В развертывании медиасерверов для WebRTC есть две сложности: масштабирование, т.е. выход за рамки использования одного сервера и оптимизация задержек для всех пользователей конференции. В то время как простой шардинг в духе «отправить всех юзеров конференции X на сервер Y» легко масштабируется горизонтально, он все же далеко не оптимален в плане задержек. Распределять конференцию по серверам, которые не только близко расположены к пользователям, но и взаимосвязаны – звучит как решение для обеих проблем. Сегодня мы подготовили перевод подробного материала от Бориса Грозева из Jitsi: проблемы каскадных SFU, с описанием подхода и некоторых трудностей, а также подробности внедрения. Стоит сказать, что конференции Voximplant тоже используют SFU; сейчас мы работаем над каскадированием SFU, которое должно появиться в нашей платформе в следующем году.

Мышиные нейроны. Изображение NIHD (CC-BY-2.0)
Коммуникации в реальном времени очень чувствительны к сети: пропускная способность, задержки и потери пакетов. Снижение битрейта ведет к снижению качества видео, длительная сетевая задержка ведет к длительной задержке у конечных пользователей. Потеря пакетов может сделать звук прерывистым и привести к фризам на видео (из-за пропуска кадров).
Поэтому для конференции очень важно выбрать оптимальный маршрут между конечными устройствами/пользователями. Когда есть только два пользователя, то это просто – WebRTC использует протокол ICE чтобы установить соединение между участниками. Если возможно, то участники соединяются напрямую, в ином случае используется TURN-сервер. WebRTC умеет резолвить доменное имя, чтобы получать адрес TURN-сервера, благодаря чему можно легко выбирать локальный TURN на основе DNS, например, используя свойства AWS Route53.
Тем не менее, когда роутинг множества участников происходит через один центральный медиасервер, ситуация становится сложной. Многие WebRTC-сервисы используют Selective Forwarding Units (SFU), чтобы более эффективно передавать аудио и видео между 3 и более участниками.
В топологии «звезда» все участники соединяются с одним сервером, через которые они обмениваются медиа потоками. Очевидно, что выбор расположения сервера имеет огромное значение: если все участники расположены в США, использовать сервер в Сиднее – это не лучшая идея.

Многие сервисы используют простой подход, который неплохо работает в большинстве случаев: они выбирают сервер поближе к первому участнику конференции. Однако бывают случаи, когда это решение неоптимально. Представим, что у нас есть три участника с картинки выше. Если австралиец (Caller C) первым подключится к конференции, то алгоритм выберет сервер в Австралии, однако Server 1 в США будет лучшим выбором, т.к. он ближе к большинству участников.
Описанный сценарий – не очень частый, но имеет место. Если считать, что пользователя подключаются в случайном порядке, то описанная ситуация происходит с ⅓ всех конференций с 3 участниками, один из которых сильно удален.
Другой и более частый сценарий: у нас есть две группы участников в разных локациях. В этом случае порядок подключения неважен, у нас всегда будет группа близко расположенных участников, которые вынуждены обмениваться медиа с удаленным сервером. Например, 2 участника из Австралии (C&D) и 2 из США (A&B).

Переключиться на Server 1 будет неоптимально для участников C&D. Server 2 неоптимален для A&B. То есть какой бы сервер ни использовался, всегда будут участники, подключенные к удаленному (= неоптимальному) серверу.
Но если бы у нас не было ограничения в один сервер? Мы бы могли подключать каждого участника к ближайшему серверу, осталось бы только соединить эти серверы.
Отложим вопрос, как именно соединять серверы; давайте сперва взглянем, какой будет эффект.

