Комментарии 33
Да, для этого требуются ресурсы. Но некоторым разработчикам важнее быстрая интроспекция, чем умные подсказки. Мы думаем об этом и надеюсь, придумаем еще один режим работы, который лучше подходит для таких случаев.
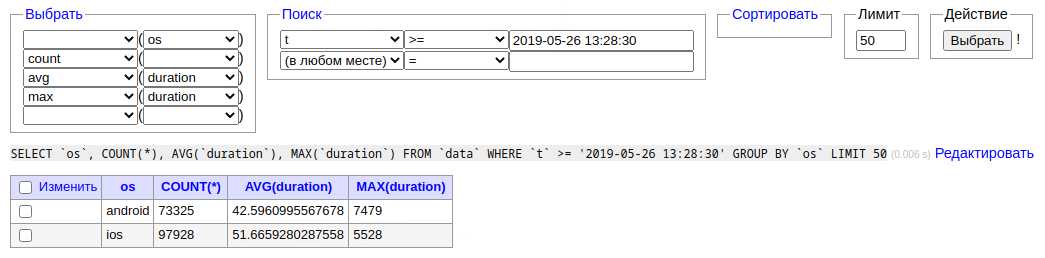
В целом, я думаю, наша аудитория согласна с нами в том, что при помощи автодополнения и генерации написать запрос можно даже быстрее. Ну и такие возможности более гибкие.
при помощи автодополнения и генерации написать запрос можно даже быстрее
Что-то не совсем понял ответ. Как мне в режиме просмотра таблицы отфильтровав нужные записи по дате сгруппировать их по выбранному полю быстрее чем просто выбрать это поле из выпадающего списка? Я если честно не знаю даже как это сделать медленнее, кроме как перейти из режима просмотра таблицы в новую sql-консоль и написать там с нуля мой запрос со всеми фильтрами и потом уже добавить в него группировку. Но это не то что «быстрее», это очень очень долго.
Сейчас у нас есть:
— Фильтрация (при помощи нового запроса на стороне БД)
— Поиск (текстовый на клиенте, в любой колонке)
— Сортировка (на клиенте и на БД, по выбору)
— Изменение размеры страницы
Из того что вы привели в пример не хватает агрегатных функций и группировки для запуска нового запроса. У нас, мне кажется, даже тикета такого нет: вроде не очень просят.
Но есть тикет по выполнению агрегатных функций уже на самом результате: youtrack.jetbrains.com/issue/DBE-5278
Помнится, на pgconf я интересовался о подстановке параметров в запрос в стиле command window pl/sql developer'а (когда значения параметров можно править в любой момент под редактором запросов, а не только в модалке перед запуском). Планируется ли такая возможность?
Возможно что запроса нет потому что большая часть софта работы с бд делается с большим упором на администрирование чем на разработку. Есть исключения (как я понимаю, DataGrip позиционируется больше как IDE), но большинство просто не привыкло к удобствам немодального ввода параметров. По факту, я такую форму видел только в pl/sql developer-е (а это именно чисто ide) и его опенсорсном клоне, учитывая то, что это софт чисто под оракл, в вашем community не так много людей привыкли к хорошему. У нас в компании раньше большая часть проектов была на oracle, при чем часть проектов предпочитали pl/sql developer, другие — toad, при этом замечено, что при переходе программистов из проекта в проект, они тащат с собой предпочтения сформированные на самом первом проекте. И тут получается проблема курицы и куриного яйца: я никогда не задумаюсь о том, чтобы слезть с pl/sql developer-а в части работы с oracle, пока у альтернативы не появятся большинство возможностей (а конкретно test window в девелопере — одна из активно используемых фич теми, кто пишет много pl/sql-кода). А значит что о необходимости такой фичи я вам не скажу.
Конкретно про себя: я пользователем DataGrip пока не являюсь, т.к. в последний раз не увидел для себя критичной массы плюсов по сравнению с текущей используемой ide-шкой, чтобы убеждать руководство в необходимости попытки смены основной используемой среды. Поэтому описать нормально запрос мне сложновато. Возможно, вскоре и придётся попробовать DataGrip в работе, тогда и заведу запрос.
1. Удобное место для ввода биндов вида :pr_parametr1 с автоматическим заполнением поля для биндов биндами из кода.
2. Возможность удобно дебажить PLSQL код. Это очень очень важно.
