H и Ryzen 7 5900HS с 45 и 35 Вт TDP со схожими частотами и производительностью.пока что про 5800H мы знаем только его 1475/7630 очков в geekbench 5, что в общем случае не бьет результаты M1. Хотя остается вопрос в каком профиле сделан замер — если это при работе от батареи, то результат конечно же очень впечатляет.
На данный момент по данным 73 бенчмарков М1 в среднем в три раза медленнее чем 5800XНу бенчмарки типа «oneDNN 2.0 Harness: Recurrent Neural Network Training — Data Type: u8s8f32 — Engine: CPU» (нейронки, вычисляемые на CPU) можно смело игнорировать. Тем более если они опять вычисляются через rosetta2.
Да, вы можете возразить, что в М1 есть аппаратный блок для работы с видео, но в этом случае М1 имеет смысл сравнивать с системами со схожим аппаратным блоком.
Radeon 5700XT
Эти тесты показывают производительность процессора во вполне реальных задачах.вы действительно считаете вычисление нейронки на CPU через rosetta2 «реальной задачей»? Напомню, что в M1 есть neural engine, специально заточенный под нейронки вычислительный блок. И в по-настоящему реальных задачах использоваться будет именно он.
Особо интересны результаты кодирования H.265 видео силами CPU Kvazaar 2.0, где Ryzen в среднем в 6 раз быстрее.это тоже без аппаратного ускорения и через rosetta2? Очень «реальная» задача.
Об этом маленьком обстоятельстве многие честные блогеры предпочитают умолчать. Удобно ведь сравнивать программное декодирование или совершенно никакой аппаратный декодер в Vega с таковым в M1.так ведь это и есть реальная задача — декодирование видео так, как это делают пользователи, т.е. с аппаратным ускорением?
Да, вы можете возразить, что в М1 есть аппаратный блок для работы с видео, но в этом случае М1 имеет смысл сравнивать с системами со схожим аппаратным блокома этот аппаратный блок есть в ноутбуках с актуальными 1185G7/4800U? Или что, раз в M1 есть neural engine, надо сравнивать его с железом, заточенным под вычисление нейронок, например серваком с восьмью tesla V100?
Если сравнить М1 с Intel Core i7 1165G7, то процессор Intel на 30% быстрее: openbenchmarking.org/vs/Processor/Apple%20M1,Intel%20Core%20i7-1165G7опять через rosetta2?
По поводу стоит ли учитывать результаты теста oneDNN, то почему бы и нет? Он показывает насколько процессор хорошо справляется с большим количеством простых операций, а также в приложениях, которые не умеют задействовать Neural Engine.потому что у 99% реальных пользователей никогда не будет таких сценариев?
Что касается Rosetta, то она обеспечивает прирост в среднем 15-25%не прироста а просадки, и она может превосходить и 50% в зависимости от юзкейсов. В большинстве случаев rosetta2 дает просадку в 20-40%. А если бы M1 еще и через эмуляцию уделывал intel/AMD, то нам с вами и обсуждать было бы нечего.
Если рассматривать серьезную работу с САПР, 3D-рендерингом и Machine Learning, то здесь Apple M1 вообще не вариант. Большая часть подобного софта оптимизирована под nVidia, производительность там гораздо выше.то есть всё это будет считаться на GPU, а не на CPU через слой трансляции, да? Я вам больше скажу, если рассматривать ML, то еще лучше будет комбинация сервер + тонкий клиент. А в качестве тонкого клиента для подключения к серверу macbook air на M1 как раз таки замечательно подходит.
Если спуститься на уровень обычного пользователя, то современные видеокарты умеют аппаратно декодировать AV1, чего нет в М1вау, круто. Где я могу купить ноутбук с такой видеокартой?
Большинство тестов запускалась нативно. Для этого просто достаточно сопоставить значения с другими обзорами (на Phoronix, например).почему тогда все результаты этих тестов с точностью до погрешности совпадают с «VirtualApple @ 2.40GHz (8 Cores)», который свидетельствует как раз об использовании rosetta2?
