In some projects, the build script is playing the role of Cinderella. The team focuses its main effort on code development. And the build process itself could be handled by people who are far from development (for example, those responsible for operation or deployment). If the build script works somehow, then everyone prefers not to touch it, and noone ever is thinking about optimization. However, in large heterogeneous projects, the build process could be quite complex, and it is possible to approach it as an independent project. If however you treat the build script as a secondary unimportant project, then the result will be an indigestible imperative script, the support of which will be rather difficult.
In the previous post we looked at what criteria we used to choose the toolkit, and why we chose gradle/kotlin, and in this post we will take a look at how we use gradle/kotlin to automate the build of non-JVM projects. (There is also a Russian version.)

Introduction
Gradle for JVM projects is a universally recognized tool and does not need additional recommendations. For projects outside of the JVM platform, it is also used. For instance, the official documentation describes usage scenarios for C++ and Swift projects. We use gradle to automate the build, test, and deployment of a heterogeneous project that includes modules in node.js, golang, terraform.
Using git submodule to organize an integration build
Each module of a large project is developed by a separate team in its own repository. At the same time, it would be convenient to work with a large project as a whole system:
- provide uniform settings for projects,
- perform integration testing,
- perform deployment in various configurations,
- issue consistent releases,
- centralize configuration,
- etc.
It is quite convenient to connect project repositories to a single repository using git submodule. In the very same moment we can work with one single crosscutting version of all subprojects. Each subproject will be checked out at a certain commit. In the case of implementing functionality that affects multiple subprojects, we can create a branch in the top-level project and specify the sub-branch to use for each subproject. Thus, it is possible to develop and test this new functionality in a coordinated manner without interference from other functionality being developed concurrently.
Deployment uses the name of the top-level project branch to identify the resources that belong to that branch. This identification scheme allows us to automatically delete all related resources immediately before deleting the branch.
A quick overview of how gradle works
Initialization phase. Gradle first searches for settings.gradle.kts, compiles and executes it to find out the list of subprojects and where they are located. Gradle compiles only changed files on an as needed basis. If the file and dependencies are not changed, then the latest compiled version will be used.
Configuration phase. Build scripts are identified for all projects and some of them executed (only those projects that are needed for the target tasks).
The main representation model of the assembly system is a directed graph without cycles (DAG). The nodes of the graph are tasks, between which dependencies are established. Some of the dependencies are derived by gradle using the task properties (for more information, see below). The task graph is overall similar to the structure used in make.
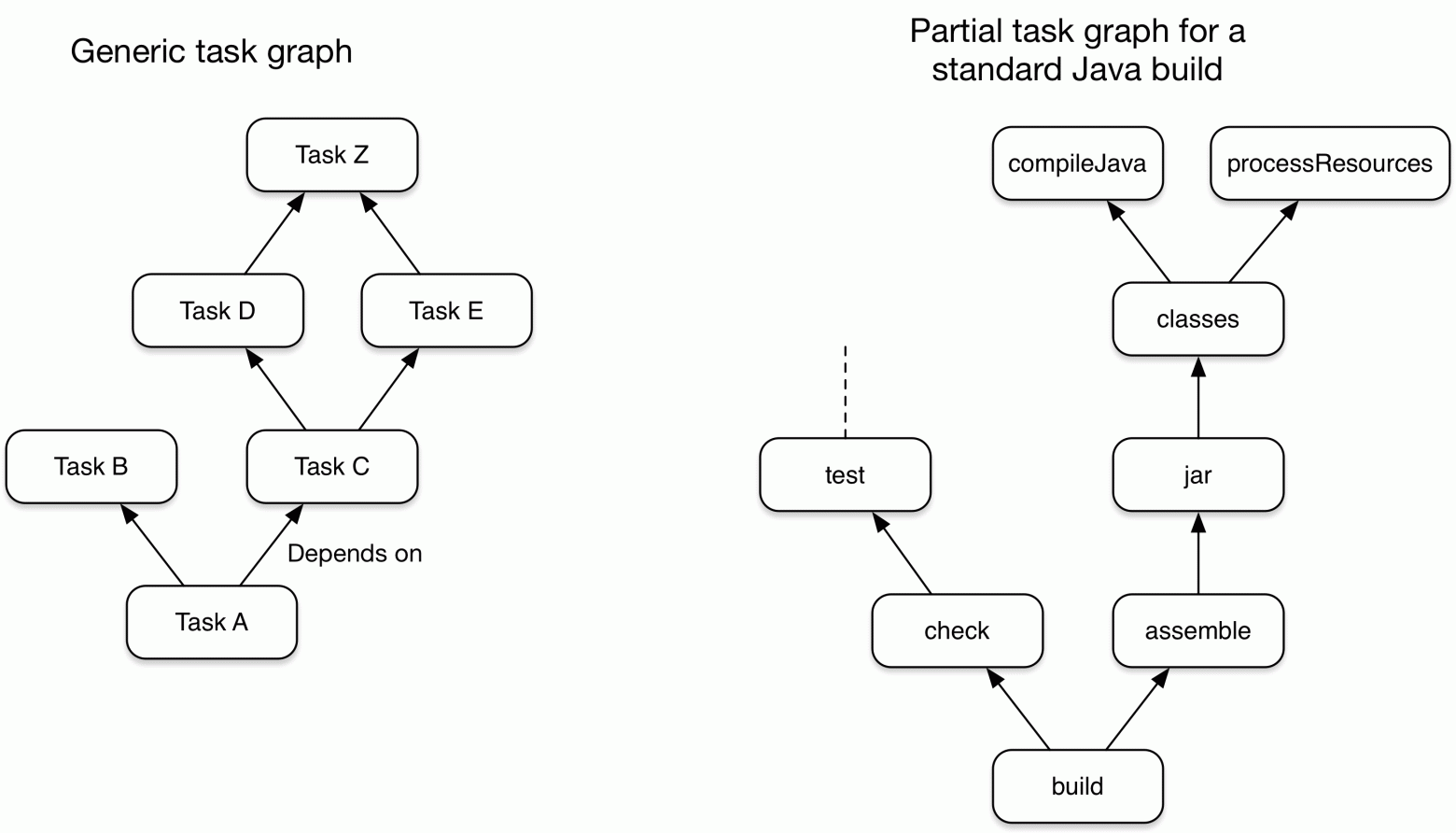
