Привет, Хабр! Меня зовут Сергей Качкин. Вместе с командой я несколько лет занимался тестированием производительности систем хранения данных: много тестов делали сами, видели результаты наших коллег и заказчиков. Так у нас накопилось некоторое количество опыта, которым хочется поделиться.
В этой статье я расскажу про тестирование блочных стораджей. Начнем с теории — поговорим о выборе цели теста, отличиях синтетики от реальных нагрузок, выборе инструмента для генерации нагрузки. Затем перейдём к практике — тестированию случайного и последовательного доступа, измерению масштабируемости СХД.

Для тех, кто любит смотреть видео: доклад на эту тему я рассказывал на Перфоманс конф #8.
Выбор цели теста
Самое важное на старте тестирования — определить для себя, зачем это всё. Начинать тест с мыслями «так правильно», «так говорит руководитель» или «в инструкции написано, что должен быть какой‑нибудь тест перфоманса» — плохая идея. Есть ситуации, когда тест помогает, но иногда только вносит путаницу и добавляет вопросов. Поделюсь наблюдениями из практики.
Тестировать есть смысл, если:
вы хотите убедиться, что ваша СХД тянет эталонную нагрузку, которую вы знаете;
нужно локализовать аппаратную проблему или боттлнек;
вы просто из любопытства изучаете СХД, с которой вы работаете.
В тестирование лучше не лезть, если:
вы не знаете, что конкретно вы хотите;
вы хотите с помощью синтетики имитировать поведение сложного приложения (например, базы данных);
вы хотите воспроизвести проблему с продуктива в тестовом окружении c помощью синтетики.
Часто в такой ситуации вы думаете: «Ага, сейчас я воспроизведу её в тестовом окружении и спокойно, не торопясь, отдебажу». Но вместо решения вы можете получить две непонятных нагрузки: одну на продуктиве, вторую в тестовом окружении. Они будут совершенно разными по природе, но похожими по симптому. Законы Мёрфи тут срабатывают удивительно надёжно. Синтетические тесты плохо воспроизводят реальность. По субъективному опыту, лучше окунуться в трассировку запросов, статистику и логи с продакшена.
Отличия синтетики от реальных нагрузок
Почему синтетика не воспроизводит реальность? На самом деле, проблемы всего две: пространство и время.
Скорость поступления запросов реальных приложений
Время — это интервал между запросами. В синтетике скорость поступления запросов — это всегда какой-то случайный процесс с известным распределением: либо это равномерное распределение, либо это пуассоновский процесс, но это всегда что-то определённое.
В реальной жизни, если верить исследователям, скорость поступления запросов — это самоподобный процесс. Это значит, что в нём случается много выбросов, вне зависимости от масштаба выборки. Предположу, что возникают они из-за того, что в системах есть точки синхронизации. В файловых системах — fsync(), в базах данных — чекпоинты, когда большое количество блоков сливается в СХД разом. Эти выбросы в реальной жизни часто являются источником проблем — роста времени отклика, переполнения очередей и так далее.
Пятно данных
Вторая проблема — это пятно данных. Опять же, в синтетике мы чаще всего обращаемся к блокам случайно по заданному пятну данных или всей поверхности. В реальной жизни, если верить разработчикам теста SPC, вероятность повторного обращения к блоку зависит от времени с момента первого обращения. Если мы что-то «потрогали», скорее всего, мы сразу повторим это, а если нет, вероятность сильно снижается.
Однако, даже зная то, что синтетика не воспроизводит реальную жизнь, всё равно есть смысл ею заниматься: системы хранения данных разрабатываются, продаются и принимаются с синтетикой, и только потом — уже у заказчика — они встречаются с реальной жизнью.
Выбираем инструмент
Чем чаще всего пользуются инженеры, когда начинают тестировать диски? Классика — dd, cp и им подобные инструменты. Это плохо работает: они однопоточные, умеют воспроизводить только последовательные паттерны и дают крайне мало статистики на выходе.