Если запустить PHPBench 0.8.1 через Rosetta 2, то производительность будет не 525 тысяч баллов, а около 420. В Kvazaar 2.0 Boshporus 1080p Medium будет не 5.2, а 4.6. На пресете Very Fast будет не 14.1, а 12.75.ну вы приведите тогда ссылки на эти результаты.
В общем, тесты по ссылке выше вполне объективно отображают текущее состояние вещейесли, конечно же, все эти запуски нативные, однако я уже привел факты это опровергающие. Привел дважды, между прочим.
Разница в производительности при использовании Rosetta 2 около 15-25%*в конкретном юзкейсе. На самом деле достаточно всего лишь глянуть на страничку на основании которой был сделан этот вывод и отлистать вниз, чтобы увидеть и примеры где rosetta2 почти не влияет, и те, где разница 40+%
Что касается AV1, то ноутбуков с Intel Tiger Lake сейчас очень много, включая упомянутые ранее Razer Book 13 и Dell XPS 9310.ну вместо любого из этих ноутов M1 макбук берется без раздумий — он выдает примерно тот же перф с автономностью выше в полтора-два раза. С 4800U хотя бы поразмышлять можно, он хотя бы в многопотоке обходит M1.
К слову, из-за этого некоторые программы не работают через Rosetta 2
Из-за этого никакие приложения не ломаются. Далеко не все x86 CPU имеют поддержку AVX, поэтому абсолютно все приложения делают фолбеки.
Стоит также упомянуть, что эти инструкции придумали не просто так, они позволяют достичь куда большей производительности на современных x86 процессорах.
А на ARM придумали другие инструкции, и их никакие из этих "тестов" не используют.
В случае с FLAC хорошо видно, что там есть фоллбек с AVX на SSE, а вот веток с NEON/AMX нет, поэтому через Rosetta производительность в несколько раз выше, чем в нативно-собранной версии.
Что касается самих тестов, то они вполне объективны.
Они объективно меряют запуск конкретных неадаптированных приложений под транслятором. К сравнению производительности CPU это не имеет отношения.
Из тех приложений, которыми я пользуюсь, остался непортированным только торрент-клиент, который я не хочу на бету обновлять по отдельным причинам, и Sublime Text, в котором я не знаю, где искать тормоза.
Никого ведь не смущает тот факт, что Geekbench оптимизирован под ARM.
Вас не смущает, что там даже Geekbench запускается x86 версия под Rosetta, когда ARM версия была готова ещё до поставки реальных устройств?
Спасибо за редкий пример, где разработчики просто забили на совместимость внутри x86 мира. Такое ещё бывает с некоторыми играми.
Пользователям свежих гибридных Lakefield (а также последних Pentium Silver, и всех Atom), наверное, очень обидно.
Инструкции AVX используются в очень многих современных приложениях, начиная с продуктов Adobe с дополнениями и заканчивая всякими там Python и Java.NEON тоже дофига где используется, но ни один из приведенных вами бенчмарков этого не отражает. Зато они отражают нерелевантные, по вашим же словам, юзкейсы.
Что касается самих тестов, то они вполне объективны. Никого ведь не смущает тот факт, что Geekbench оптимизирован под ARM.код, который нативно работает под M1, тоже оптимизируют под ARM. И его производительность никак не коррелирует с производительностью AVX под rosetta2.
Да, действительно, NEON используется во многих приложениях для смартфонов, но среди десктопных приложений — это огромная редкость.yet. Автовекторизацию никто не отменял (да, для этого надо лишь пересобрать), SIMD-библиотеки, поддерживающие NEON, никто не отменял, библиотеки, поддерживающие NEON вручную никто не отменял…
Что касается производительности AVX, то она примерно в 2.8 раза выше чем у обычных SSE/SSE2чет этот пассаж противоречит лично моему опыту написания SIMD кода. Обычно AVX дает порядка 80% над SSE3, при условии сравнительно линейного алгоритма.
которые по своей сути являются аналогом NEON.вы думаете ARM не умеет в 256-битные регистры и шире?
