В одном будущем проекте встала задача передавать и хранить данные в формате VCard, которые содержат кириллические буквы. Так как размер передаваемой информации ограничен, необходимо было уменьшить размер данных.
Было несколько вариантов:
Красивый, но бесполезный, график результатов:
Визитная карточка в формате VCard 3.0 (длина 260 символов):
Все приведенные ниже результаты касаются этого примера. Для кириллических визиток результаты отличаться не должны. Для визиток на других языках, наверное, потребуется дополнительное исследования, в рамки задачи это не входило.
Вариант с использованием CP1251 отпал сразу. Несмотря на маленький размер готовых файлов его использование (как и любой другой традиционной кодировки) сильно ограничивает возможности сервиса.
Стандартная схема сжатия (The Standard Compression Scheme for Unicode, SCSU) основана на разработке Рейтер.
Основная идея SCSU — определение динамических окон на пространстве кодов Юникод. Символы, принадлежащие к небольшим алфавитам (например, кириллице) могут быть закодированы одним байтом, который указывает индекс символа в текущем окне. Окна предустановленны к блокам, которые чаще всего используются, так что кодировщику не приходиться их задавать.
Для больших алфавитов, включая Китайский язык, SCSU позволяет переключаться между однобайтовым и «Юникод режимом», который на самом деле является UTF-16BE.
Управляющие байты («теги») вставляются в текст, чтобы изменять окна и режимы. Теги экранирования («quote» tags), используются для переключения в другое окно только для следующего символа. Это полезно для кодирования одного символа вне текущего окна, или символа, который конфликтует с тегами.
Перед первой кириллической буквой кодер использует тег SC2 (шестнадцатеричное 12), чтобы переключиться в динамическое окно №2, которое предустановленно на кириллический блок символов. При повторном использовании кириллических символов, тег не используется.
Концепция бинарно упорядоченного сжатия (The Binary Ordered Compression for Unicode, BOCU) была разработана в 2001 году (by Mark Davis and Markus Scherer for the ICU project).
Основанная идея BOCU-1 — кодировать каждый символ как разницу (расстояние в таблице Юникод) к предыдущему символу. Небольшие разницы занимают меньшее количество байт, чем большие. Кодируя разницы, BOCU-1 достигает одинакового сжатия для небольших алфавитов, в каком бы блоке они не находились.
BOCU-1 дополняет концепцию следующими правилами:
На каждую смену блока (переход из кириллицы в латиницу) кодеру необходимо два байта (d3 – для переключения в кириллический блок, 4c – для двоеточия).
Для сравнения эффективности был выбран алгоритм сжатия gzip. Для больших текстов gzip показывает большую степень сжатия в сравнении SCSU и BOCU-1 (так как количество разных символов даже в многоязычных документах ограничено). На небольших текстах, как VCard в примере, однозначный результат получить сложно.
Существенным недостатком универсальных алгоритмов сжатия есть сложность реализации компрессора и декомпрессора.
Вопрос о двухэтапном сжатии (например, SCSU + gzip) для меня остается открытым.
Результаты работы алгоритмов SCSU и BOCU-1 для исходных данных в сравнении с CP1251 и UTF8 показаны в первой колонке.
Вторая колонка представляет количество байт выданных непосредственно кодером (без Ма́ркер поря́дку ба́йт, BOM, который указывает на тип представления Юникод в файле).
Третья колонка представляет файл сжатый gzip
Четвертая колонка показывает количество байт данных в gzip архиве (без заголовка, 18 байт).
Все файлы в архиве (5 кб).
SQL Server 2008 R2 использует SCSU для хранения nchar(n) и nvarchar(n). Symbian OS использует SCSU для сериализации строк.
Для работы с SCSU и BOCU-1 можно использовать ICU или SC UniPad
.
Меня очень удивило, что ни один из распространенных ридеров штрих кодов не распознает SCSU или BOCU-1.