Execution phase. Based on the constructed partial graph of dependencies between tasks, a subgraph is determined that is necessary to achieve the goals of the current target tasks. For each task the up-to-date condition is checked, whether the task should be executed or not. And then only the tasks that are absolutely needed are executed.
The build script that is based on the task graph alone is a hard-to-maintain imperative script. In order to organize similar sets of tasks related to different modules, gradle has the concepts of projects and plugins. A project is a module that represents part of the source code of a larger project, and a plugin is a reusable set of interrelated tasks that are instantiated for a specific project. Similar concepts exist in maven.
DSL (domain-specific language)
Gradle uses a flexible approach to the organization of the build script based on the idea of an embedded domain specific language. In the host language (Groovy or Kotlin), functions, objects, and classes are designed in a special way so that when they are used, easily perceived scripts are obtained, similar to the declarative description of the project. That is, despite of the fact that the build script is an imperative program, it can look like a declarative description of the configuration of plugins and the structure of the project.
This approach is both the strength/convenience of gradle and the vulnerability to overuse of imperative capabilities. At the moment, it looks like the only remedy is self-discipline.
General considerations on best practices of using gradle/kotlin
Built-in project buildSrc
Setting up a project build is mostly done in the script build.gradle.kts. Among other things, this script allows you to create ad-hoc tasks and execute arbitrary code. If you do not commit to self-discipline and follow the recommendations, the build script quickly turns into spagetti code. Therefore, creating tasks and using executable code inside the build script should be considered an exception and a temporary solution, and everyone should remember that supporting a build project with imperative logic in build scripts is extremely difficult.
Gradle offers a super convenient convention with an auxiliary project buildSrc. This project might be considered as the main place for imperative logic and user tasks. The buildSrc project is compiled automatically and added as a dependency to the build script. So everything that is declared in it will be available for use in scripts without additional effort.
Only declarative elements should remain in the build script, such as declaration of plugins, plugin configurations, and project settings.
The buildSrc project is an old boring JVM project. It contains the usual code, one can add resources, write tests, and implement whatever logic is needed for the build scripts. This buildSrc project also has it's own build script and we could refer to this as a "recursive build". The main result of building of this helper project is the classes that will be automatically appended to the classpath of all projects. That is, if you declare a plugin in buildSrc, then this plugin can be used in all projects and subprojects without additional configuration.
It should also be noted that buildSrc does not contain scripts that will be executed in the configuration phase. That is, if you need to create some tasks, you need to call the code. Either by calling a function directly, or by using a plugin (in the latter case the apply (Project) method will be invoked).