Она не работает дальше тривиальных примеров, да и на них не работаетесли она работает на x86, то высоковероятно отработает и на NEON, при сборке под ARM таргет. Я вполне натыкался на код с заанроленными циклами чтобы компилятору было проще догадаться до автовекторизации, иногда используются всякие pragma omp и пр. Часть кода попросту перепишут руками, часть кода уже умеет в NEON, и надо лишь пересобрать.
Ну я взял и написал: https://github.com/Viknet/counting-chars/tree/neon
Сразу скажу, что до этого ничего никогда с векторными инструкциями не делал, выдал то, что изучил за вечер.
Из интересных результатов:
clang -O3 с AVX работает быстрее, чем написанная вручную SSE4.2;-O3 ничего не автовекторизируется, и вообще не ускоряется относительно -O2 при любых флагах и модификаторах архитектуры;Да не вопрос. Но я уверен, что это далеко не оптимальный вариант — я просто сделал кальку с sse версии, используя те инструкции, что нашёл, не пытаясь подбирать количество линий в итерации, высчитывать такты инструкций и т.д.
Ну и собирал я всё под clang — gcc под m1 пока нет — поэтому может потребоваться немного напильника.
Если сравнить 1165G7 с M1, то М1 существенно быстрее (>10%) в 7 приложениях, Intel — в 18. Если проанализировать данные, то получится, что Intel в среднем на 20% быстрее.я с тем же успехом могу сейчас накидать сравнений M1 против того же 1165G7 в исполнении ARM кода. Спойлер: М1 будет быстрее.
Нет, вы можете, конечно сколько угодно цитировать Apple с их «М1 быстрее чем 98% ноутбуков», но реальность совершенно другая.вам накидать замеров в реальных юзкейсах, типа монтажа видео (всё еще через rosetta2, кстати)?
Да, приведите тесты, где М1 куда быстрее чем Tiger Lake.geekbench 5? Cinebench r23 (multicore)?
Если речь идет о монтаже видео, то там используется аппаратный декодер, а не процессор как таковой.ага, только этот аппаратный декодер является частью проца, и реальный код его использует для ускорения пользовательских задач. Или у вас AVX это тоже аппаратный блок а «не процессор как таковой»? Чего тогда ваши бенчи отражают быстродействие второго но не первого?
Что касается самого теста Geekbench, то он в целом оптимизирован под ARM. Это проявляется в том, что даже в пятой версии использование SSE/AVX инструкций там очень ограничено.где в ARM версии GB5 используется NEON там, где в x86 не задействован SSE/AVX? яили в SIMD можно только x86 процам, иначе «ничесна»?
Если рассматривать систему в целом, то ноутбук с весьма старой по нынешним меркам видеокартой GeForce GTX 2060 кодирует видео примерно в 3 раза быстрее в Premier Pro: youtu.be/W82KrjnPaZc?list=LL&t=323adobe premiere pro не оптимизирован под M1. Это даже говорит обзорщик в видео по вашей же ссылке.
AVX инструкции активно используются в тестах AES-XTS, Machine Learning, а также в нескольких других.и эти тесты входят в набор тестов гикбенча. Так почему вы тогда пытаетесь доказать что гибкенч дает преимущество ARM процессорам, приводя пример обратного?
Что касается прямого сравнения AVX и NEON, то они отличаются количеством обрабатываемых данныхДля справки: NEON не ограничен 128-битными операциями, и масштабируется вплоть до, емнип, 2048 бит.
Отсюда и возникает различие в 2.8 раза между 128-битными SSE/NEON и AVX.еще раз, вы в реальных задачах никогда не получите такого увеличения производительности. Например, обращение к младшим 128-битным частям ymm/zmm дороже чем прямое обращение к xmm. Но, подозреваю, это вам ни о чем не говорит.
А это упирается ещё и в возможности ALU/FPU, а не в систему команд. Если FPU 128-битный, и он только один, то команда, оперирующая 2048-битными данными, будет выполняться в 16 раз медленее аналогичной команды, работающей с 128-битными данными.
Например, обращение к младшим 128-битным частям ymm/zmm дороже чем прямое обращение к xmm.