3. Возможность в режиме дебага выполнить запрос внутри той же сесси, в которой идет дебаг. То есть, если у меня в plsql болке был апдйет таблицы без коммита, я могу посмотреть что именно поменялось перед тем, как продолжить дебаг
Я 90% времени занимаюст разработкой под Oracle на PLSQL. Тут я вижу только один адекватный инструмент, PLSQL Developer. Все остальные не дают достатоного удобства для разработки на PLSQL.
Мечтаю о времени, когда ДатаГрип начнет поддерживать нормально Oralce -)
Поддерживаю, у PL/SQL Developer’а есть две фичи, которых я больше нигде не видел, и которые невероятно удобны.
- Test Window, где можно задать любой блок кода, и выполнить его, задав переменные привязки. Особенно удобно это с курсорами. Я попробовал это в IntelliJ Idea. У меня, конечно, получилось запустить хранимку, которая возвращает курсор, но удобство так себе. Как и в Oracle SQL developer. А просто открыть курсор, и посмотреть его, без хранимки, и вообще никак, а я этим постоянно пользуюсь для отладки запросов.
- вторая фича – это гибко настраиваемый браузер сессий. Можно настроить любые запросы, например сессии с открытыми транзакциями; сессии, которые съели много темпа; сессии из dba_blockers/dba_waiters и так далее. И в дочернем гриде тоже можно настроить любые запросы, например SQL Monitoring report, план выполнения, события одидания сейчас, и накопленные за сессию/стейтмент. У ДатаГрипа вообще пока нет браузера сессий.
открыть курсор без хранимки — это, например, выполнить вот такой код:
begin
open :p_cursor for
select *
from my_table t
where t.business_date = :p_business_date
and t.account_id = :p_account_id
order by t.time_stamp desc;
end;В PL/SQL Developer'е это делается в Test Window. Он сам находит, что в этом куске кода три переменных привязки. И, соответственно, указывается, что p_cursor — это курсор, p_business_date — дата (с указанием конкретной), а p_account_id — число (с указанием конкретного). Можно этот кусок кода выполнить, потом кликнуть на многоточие рядом со словом p_cursor в табличке с переменными привязки, и увидеть результат.
Это очень удобно, когда хочется позапускать запрос, который тормозит, и причем обязательно сделать это с переменными привязки, а не с литералами, потому что с литералами будет другой план выполнения. А тут можно взять один плохо работающий запрос, и позапускать его, в условиях, максимально близких к тому, как это работает в хранимке (или к тому, как он запускается, например, из Джавы). И можно, пока он работает, в бэкграунде в браузере сессий его найти, и посмотреть план выполнения, и SQL Monitoring Report, если он есть. На этом этапе можно найти проблему с запросом, и поправить её.
Собственно, поэтому и хочется видеть в DataGrip (а точнее в Idea Ultimate) и некий аналог Test Window, для удобного (!) запуска с переменными привязки; и настраиваемый браузер сессий.
Спасибо вам за DataGrip, я чесно давно не стыкался с тем что меня что-то не устаивает. По-моему вы движетесь в правильном направлении, все как програмисты любят — до мелочей.
Ничего не сможете сказать по поводу https://youtrack.jetbrains.com/issue/DBE-11063? Крайне необходимая вещь иногда.
Нету ничего при попытке экспортировать результаты запроса в другую базу/схему при использовании любой 2020.2 версии.
Ошибка: Не работает ROW_COUNT() в MySQL
При выполнении скрипта:
CREATE TEMPORARY TABLE tmp_test (col INT);
INSERT INTO tmp_test VALUES (1);
SELECT ROW_COUNT();
возвращает 0
всё потому что между запросами куча всего лишнего выполняется
2020-07-31T06:12:08.385309Z 14 Query /* ApplicationName=PhpStorm 2019.3.2 */ INSERT INTO tmp_test VALUES (1)
2020-07-31T06:12:08.388977Z 14 Query SHOW WARNINGS
2020-07-31T06:12:08.402021Z 14 Query SELECT @@session.transaction_isolation
2020-07-31T06:12:08.466823Z 14 Query /* ApplicationName=PhpStorm 2019.3.2 */ set session transaction read write
2020-07-31T06:12:08.474409Z 14 Query /* ApplicationName=PhpStorm 2019.3.2 */ SAVEPOINT `0ce3488f_9352_4c65_bfa7_bc0b9bd49c2f`
2020-07-31T06:12:08.477516Z 14 Query SELECT @@session.transaction_read_only
2020-07-31T06:12:08.528428Z 14 Query SHOW WARNINGS
2020-07-31T06:12:08.537026Z 14 Query /* ApplicationName=PhpStorm 2019.3.2 */ select database()
2020-07-31T06:12:08.548932Z 14 Query SHOW WARNINGS
2020-07-31T06:12:08.559930Z 14 Query SHOW WARNINGS
2020-07-31T06:12:08.566771Z 14 Query /* ApplicationName=PhpStorm 2019.3.2 */ SET net_write_timeout=600
2020-07-31T06:12:08.572162Z 14 Query /* ApplicationName=PhpStorm 2019.3.2 */ SET SQL_SELECT_LIMIT=501
2020-07-31T06:12:08.574361Z 14 Query /* ApplicationName=PhpStorm 2019.3.2 */ SELECT ROW_COUNT()
Ещё не знаю как в DataGrip, но в Шторме очень хочется чтобы результаты закладки «console», отображались и были привязаны именно к закладке, а не в отдельном фрейме «Services» выводились. А то невозможно, например, сравнить 2 результата на разных серверах.