Unicode Technical Note #14. A Survey of Unicode Compression
Unicode Technical Standard #6. A Standard Compression Scheme for Unicode
Unicode Technical Note #6. BOCU-1:MIME-Compatible Unicode Compression
Было несколько вариантов:
- Использовать традиционные кодировки (для кириллицы — CP1251).
- Использовать форматы сжатия Юникода. На сегодняшний день это — SCSU и BOCU-1. Детальное описание этих двух форматов привожу ниже.
- Использовать универсальные алгоритмы сжатия (gzip).
Красивый, но бесполезный, график результатов:
Входные данные
Визитная карточка в формате VCard 3.0 (длина 260 символов):
BEGIN:VCARD VERSION:3.0 N:Пупкин;Василий FN:Василий Пупкин ORG:ООО «Рога и Копыта» TITLE:Самый главный TEL;TYPE=WORK,VOICE: +380 (44) 123-45-67 ADR;TYPE=WORK:;1;Крещатик;Киев;;01001;UKRAINE EMAIL;TYPE=PREF,INTERNET:vasiliy.pupkin@example.com END:VCARD
Все приведенные ниже результаты касаются этого примера. Для кириллических визиток результаты отличаться не должны. Для визиток на других языках, наверное, потребуется дополнительное исследования, в рамки задачи это не входило.
Вариант с использованием CP1251 отпал сразу. Несмотря на маленький размер готовых файлов его использование (как и любой другой традиционной кодировки) сильно ограничивает возможности сервиса.
SCSU
Стандартная схема сжатия (The Standard Compression Scheme for Unicode, SCSU) основана на разработке Рейтер.
Основная идея SCSU — определение динамических окон на пространстве кодов Юникод. Символы, принадлежащие к небольшим алфавитам (например, кириллице) могут быть закодированы одним байтом, который указывает индекс символа в текущем окне. Окна предустановленны к блокам, которые чаще всего используются, так что кодировщику не приходиться их задавать.
Для больших алфавитов, включая Китайский язык, SCSU позволяет переключаться между однобайтовым и «Юникод режимом», который на самом деле является UTF-16BE.
Управляющие байты («теги») вставляются в текст, чтобы изменять окна и режимы. Теги экранирования («quote» tags), используются для переключения в другое окно только для следующего символа. Это полезно для кодирования одного символа вне текущего окна, или символа, который конфликтует с тегами.
Пример
… N : П у п к и н … F N : В а с и л и й … … 4E 3A 12 9F C3 BF BA B8 BD … 46 4E 3A 92 B0 C1 B8 BB B8 B9 …
Перед первой кириллической буквой кодер использует тег SC2 (шестнадцатеричное 12), чтобы переключиться в динамическое окно №2, которое предустановленно на кириллический блок символов. При повторном использовании кириллических символов, тег не используется.
Преимущества
- текст, закодированный в SCSU, в основном занимает столько же места, сколько и в традиционной кодировке. Накладные расходы на теги относительно незначительны.
- SCSU декодер легко реализовать, в сравнении с универсальными алгоритмами сжатия.
Недостатки
- SCSU использует контрольные символа ASCII, не только как теги, но и как часть обычных символов. Это делает SCSU неподходящим форматом для таких протоколов как MIME, которые интерпретируют контрольные символы без их декодирования.
BOCU-1
Концепция бинарно упорядоченного сжатия (The Binary Ordered Compression for Unicode, BOCU) была разработана в 2001 году (by Mark Davis and Markus Scherer for the ICU project).
Основанная идея BOCU-1 — кодировать каждый символ как разницу (расстояние в таблице Юникод) к предыдущему символу. Небольшие разницы занимают меньшее количество байт, чем большие. Кодируя разницы, BOCU-1 достигает одинакового сжатия для небольших алфавитов, в каком бы блоке они не находились.
BOCU-1 дополняет концепцию следующими правилами:
- Предыдущее или базовое значение выравнивается по середине блока, во избежание больших прыжков из начала блока в конец.
- 32 контрольных символа ASCII, а также пробелы не изменяться при кодировании, для совместимости с электронной почтой и для сохранения бинарного порядка
- Пробел не вызывает изменения базовой величины. Это означает что при кодировании нелатинских слов разделенных пробелами, нет необходимости делать большой скачок до U+0020 и назад.