Нагружайте СХД специальными утилитами. Их много, однако почти все давно заброшены. Из того, что можно использовать, и того, что применяем и мы, и заказчики, остались только fio и Vdbench.
Vdbench
Vdbench — инструмент, который хорошо прижился в энтерпрайзе. Многие наши заказчики тестируют с его помощью свои дисковые массивы, мы тоже его используем. Он логично сделан, у него понятная структура настроек, он кроссплатформенный, на нём можно компоновать сложные составные паттерны.
Но есть и минусы. Он умер в 2008 году. Второй недостаток (если первого недостаточно) — в нём нет асинхронного ввода-вывода. Тем не менее, Vdbench используется в повседневной работе — и у нас, и у заказчиков.
fio
Де-факто стандартом для тестирования блочного доступа является fio. В 2023 году это единственное, что стоит использовать. Его автор — Йенс Аксбо (Jens Axboe) — тот самый инженер, который разрабатывает блочный стек Linux. Соответственно, все новые фичи Linux сразу поддерживаются в fio. Инструмент гибкий, в нём много опций логирования и отчетов, к нему много готовых обёрток и парсеров, он постоянно дорабатывается.
Из минусов — в fio легче запутаться в настройках. В нём меньше возможностей, чтобы делать составные нагрузки. Вы не всегда сможете полностью перенести проект из Vdbench. Есть шанс налететь на баг, особенно в варианте клиент-сервер.
Тестирование случайного IO
С инструментом определились, теперь поговорим про сами нагрузки. Исторически они разделяются на случайный доступ и последовательный (тяжелое наследие механических жестких дисков, в которых паттерн влияет на скорость). Сейчас чаще всего мы встречаемся со случайным доступом. Это типовая нагрузка для SSD-дисков. Основные целевые приложения — базы данных. Они требовательны ко времени отклика, и их часто размещают на SSD.
Как правило, это мелкий блок (4k-32k) и какое-то соотношение чтение-запись (например, 70/30). Размером пятна данных мы регулируем количество кэш-хитов.
Частный случай — если надо проверить пропускную способность СХД с SSD дисками. Тут можно сделать большой блок (>128КБ).
Выбираем размер очереди
Есть один параметр, на который стоит обратить внимание — глубина очереди (IO depth). Её указывают во всех тестах, но никто не объясняет, как выбрано значение. Если вы возьмёте любой бенчмарк дисков, там будет написано: «Протестировано с такой-то глубиной очереди». Но почему именно такой?
Глубина очереди связана с результатом по закону Литтла:

Мы задаём на входе теста глубину очереди и на выходе получаем какое-то произведение IOPS и времени отклика (latency). Например, у нас есть требование: 100K IOPS со временем отклика 1 мс.
cлучайная нагрузка, 8KiB, чтение/запись = 70/30,
100 000 IOPS,
Время отклика — 1 мс.
Считаем очередь по закону Литтла:

Значит очередь должна быть 100 — ни больше, ни меньше. Дальше мы запускаем тест с очередью 100 и смотрим, получится ли 100 000 IOPS.
Может получиться:
200k IOPS, latency 0.5 ms,
10K IOPS, latency = 10 ms,
50K IOPS, latency = 2 ms.
Также закон Литтла можно переписать иначе:

И это тоже может стать основой теста. Мы сообщаем fio или Vdbench, сколько IOPS мы хотим получить, и утилита сама подберёт за нас нужную очередь. Такой подход «наоборот» тоже полезен. Он хорошо подходит для длительных тестов. Допустим, просим 100K IOPS и оставляем на неделю. Или начинаем делать СХД «больно» разными способами. В таком тесте хорошо видно влияние фоновых процессов, скрабберов, ребилда пула или влияние отказа компонентов, репликации и снэпшотов. Это удобно: мы видим, насколько отказы и дополнительные функции влияют на время отклика.
Измеряем масштабируемость дисковой подсистемы
Что делать, когда требования по производительности не сформулированы? Допустим, запрос на тестирование от заказчика или руководителя звучит просто и лаконично: «Надо измерить производительность стораджа». Измерение масштабируемости может помочь решить задачку.
Из теории мы знаем, что при росте нагрузки в какой-то момент производительность (IOPS) расти перестанет, а будет увеличиваться только время отклика (latency). Причём для разных конфигураций СХД насыщение будет наступать в разные моменты.
Поэтому когда нет чёткой цели на тестирование, будем увеличивать очередь и найдём область насыщения. В качестве производительности СХД будем показывать точку 95% утилизации системы и точку, где время отклика не превышает 1 мс. Тут нет тайного смысла, просто надо выбрать что-то конкретное и заданное в цифрах.
Для поиска этих точек и визуализации удобно использовать Universal Scalability Law. Это расширение закона Амдала, в который добавлен еще один компонент. Статья-первоисточник про USL выложена тут. Есть готовые проекты на R (и судя по всему, исследователи предпочитают использовать именно его — все последние апдейты заезжают в проект на R). Есть и проект на Python, тоже вполне рабочий.
Суть в том, что вы делаете несколько обмеров с разной глубиной очереди, дальше готовая библиотека вычисляет коэффициенты alpha, beta, gamma, которые описывают график.