Plugins
For different types of projects (go, node.js, terraform, ...) it makes sense to create plugins. Existing plugins (for example, kosogor for terraform) can be used, but those plugins might miss some features.
A plugin can be implemented directly in the buildSrc, or as a separate project for reuse. If separate projects are used, then either you need to connect these projects as an included build, or publish artifacts in a deployed repository (Artifactory, Nexus).
The plugin can be considered as a set of the following elements:
- declarative configuration;
- script/procedure for creating tasks based on the configuration;
- the possibility of a singleton attachment to a separate project and it's configuration.
A simple plugin might look like this:
open class MyPluginExtension(objects: ObjectFactory) { val name: Property<String> = objects.property(String::class.java) val message: Property<String> = objects.property(String::class.java) init { name.convention("World") message.convention(name.map{"Hello " + it}) } } class MyPlugin: Plugin<Project> { override fun apply(target: Project) { val ext = target.extensions.create("helloExt", MyPluginExtension::class.java) target.tasks.register("hello-name"){ it.doLast{ println(ext.message.get()) } } } }
Some inconvenience of plugins is the need to create both tasks and extensions (configuration objects) at the time of the plugin application. Only after that, you can configure the plugin. This procedure is not very convenient, because at the time of creating the tasks, the configuration is still missing. Therefore, we have to use a more involved mechanism of properties and providers. They allow you to operate on future values that will be available only in the execution phase. (See below for more information about properties.) At the same time, it is important to not use the property values at the configuration stage, since they will have the default values (configured in convention statements).
Custom DSL
In addition to the plugins themselves, a similar result could be achieved simply by calling functions that create tasks.
As an example, you can take a look at how tasks are being added in kosogor library with the help of a DSL.
terraform { config { tfVersion = "0.11.11" } root("example", File(projectDir, "terraform")) }
The external function terraform looks like an extension for the type Project:
@TerraformDSLTag fun Project.terraform(configure: TerraformDsl.() -> Unit) { terraformDsl.project = this terraformDsl.configure() }
That is, the code that the user writes inside {} will be executed on an object of the type TerraformDsl. For example, method root creates tasks using the configuration and the name passed to the method:
@TerraformDSLTag fun root(name: String, dir: File, enableDestroy: Boolean = false, targets: LinkedHashSet<String> = LinkedHashSet(), workspace: String? = null) { val lint = project!!.tasks.create("$name.lint", LintRootTask::class.java) { task -> task.group = "terraform.$name" task.description = "Lint root $name" task.root = dir } // ... }
Using methods in Kotlin that take the last parameter of a function of the type Type.()->Unit, allows you to create a DSL that looks quite elegant and convenient. To some extent this provides more flexibility and convenience than plugins. For example, when the 'root' method is running, the previous 'config' method has already been completed and all configuration parameters are available directly. However, we may lose the features provided by the properties (see below).
Tips&tricks
Why is it important to achieve incremental build?
A project build can be invoked hundreds of times a day. Any superfluous work that the build script performs could result in a noticeable loss of time. In extreme cases, when the build process takes 10-30 minutes, the work becomes significantly more difficult and irritating. If the build is performed in the cloud and the result needs to be deployed in several configurations, then the long-term operation of the script can also lead to the increased costs.
The "incrementalness" property does not appear by itself. The build becomes more incremental when all tasks support this property. Ideally, if we trigger the same gradle command once again, it should complete in a fraction of a second, because all tasks will be skipped.
Automatic dependencies between tasks based on properties and files
If task B depends on the result of task A, then you can configure these tasks in a such a way that gradle could guess that you need to perform task A, even without explicitly specifying the dependency.
To achieve this, gradle provides a mechanism of properties and providers (in other languages/systems, one could use monads in a similar way). (The mechanism is similar to the "settings" in sbt.) At the configuration stage, the values are encapsulated in the providers and are not available directly. If there is a functional dependency of one value on another one (or in the special case is equal to, one could invoke .map or .flatMap on the value provider and inside lambda the value will be available as an argument and it's the way to operate on the future property value. As a result, a new "provider" will be created, which will calculate the value of the expression on demand during the execution phase.
