На днях вышло очередное обновление плагина Big Data Tools. Почти полтора года мы выпускали только Early Access Preview, и сейчас мы рады представить вам самую первую версию, рассчитанную на широкую аудиторию.

Big Data Tools — это плагин, позволяющий подключаться к кластерам Hadoop и Spark. Он предоставляет возможность мониторинга узлов, приложений и отдельных задач. Кроме того, можно создавать, запускать и редактировать ноутбуки Zeppelin. Вы можете не переключаться на веб-интерфейс Zeppelin и продолжать спокойно работать из любимой IDE. Плагин обеспечивает удобную навигацию по коду, умное автодополнение, рефакторинги и квик-фиксы прямо внутри ноутбука. Плагин доступен для установки в IntelliJ IDEA Ultimate, PyCharm и DataGrip. Вы можете скачать его со страницы плагина на сайте либо установить прямо из IDE.
Давайте подробней рассмотрим, что же изменилось в новой версии.
Поддержка Zeppelin 0.9

26 декабря команда Zeppelin сделала всем новогодний подарок: новый релиз 0.9, в котором было закрыто 568 тикетов.
Мы давно были готовы к этому событию, так как протестировали плагин на версии 0.9-preview2, поэтому поддержка 0.9 не заняла много времени. Приглашаем всех попробовать не только новую версию Big Data Tools, но и новую версию Zeppelin!
Импорт и экспорт ноутбуков Zeppelin