Поясните. Если вы имеете в виду работу с младшими 128 битами с сохранением старших бит, тогда да, это дорого.
А это упирается ещё и в возможности ALU/FPUx87 FPU уже давным давно устарел и полностью заменен на SSE. Насколько я в курсе, SIMD операции в x64 выполняются на 64-битных арифметических блоках, и действительно можно упереться в число одновременно доступных, но их число расширяется условно линейно и я не вижу причин почему это бы ограничивало ARM больше, чем x64.
Поясните. Если вы имеете в виду работу с младшими 128 битами с сохранением старших бит, тогда да, это дорого.в том числе
x87 FPU уже давным давно устарел и полностью заменен на SSE.
А SSE — это уже не FPU?
Насколько я в курсе, SIMD операции в x64 выполняются на 64-битных арифметических блоках
По-моему, уже давно на 256-битные и в Intel, и в AMD. Был поначалу период, когда 128-битные блоки объединялись для выполнения AVX команд, сейчас они полноценные 256-битные, причём для выполнения и 64-битных, и 128-битных команд блок задействуется целиком.
о их число расширяется условно линейно и я не вижу причин почему это бы ограничивало ARM больше, чем x64.
Вопрос в целесообразности и востребованности в разработке процессора с 16+ FPU-блоков на ядро.
По-моему, уже давно на 256-битные и в Intel, и в AMDвы немного о другом, SSE/AVX содержат не только операции с плавающей точкой. Да, с последних пор «честные» 256-битные регистры есть и у AMD, но это не значит, что задача а-ля «перемножить попарно 8 double'ов» делается в одном физическом блоке.
причём для выполнения и 64-битных, и 128-битных команд блок задействуется целиком«ширина» команды ведь определяется адресуемыми регистрами. Ну, если говорить о всяких vmulpd, например.
Вопрос в целесообразности и востребованности в разработке процессора с 16+ FPU-блоков на ядро.вот мы уже имеем на рынке ядра на ARM и x86 со сравнимой производительностью. Почему вы думаете что на какой-то архитектуре делать N арифметических блоков целесообразнее, чем на другой? Ну, есть конечно hyperthreading, но в этом контексте он скорее против x86 играет.
Если рассматривать систему в целом, то ноутбук с весьма старой по нынешним меркам видеокартой GeForce GTX 2060 кодирует видео примерно в 3 раза быстрее в Premier Pro:
Лихо вы новейшее поколение доступных в ноутбуках карточек записали в "весьма старые по нынешним меркам", и проигнорировали тот факт, что сравнивается дискретная карта со встроенной, при разнице энергопотребления почти на порядок.
Так-то встройка из M1 даже в этих неоптимизированных приложениях выглядит эпическим вином для холодного ультрабука.
Видеокарты Turing были представлены более двух лет назад. 2060 по меркам нынешнего поколения Ampere — это карта начального уровня.
И ничего новее пока в ноутбуках нет. Только ещё более мощное и жручее, того же поколения.
По поводу разницы энергопотребления, то для всего ноутбука она примерно соответствует разнице в производительности — около 30 Вт у Apple против около 92 Вт у Asus G14 с 4900HS + 2060.
Скорее, 150 vs 30 для этих ноутбуков. 
И сама карта может потреблять от 100 до 185 Вт в пике, в зависимости от нагрузки и конфигурации питания ноутбука.
GPU в M1 потребляет 10 Вт под нагрузкой.
Да, это несколько больше 10 Вт, о которых вы говорите.
Я говорю про потребление именно GPU.
Что касается значений от 100 до 185 Вт — то это максимальные значения для всего ноутбука. В среднем там около 121-147 Вт под нагрузкой.
Да, то что это не только GPU, мне было непонятно из графиков. Можем принять "бумажный" TDP от NVidia — 80-90 Вт. Что и составляет почти порядок разницы с M1 GPU.
Уровень производительности старенькой 2060 в играх, задачах машинного обучения и обработки видео в несколько раз выше чем у М1.
Потому что M1 сделан для холодных ультрабуков, которым надо долго работать от батарейки. И в этой нише он сейчас не имеет конкурентов по производительности.