Example:
class TaskA: DefaultTask() { @OutputFile val result = project.objects.fileProperty() init { result.convention(project.buildDir.file("result.txt")) } } class TaskB: DefaultTask() { @InputFile val input = project.objects.fileProperty() @Action fun taskB() { println(input.get().asFile.absolutePath) } }
In the script, there is no need to declare the dependency explicitly, provided that the properties are related:
val taskA = tasks.register<TaskB>("taskA") { output.set(file("other.txt")) } tasks.register<TaskB>("taskB") { input.set(taskA.result) }
Now, when calling taskB, the taskA will be considered as a dependency and executed, if necessary.
Using files as signals that survive invocations
When performing operations that only result in side effects (for example, deploying to the cloud), and are not reflected naturally in the file system, gradle cannot check whether the task should be performed or not. As a result, the corresponding task will be executed every time.
To help gradle, one could create a taskB.done on the task completion, and specify that this file is the output file for the task. In this file, it is desirable to reflect in a compressed form a description of what state the cloud configuration is in. You can, for example, specify the SHA of the deployed configuration or just text with the list of deployed components and their versions.
If several tasks change the shared cloud state, then it is useful to represent this state in the form of one or more files shared by these tasks (cloud.state). Each task that changes the state in the cloud will also change the local files. Thereby gradle will understand which tasks might require restarting.
Restart the local service only if the executable file has changed
Let's say we have a build task that produces an executable file
class BuildNative(objects: ObjectFactory): DefaultTask() { @OutputFile val nativeBinary: FileProperty = objects.fileProperty() init { nativeBinary.convention("binary") } @TaskAction fun build() { // ... } }
The service is started by creating a process with the name of this executable file.
open class StartService(objects: ObjectFactory): DefaultTask() { @InputFile val nativeBinary: FileProperty = objects.fileProperty() @OutputFile val pidFile: FileProperty = objects.fileProperty() init { nativeBinary.convention("binary") pidFile.convention("binary.pid") } @TaskAction fun start() { pidFile.get().asFile.writeText( Process(nativeBinary.get().asFile.absolutePath).start() )// slighlty simplified } }
Now we can declare a restart task that will not be executed if the executable file has not changed
class ServiceStarted(objects: ObjectFactory): StartService(objects) { @TaskAction fun restartIfNeeded() { if(pidFile.get().asFile.exists()) { kill(pidFile.get().asFile.readText()) } start() } }
This task chain is convenient for local debugging of services. If you change any line in any of the services, only the respective service will be rebuilt and restarted.
Centralized setting of port numbers
For testing, you may need to run configurations with a different set of services. In a pair of services that depend on one another, the interaction port must be specified twice — in the service itself and in the client of this service. It is clear that according to the principle of the single version of the truth (SVOT/SSOT), the port should be configured only once, and in other places it should refer to this trusted source. A single service configuration must be available for both the service and the client.
Let's look at an example of how this could be done in gradle.
data class ServiceAConfig(val port: Int, val path: String) { fun localUrl(): URL = URL("http://localhost:$port/$path") }
In the main script build.gradle.kts we create a configuration and put it in ' extra`:
val serviceAConfig: ServiceAConfig by extra(ServiceAConfig(8080, "serviceA/test"))
And in other scripts, we can access this configuration declared in 'RootProject'.:
val serviceAConfig: ServiceAConfig by rootProject.extra
Thus, it is possible to link services and centralize the configuration.
Unsolicited tips
- Read the documentation. Gradle documentation can be taught in schools as an example of how one should write a documentation.
- Understand the gradle model. A lot of questions will evaporate, if you understand the basic gradle model.
- Use buildSrc. When building projects, you often need to add separate auxiliary tasks. Put such tasks in
buildSrc. You can also create independent projects with plugins, which will allow you to use them in other projects. - Strive to make each task incremental. In this case, changing any line of code will only lead to the execution of strictly necessary tasks. The build will run as quickly as possible.
- Share your knowledge. Many things in gradle and in kotlin may be unusual for people who have not had experience with them. There is definitely an entry barrier. Making changes blindly, without understanding how the build system works, is unlikely to lead to a decent result.
Conclusion
In this post, we looked at some of the features of the project build system based on gradle/kotlin. Gradle seems to be quite convenient for building non-JVM projects. Even for non-JVM projects almost all of the advantages are preserved — modularity, performance, and error protection. If you commit self-discipline and develop the build project based on the general principles of engineering, then gradle will allow you to obtain a flexible and maintainable system.
Acknowledgements
I would like to thank nolequen, Starcounter, tovarischzhukov for constructive criticism of the draft article.