Плагин Big Data Tools берет на себя мелкие рутинные операции, ради которых неудобно переключаться на веб-интерфейс. Одна из таких операций — импорт и экспорт ноутбуков. Теперь вы можете сохранить ноутбук себе на компьютер и поделиться им с коллегами, не выходя из IDE.

Настройки интерпретаторов и репозиториев Zeppelin
Выбрав в контекстном меню ноутбука пункт «Open Interpreter Settings», вы теперь попадете вот в такой интерфейс:
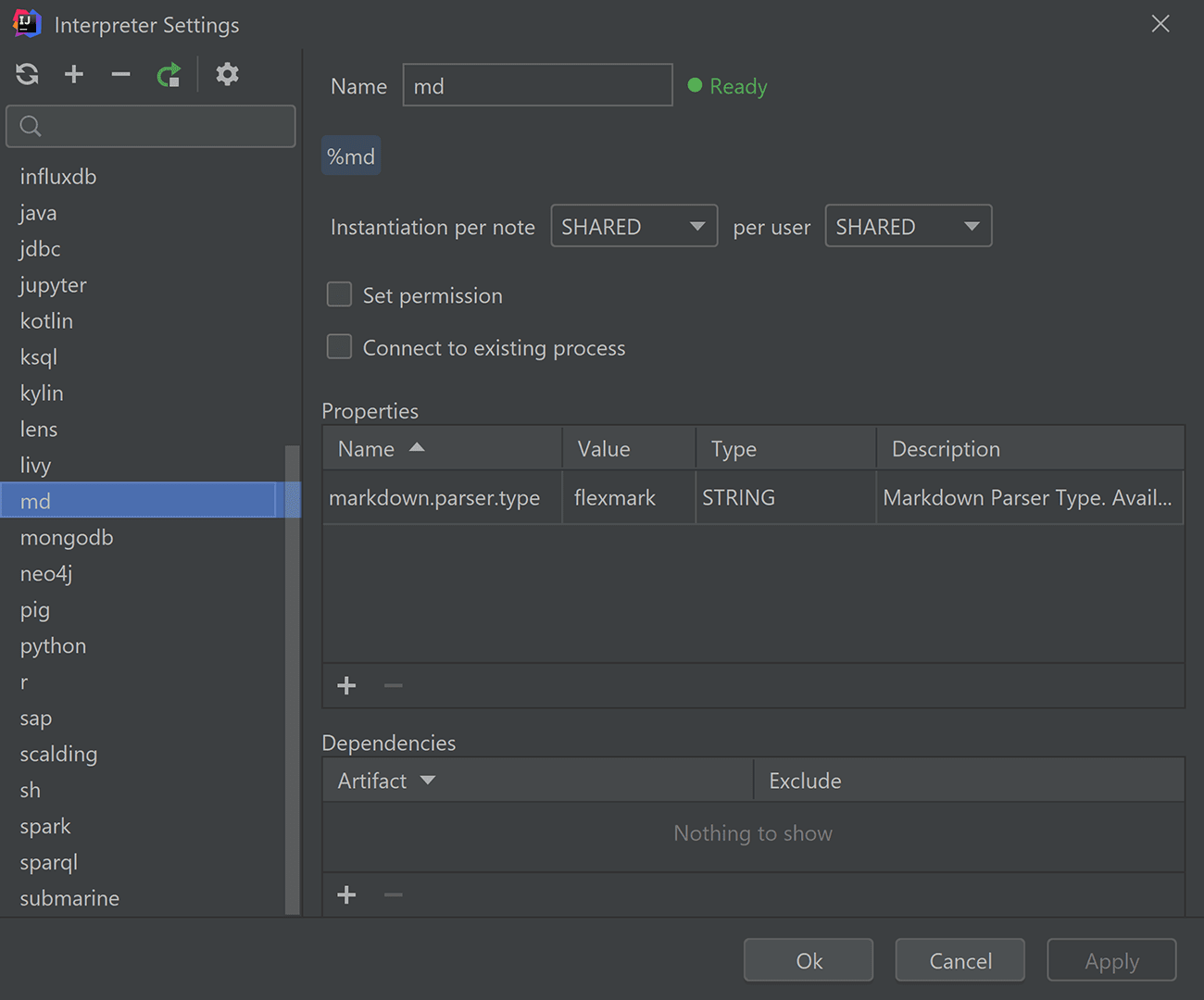
На этом скриншоте видны настройки интерпретатора Markdown. Точней, настройка здесь всего одна — markdown.parser.type. Этот параметр может принимать значения flexmark, pegdown и markdown4j, причем возможность выбрать flexmark появилась только в новом Zeppelin 0.9.
Здесь вы найдете полный список интерпретаторов и сможете просмотреть и отредактировать их настройки.
Этот интерфейс является улучшенным аналогом того, что уже существует в веб-интерфейсе Zeppelin. Огромный плюс в том, что теперь вам не нужно открывать браузер, чтобы посмотреть или отредактировать какую-либо настройку.
Кроме того, отсюда вы можете перезагрузить интерпретатор или отредактировать список репозиториев:
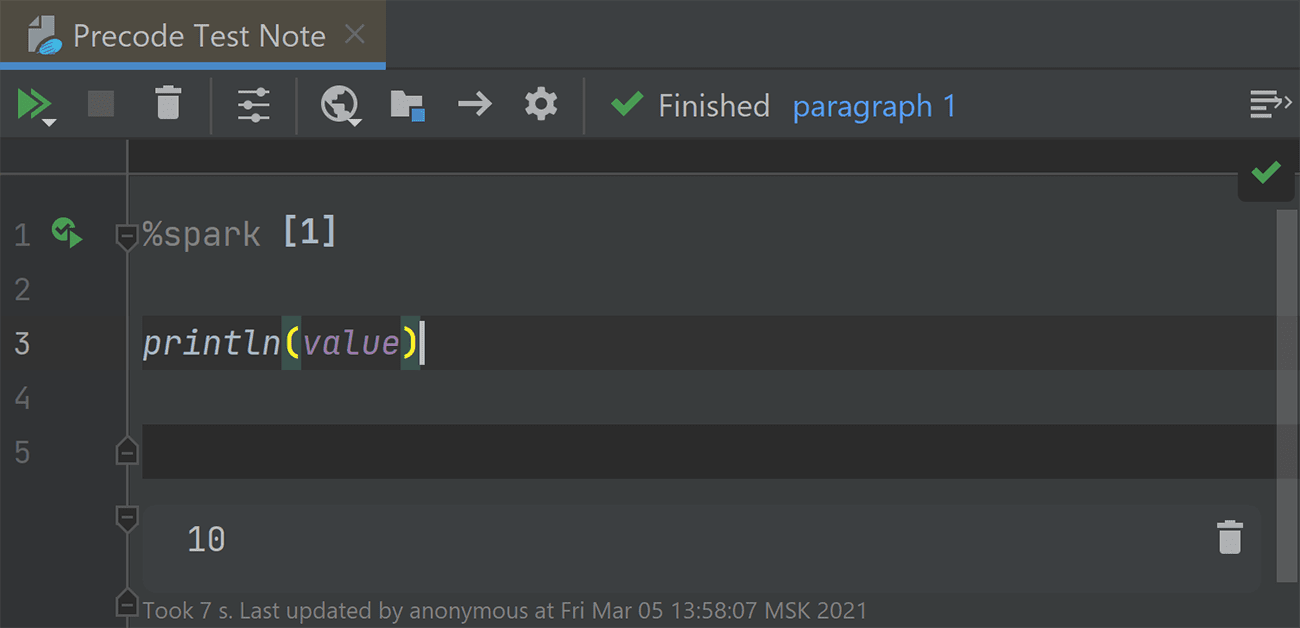
Подсветка precode
В Zeppelin есть возможность объявить переменные вне блокнота — они будут доступны при запуске интерпретатора. Например, это можно использовать для хранения конфигурации.