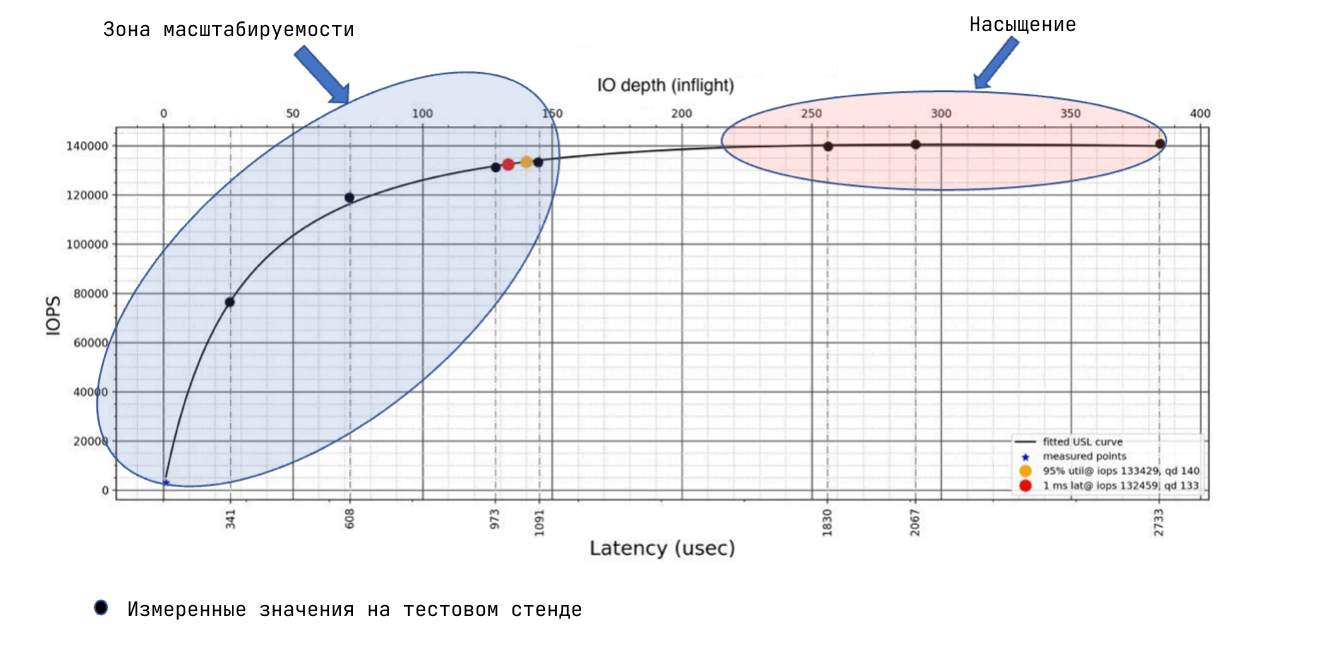
На графике вы наглядно видите, в каком диапазоне очередей у вас система масштабируется, а где она уходит в насыщение (т.е. где IOPS перестают расти).
В тестировании web-сервисов, насколько я слышал, часто увеличивают нагрузку до некоторого процента отказов в обслуживании. К дискам такое неприменимо, отказов быть не должно никогда.
Важный момент, который надо проговорить: мы тестируем СХД целиком, а не отдельный диск. СХД — это софт, шины, кэши, медиа. В этом тесте мы не всегда требуем, чтобы диски были в “steady state” и считаем, что они FOB (fresh out of box). То есть на выходе мы получаем максимальные цифры, которые позволяет СХД. Если мы хотим более приближенные к жизни цифры, надо делать поправку на характеристики дисков с учётом числа, модели конкретного SSD и следовать методике SNIA.
Тест устоявшегося состояния СХД осложняется тем, что у нас нет прямого доступа к SSD диску, чтобы гарантированно прописать весь объем SSD с нужной интенсивностью. СХД может резервировать часть пространства под spare, и гарантированно прописать весь объем SSD не получится. Тестирование устоявшегося состояния в СХД с SSD — тема для отдельной статьи.
Вывод: результат теста мы считаем максимальным «попугаем», на который способна СХД. К примеру, для Татлин Unified с 24 NVMe дисками и iSCSI подключением к двум хостам, график получается вот такой.