- контрольные символы ASCII сбрасывают базовую величину, что делает соседние строки в файле независимыми.
Пример
… N : П у п к и н ; В … F N : В а с и л и й … … 9e 8a d3 d3 93 8f 8a 88 8d 4c 11 d3 c6 … 96 9e 8a d3 c6 80 91 88 8b 88 89 …
На каждую смену блока (переход из кириллицы в латиницу) кодеру необходимо два байта (d3 – для переключения в кириллический блок, 4c – для двоеточия).
Преимущества
- Контрольные символы ASCII остаются при кодировании
- Как и SCSU, BOCU-1 требует небольших накладных расходов в сравнении с традиционными кодировками
Недостатки
- Латинские буквы (и все ASCII символы, кроме контрольных) меняют свое значение при кодировании. Так, например, XML парсер должен получить информацию о BOCU-1 кодировке из протокола более высокого уровня.
- Алгоритм BOCU-1 нигде формально не описан, кроме программного кода сопровождающего UTN #6.
Универсальные алгоритмы сжатия
Для сравнения эффективности был выбран алгоритм сжатия gzip. Для больших текстов gzip показывает большую степень сжатия в сравнении SCSU и BOCU-1 (так как количество разных символов даже в многоязычных документах ограничено). На небольших текстах, как VCard в примере, однозначный результат получить сложно.
Существенным недостатком универсальных алгоритмов сжатия есть сложность реализации компрессора и декомпрессора.
Вопрос о двухэтапном сжатии (например, SCSU + gzip) для меня остается открытым.
Результаты
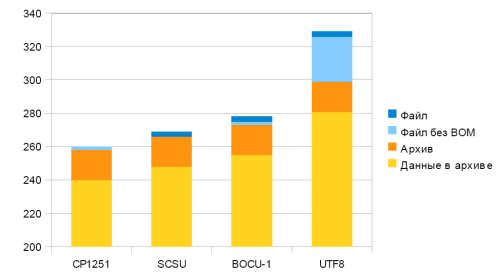
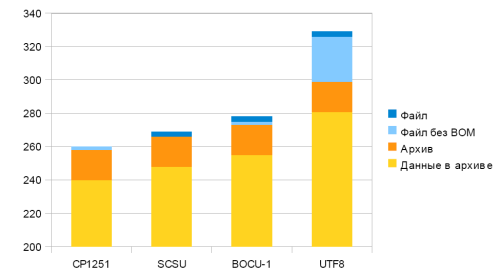
Результаты работы алгоритмов SCSU и BOCU-1 для исходных данных в сравнении с CP1251 и UTF8 показаны в первой колонке.
Вторая колонка представляет количество байт выданных непосредственно кодером (без Ма́ркер поря́дку ба́йт, BOM, который указывает на тип представления Юникод в файле).
Третья колонка представляет файл сжатый gzip
Четвертая колонка показывает количество байт данных в gzip архиве (без заголовка, 18 байт).
| Файл | Файл без BOM | В архиве | Длина данных в архиве | |
| CP1251 | 260 | 260 | 258 | 240 |
| SCSU | 267 | 264 | 266 | 248 |
| BOCU-1 | 278 | 275 | 273 | 255 |
| UTF8 | 329 | 326 | 299 | 281 |
Все файлы в архиве (5 кб).
Применение
SQL Server 2008 R2 использует SCSU для хранения nchar(n) и nvarchar(n). Symbian OS использует SCSU для сериализации строк.
Для работы с SCSU и BOCU-1 можно использовать ICU или SC UniPad
.
Меня очень удивило, что ни один из распространенных ридеров штрих кодов не распознает SCSU или BOCU-1.
Что еще почитать
Unicode Technical Note #14. A Survey of Unicode Compression
Unicode Technical Standard #6. A Standard Compression Scheme for Unicode
Unicode Technical Note #6. BOCU-1:MIME-Compatible Unicode Compression