Соответствующая настройка называется zeppelin.SparkInterpreter.precode (теоретически здесь может участвовать любой интерпретатор, но в данный момент наша подсветка поддерживает только Spark и PySpark). Это фича Zeppelin, документацию можно прочитать здесь.
Начиная с этого обновления, плагин Big Data Tools учитывает код, записанный в precode. Если вы будете использовать в ноутбуке переменные, объявленные в precode, они будут подсвечиваться стандартным способом.
Чтобы сконфигурировать precode, используйте окно настроек интерпретатора, о котором мы рассказали выше.

Проверим, действительно ли работает подсветка:
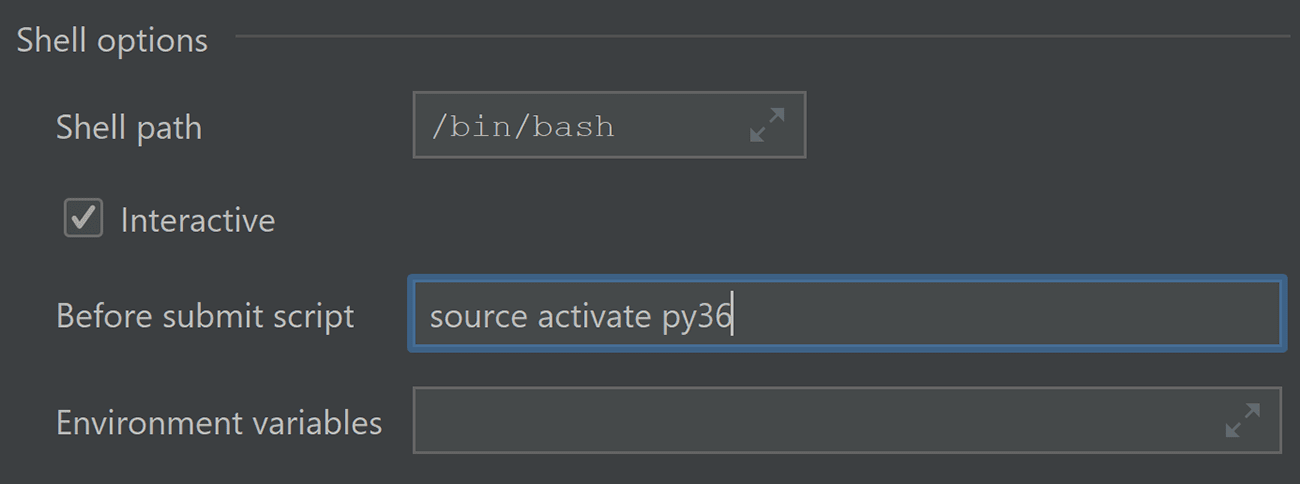
Запуск скрипта перед выполнением spark-submit
Если перед запуском задачи на выполнение вам нужно как-либо сконфигурировать среду, теперь для этого есть простой способ. Просто укажите строку, которую хотели бы выполнить с помощью шелла, в настройках spark-submit.
Допустим, нам нужно сконфигурировать окружение Python. Для этого можно запустить команду типа “source activate py36”. Впрочем, с тем же успехом можно запустить echo "Hello World" или любую другую команду.
Улучшенная поддержка Python
Мы продолжаем улучшать поддержку Python, которая появилась в конце декабря. На этот раз мы добавили окно, позволяющее прописать настройки Python, если это не было сделано до вас.

Обратите внимание на опцию «Install stubs for Spark built-ins». Включив ее, вы можете значительно улучшить автодополнение в PySpark.