По графику видно, что 95% утилизации система достигает при очереди 246 и скорости в 290K IOPS.
При этом 300K IOPS получается при очереди 300 с временем отклика 1 мс. Это вычисленное значение должно быть близко к максимуму этой конфигурации.
Можно запустить тест в одной точке на более долгое время, например, на 24 часа. График даёт понимание, как выбранная нагрузка расположена по отношению к точке насыщения системы.
Паттерн fio:
[global]
ioengine=libaio
direct=1
size=100%
group_reporting=1
time_based
randrepeat=0
ramp_time=60s
rw=randrw
numjobs=5
iodepth=30
runtime=24h
blocksize=8k
rwmixread=70
write_lat_log
write_bw_log
write_iops_log
write_hist_log
log_hist_msec=1000
log_hist_coarseness=4
log_avg_msec=1000
[oltp]
# десять сырых multipath устройств
host1
read: IOPS=113k, BW=881MiB/s (924MB/s)(72.6TiB/86400003msec)
write: IOPS=48.3k, BW=378MiB/s (396MB/s)(31.1TiB/86400003msec);
host2
read: IOPS=99.9k, BW=780MiB/s (818MB/s)(64.3TiB/86400001msec)
write: IOPS=42.8k, BW=334MiB/s (351MB/s)(27.5TiB/86400001msec.
Тестирование последовательного доступа
Тест потоковых нагрузок — чаще всего просто головная боль. Этот тип нагрузок характерен для механических жестких дисков. Это бэкапы, стриминг медиа, архивы. Это всегда что-то большим блоком — 128K–1024K. Если у вас случайная нагрузка, то скорее всего вам понадобятся SSD, если потоковая, то можно рассматривать обычные механические жесткие диски.
Проблема в том, что идеального последовательного IO не существует в обычной жизни. Чаще всего в тестах подразумевается тест в один поток. По крайней мере, в большинстве синтетических тестов это так. И это страшно далеко от реальности, в которой всегда есть несколько открытых файлов, несколько потоков бэкапа, несколько фильмов, которые пользователи смотрят одновременно. Сегодня потоковой нагрузкой заказчики обычно называют нагрузку, в которой можно выделить отдельные последовательные потоки, а не просто один поток.
Появляется вариативность настроек, из-за которой приходится делать исследовательскую работу. По-хорошему, для каждого теста надо уточнять, что именно считается потоковой нагрузкой в конкретном случае.
Часто требование для резервного копирования формулируется просто в МБ/c, например, «надо 3000 МБ/c». Но на практике это 10 потоков по 300 МБ/с, или 100 по 30? Для СХД это две большие разницы.
Как следствие, для потоковых нагрузок подходят две метрики.
Скорость на один поток в МБ/c. Определяется временем отклика СХД.
Общая пропускная способность на все потоки в МБ/c.
Потоковая нагрузка и самая частая ошибка с fio
Популярная ошибка с потоковой нагрузкой на сырых устройствах и fio — это увеличивать количество потоков, не разнося их по пятну данных. Это много где описано, но все всё равно наступают на эти грабли (и мы тоже).
[global]
direct=1
ioengine=libaio
rw=read
bs=128k
iodepth=4
numjobs=2
[sda]
filename=/dev/sdeПятно данных обоих потоков будет выглядеть вот так:
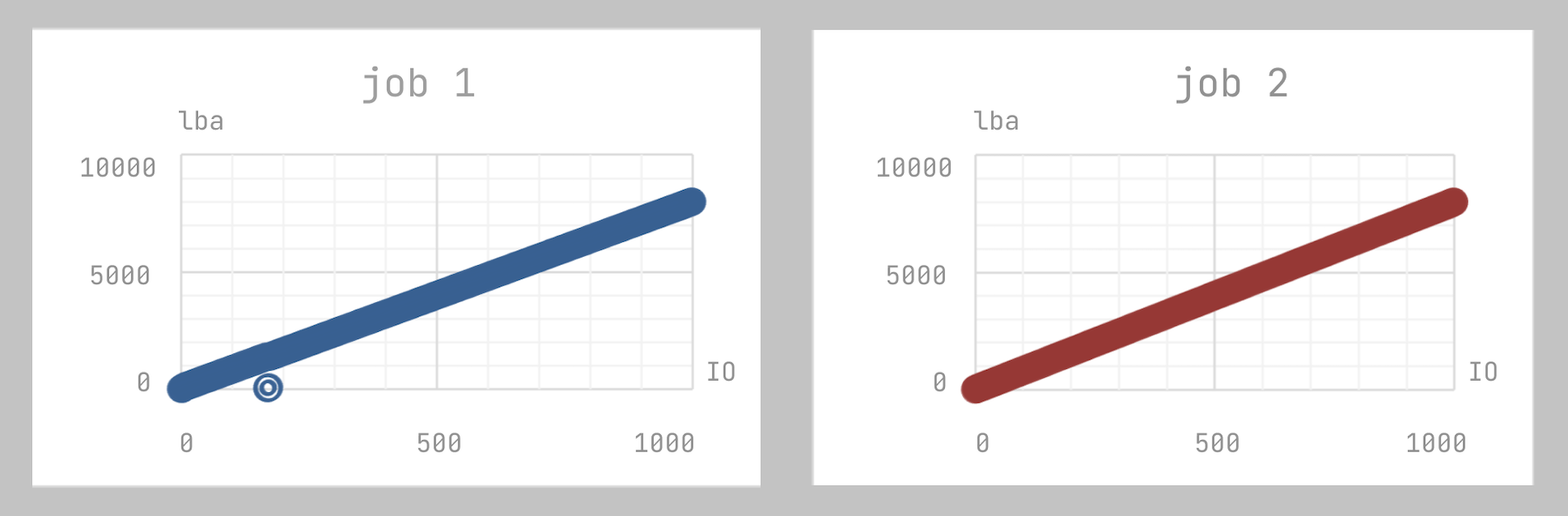
Так делать не надо. Когда вы задаете в fio несколько потоков, они все начинают читать с начала диска. Соответственно, при первом обращении данные попадут в кэш. Вы получите кэш-хиты там, где вы их не ждали. Результат будет искажённый.
Как сделать лучше? Например, так:
[global]
ioengine=libaio
direct=1
size=100%
rw=randread:500
numjobs=2
iodepth=4
blocksize=256k
[sda]
filename=/dev/sdaПятно данных выглядит примерно так:

Через 500 запросов каждый поток «прыгает» в случайный блок на диске. Таким образом есть надежда, что они не пересекутся. Вот ещё один пример.
[global]
ioengine=libaio
direct=1
rw=read
bs=256k
size=20%
offset_increment=20%
numjobs=5
iodepth=4
[sda]
filename=/dev/sdaПолучается пять потоков fio, равномерно распределённых по поверхности.

Мы делим дисковое пространство на 5 областей (size=20%) и запираем каждый поток в свою область. Таким образом, мы покрываем все пространство диска. Это более предсказуемый паттерн.
Если нужна файловая система, то каждому потоку даем свой набор файлов, который они будут заполнять.
[global]
thread
direct=1
ioengine=libaio
rw=write
blocksize=256k
file_service_type=sequential
nrfiles=140
filesize=10g
numjobs=8
iodepth=8
[archive]
directory=/mnt/Моё личное мнение про файловую систему — если есть возможность, лучше её не использовать. Она добавляет сложных компонентов: файловый кэш, журнал транзакций, алгоритмы оптимизации (read ahead, flush behind). Кроме того, невозможно проконтролировать, к каким блокам на диске мы обращаемся. Всё это будет искажать результаты.
На эту тему есть статья Benchmarking file system benchmarking: it *IS* rocket science, где наглядно описано, что все существующие бенчмарки файловых систем не очень хорошо работают. Поэтому, если условия позволяют упростить тест, лучше делать его на сырых устройствах.
От простых нагрузок больше пользы
Когда говорят о тестировании сложных СХД, часто рекомендуют делать составные нагрузки, имитирующие сложные приложения (OLTP, OLAP, VDI, и т.д.).
Например:
«горячие» и «холодные» зоны на диске;
смесь блоков разных размеров;
смесь последовательного и случайного доступа.
По моему субъективному опыту, от простых однокомпонентных нагрузок пользы больше. Да, это меньше похоже на реальные приложения и «продаётся» хуже. Если вы инженер и тестируете хранилище, от вас будут просить более реалистичные сценарии, составные паттерны. Все хотят видеть, как на вашей системе будет работать какой-нибудь Postgres, а не ваши 100 000 IOPS на странной синтетике 70/30 8K.
У меня есть несколько аргументов против составных нагрузок. Во-первых, это всё равно не будет похоже на реальное приложение, как я писал выше. Во-вторых, сложно анализировать, как это всё работает внутри СХД. В-третьих, такую нагрузку сложнее масштабировать. Не всегда можно корректно добавить 10% к напору. И последнее — если это «продающий» бенчмарк, который вы используете в маркетинге, то будут возникать сомнения, что нагрузку подогнали под нужный результат.
В статье я постарался описать особенности тестов производительности блочных СХД. Некоторым моментам обычно уделяют недостаточно внимания, например осознанному выбору размера очереди. Если цель тестирования не сформулирована в цифрах, можно попробовать оценить масштабируемость СХД. Тесты потоковой нагрузки можно делать многими разными способами и часто выбор непрост. Привёл пример с реальным TATLIN.UNIFIED. Надеюсь, это будет кому-то полезно.