Ещё не знаю как в DataGrip, но в Шторме очень хочется чтобы результаты закладки «console», отображались и были привязаны именно к закладке, а не в отдельном фрейме «Services» выводились. А то невозможно, например, сравнить 2 результата на разных серверах.
Эта фича похоже у вас появилась в DataGrip 2020.1 Show output results in the editor
А в свежем PHPStorm'е она тоже появилась?
Поддержку ClickHouse планируется расширять? Например, работа со словарями не поддерживается. Сами запросы выполняются, а проверка синтаксиса выдаёт ошибку
create table test1.table1
(
id String,
FirstName String,
LastName String,
AgeMin Int8,
AgeMax Int8
)
engine = MergeTree ORDER BY id
SETTINGS index_granularity = 8192;
CREATE VIEW test1.view1
(
`id_hash` UInt64,
`id` String,
`FirstName` String,
`LastName` String,
`AgeMin` Int8,
`AgeMax` Int8
)
AS
SELECT halfMD5(id) AS id_hash,
*
FROM test1.table1;
drop dictionary if exists test1.view1;
CREATE DICTIONARY test1.view1(
id_hash UInt64,
id String,
FirstName String,
LastName String,
AgeMin Int8,
AgeMax Int8
)
PRIMARY KEY id_hash
RANGE(MIN AgeMin MAX AgeMax)
SOURCE(CLICKHOUSE(host localhost port 9000 user default db test1 table view1))
LAYOUT(RANGE_HASHED())
LIFETIME(MIN 86400 MAX 150000);Подсказка на drop: "DATABASE, TABLE or TEMPORARY expected, got 'dictionary'"
Подсказка на create: "DATABASE, LIVE, MATERIALIZED, TABLE, TEMPORARY or VIEW expected, got 'DICTIONARY'"
В статье https://habr.com/ru/company/JetBrains/blog/461725/ описана приятная возможность "Select current statement.". На MySQL, например, всё хорошо отработало, а на этом запросе произошёл "полукраш" какой-то. Сама среда не упала, но окно "Find Actions" "вылетело". Открылось окно терминала с текстом "No manual entry for select \;type\=a".
macOS 10.15.6
PyCharm 2020.2
Или описанные функции в DataGrip и PyCharm работают по-разному?
Нашёл запрос на словари в кликхаусе — https://youtrack.jetbrains.com/issue/DBE-9813. Давно висит. Сколько нужно "голосов", чтобы задачу сделали?
1. Можно попробовать мультикаретки. По-моему, оч удобный способ, если редактор не воткнёт из-за большого количества инсертов.
2. Можно выделить все инсерты, нажать edit as table, скрыть столбец и то, что получилось оптяь экспортнуть в инстерты. К сожалению, имя таблицы придётся вписать заново, а еще через find/replace пофиксить проблемы с квотацией (кажется, что значения не должны квотироваться повторно, но сейчас это так)
Помогло?
CREATE DATABASE tmpdb;
USE tmpdb;
CREATE TABLE you_table (тут столбцы включая ненужный);
пакетный inserts из datagrip
ALTER TABLE you_table DROP no_needed_col;
INSERT INTO maindb.you_table SELECT * FROM you_table;
DROP DATABASE tmpdb;
DataGrip 2020.2: редактор больших значений, предпросмотр SQL при редактировании, новое отображение ячеек bool и другое