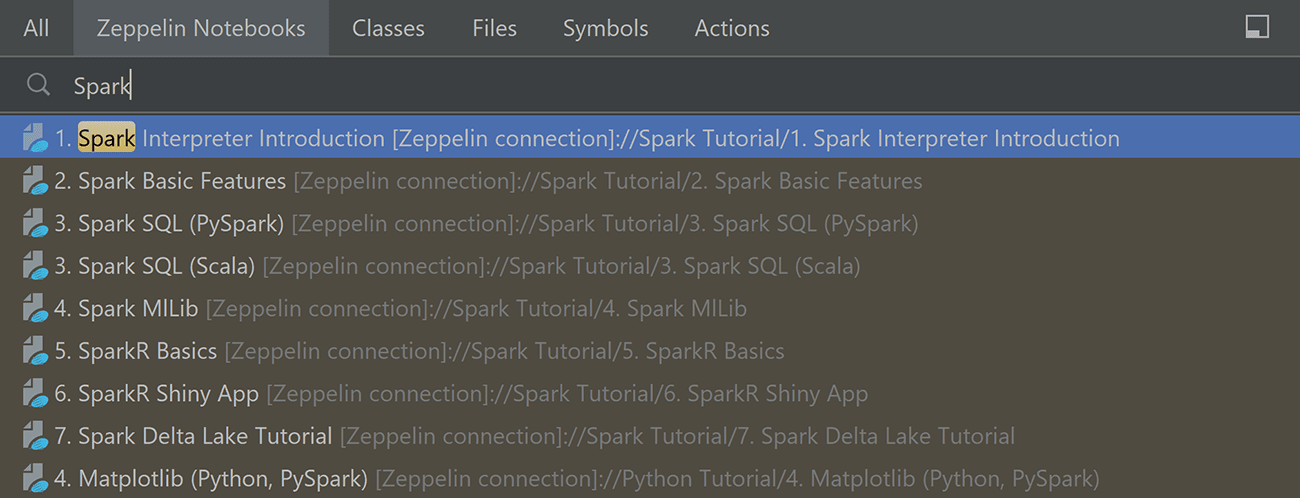
Улучшенный поиск по ноутбукам
Теперь ноутбуки можно находить с помощью Search Everywhere (вызывается двойным нажатием клавиши Shift).
Найденные ноутбуки будут отображены вместе со всеми результатами поиска во вкладке «All», а также отдельно — во вкладке «Zeppelin Notebooks».
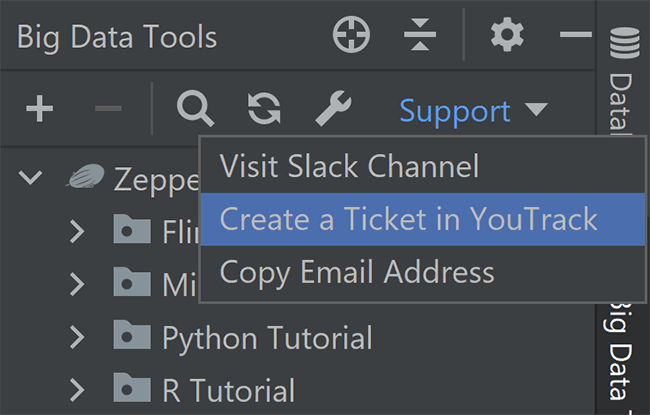
Связь с разработчиками
У вас могут возникнуть вопросы к разработчикам, но как понять, куда обратиться? Мы покончили с этой проблемой: теперь вы можете найти нужные ссылки прямо в интерфейсе плагина, воспользовавшись меню «Support» в правом верхнем углу панели «Big Data Tools».
Исправление ошибок
Плагин Big Data Tools продолжает активно развиваться. Мы стараемся учитывать все важные замечания и оперативно исправлять ошибки.
Подробный обзор основных улучшений можно найти в разделе «What’s New» на странице плагина. Если вы ищете информацию по конкретной проблеме, воспользуйтесь полным отчетом из YouTrack.
Спасибо, что пользуетесь нашим плагином! Напоминаю, что установить свежую версию можно либо с официальной страницы плагина, либо прямо в IDE (плагин называется «Big Data Tools»). На странице плагина вы можете оставить свои отзывы и предложения (мы обязательно их прочтем!), а также поставить оценку при помощи звездочек.
Документация и социальные сети
Ну и наконец, если вам нужно разобраться в функциональности Big Data Tools, у нас есть подробная документация — отдельно для IntelliJ IDEA, PyCharm и DataGrip. Задать вопрос можно в комментариях под этой статьей либо в Twitter.
Версия 1.0 — это большая веха в истории плагина Big Data Tools. Надеемся, что все эти улучшения окажутся полезными, позволят вам сконцентрироваться на интересных вещах и получать от этого удовольствие.
Ваша команда Big Data Tools
The Drive to Develop