То, что его вообще начали сравнивать с дискретными видеокартами и десктопными процессорами с кардинально другими энергобюджетами — уже должно о чём-то говорить.
Что касается мобильных видеокарт Ampere, то они будут анонсированы в начале января.
Когда появятся в продаже — тогда будет иметь какой-то смысл сравнивать. А пока есть то что есть.
Вы сравниваете потребление только GPU с потреблением всего ноутбука с GeForce GTX 2060.
Нет, этого я не делаю. Цифры 100-180 Вт я признал ошибочными в прошлом же ответе.
Условная мобильная GeForce GTX 3060, которую должны анонсировать через две недели будет ещё в 1.5 раза производительнее при схожем энергопотреблении.
И это тоже будут (когда-нибудь) ноутбуки другого класса, для людей с другими требованиями к автономности (и нагреву).
Это я к тому, что для тех кому нужна производительность устройства на М1 в принципе не нужны.
Смотря какая производительность. Монтировать 4k-видео без лагов и шума вентиляторов уже хватает, чего нельзя сказать ни про какую другую встройку.
А для тех, кому нужно больше, девайсы ещё просто не обновились — M1 для самых младших моделей.
Что касается ультрабуков, то есть Razer Book 13, который обеспечивает схожие потребительские качества и при этом не имеет проблем с софтом.
Потребительские качества у него куда хуже, это даже любители Razer признают.
А я указывал вам раз за разом, что отзывчивость «системы» нифига не умение в одной ядро посчитать одну задачуа я утверждаю что та самая отзывчивость зависит от однопоточной производительности больше, чем от многопоточной.
Только проблема, у меня вот фоном десятки приложенийэто уже определяет отзывчивость в конкретно вашем случае. Не надо подменять понятия, раз уж пытаетесь меня за это драконить.
Это по вашему нереальные юзеркейсы или как?как вы думаете, многие играются на рабочих компах?
Или реальные кейсы только у вас, как обычно?напомните мне пожалуйста, где я что-то утверждал про свои юзкейсы?
это уже определяет отзывчивость в конкретно вашем случае.
Я бы сказал, что это типовой случай со времён выхода Windows 3.0, а то и раньше. Отзывчивость в режиме "запущен только UI" мало кого интересует.
как вы думаете, многие играются на рабочих компах?
С марта — многие :)
Я бы сказал, что это типовой случай со времён выхода Windows 3.0, а то и раньше. Отзывчивость в режиме «запущен только UI» мало кого интересует.вы прекрасно понимаете о чем я. Висящий в фоне и простаивающий софт (коего большинство) больше всего влияет на потребление оперативы.
в том случае, когда вас интересует умение решить задачу в один поток, игнорируя, что мир многопоточен уже десятки лет. И даже, о боже, многие программы научились не виснуть гуем, пока тяжелую задачу в другой поток лупят.я повторю вопрос, от которого вы уже несколько раз уклонялись. Вы хоть раз разрабатывали многопоточные приложения?
Причём, если бы кто запустил сжатие базы фоном, а сам сидел играл в солитёр на маке или ютубчик в браузере смотрел — это бы показало, что вероятно претензии к отзывчивости весьма не обоснованы. Но вы предпочли именно подмену одного явления другим.вот здесь есть демонстрация с кучей фоновых приложений. Или вот здесь. Вам сойдет за пруф? Или доказательства по вашей же избранной методологии вам не хватит?
Сейчас я вам покажу многзадачность. Ну как сейчас, когда дискетка отформатируется.
Да нет, отзывчивость — это именно умение системы реагировать на действия пользователя в целом, а не скорость решения конкретной задачи.
Вот как раз с дискеткой отзывчивость была нулевая в win+dos, система почти не реагировала на действия пользователя при работе с дисководом, хорошо если курсор мыши двигался — она, кажется, вообще в real режим переключалась для работы c дисководом через BIOS и блокировала всё остальное. На этой задаче многозадачность превращалась в однозадочность, какой быстрый проц в однопотоке не был.
Бенчмарки Apple M1 в реальной разработке