SFU-соединение между C и D не изменилось – по-прежнему используется Server 2. Для участников A и B используется Server 1, и это очевидно лучше. Самое интересное – связь между, например, A и C: вместо A<=>Server 2<=>C используется маршрут A<=>Server 1<=>Server 2<=>C.
В соединении SFU есть свои плюсы и минусы. С одной стороны, в описанной ситуации время обмена между участниками становится больше при добавлении новых прыжков по сети. С другой стороны, имеет место уменьшение этого времени, когда мы говорим про связь «клиент» – «первый сервер», потому что мы можем восстанавливать медиапоток с меньшей задержкой по принципу hop-by-hop.
Как это работает? WebRTC использует RTP (обычно поверх UDP), чтобы передавать медиа. Это означает, что транспорт ненадежен. Когда теряется UDP-пакет, то можно игнорировать потерю или запросить повторную отправку (ретрансмиссию), используя пакет RTCP NACK – выбор уже на совести приложения. Например, приложение может проигнорировать потерю аудиопакетов и запросить ретрансмиссию некоторых (но не всех) видеопакетов, в зависимости от того, нужны ли они для декодирования последующих кадров или нет.
Ретрансмиссия RTP-пакета, один сервер
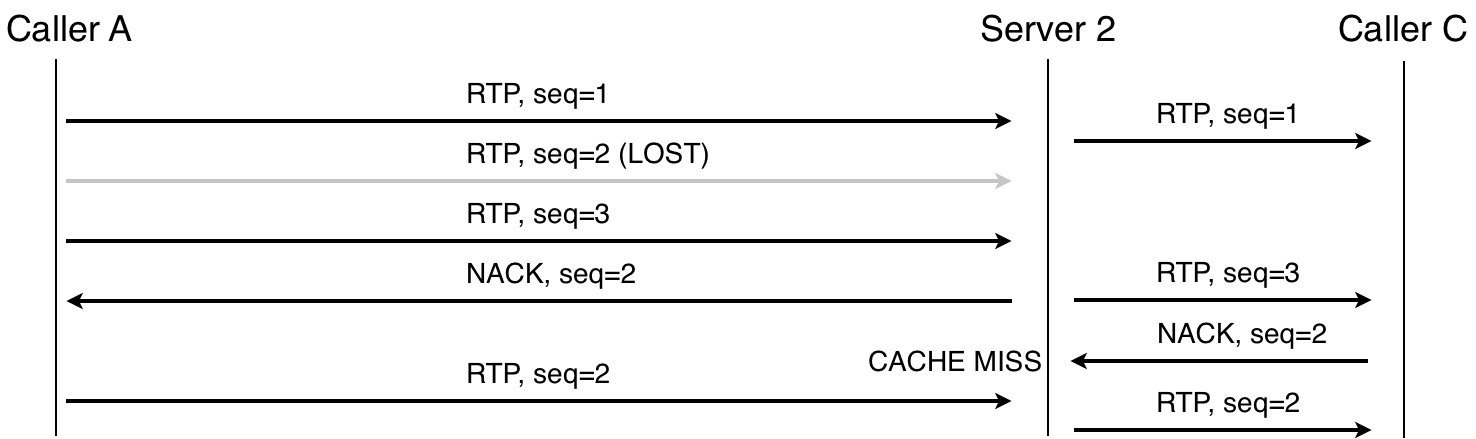
Когда есть каскадирование, ретрансмиссия может быть ограничена локальным сервером, то есть выполняться на каждом отдельном участке. К примеру, в маршруте A-S1-S2-C, если пакет потерян между A и S1, то S1 это заметит и запросит ретрансмиссию; аналогично с потерей между S2 и C. И даже если пакет потерян между серверами, принимающая сторона также может запросить ретрансмиссию.

Ретрансмиссия RTP-пакета, два сервера. Обратите внимание, что Server 2 не запрашивает пакет 2, потому что NACK пришел вскоре после отправки пакета.
На клиенте используется джиттер буфер, чтобы задержать воспроизведение видео и успеть получить отложенные/ретрансмитные пакеты. Размер буфера динамически меняется в зависимости от времени обмена между сторонами. Когда происходят hop-by-hop ретрансмиссии, задержка уменьшается, и как следствие, буфер может быть меньше – в итоге общая задержка тоже уменьшается.
Коротко: даже если время обмена между участниками выше, это может привести к снижению задержки при передаче медиа между участниками. Нам еще предстоит изучить этот эффект на практике.
Давайте взглянем на сигнализацию. С самого начала Jitsi Meet разделил концепцию сервера сигнализации (Jicofo) и медиасервера/SFU. Это позволило внедрить поддержку каскадирования относительно просто. Во-первых, мы могли обрабатывать всю логику сигнализации в одном месте; во-вторых, у нас уже был протокол сигнализации между Jicofo и медиасервером. Нам нужно было только немного расширить функциональность: у нас уже поддерживались множественные SFU, подключенные к одному серверу сигнализации, надо было добавить возможность одному SFU подключаться ко множеству серверов сигнализации.
В итоге появилось два независимых пула серверов: один для инстансов jicofo, другой для инстансов медиасервера, см. схему:
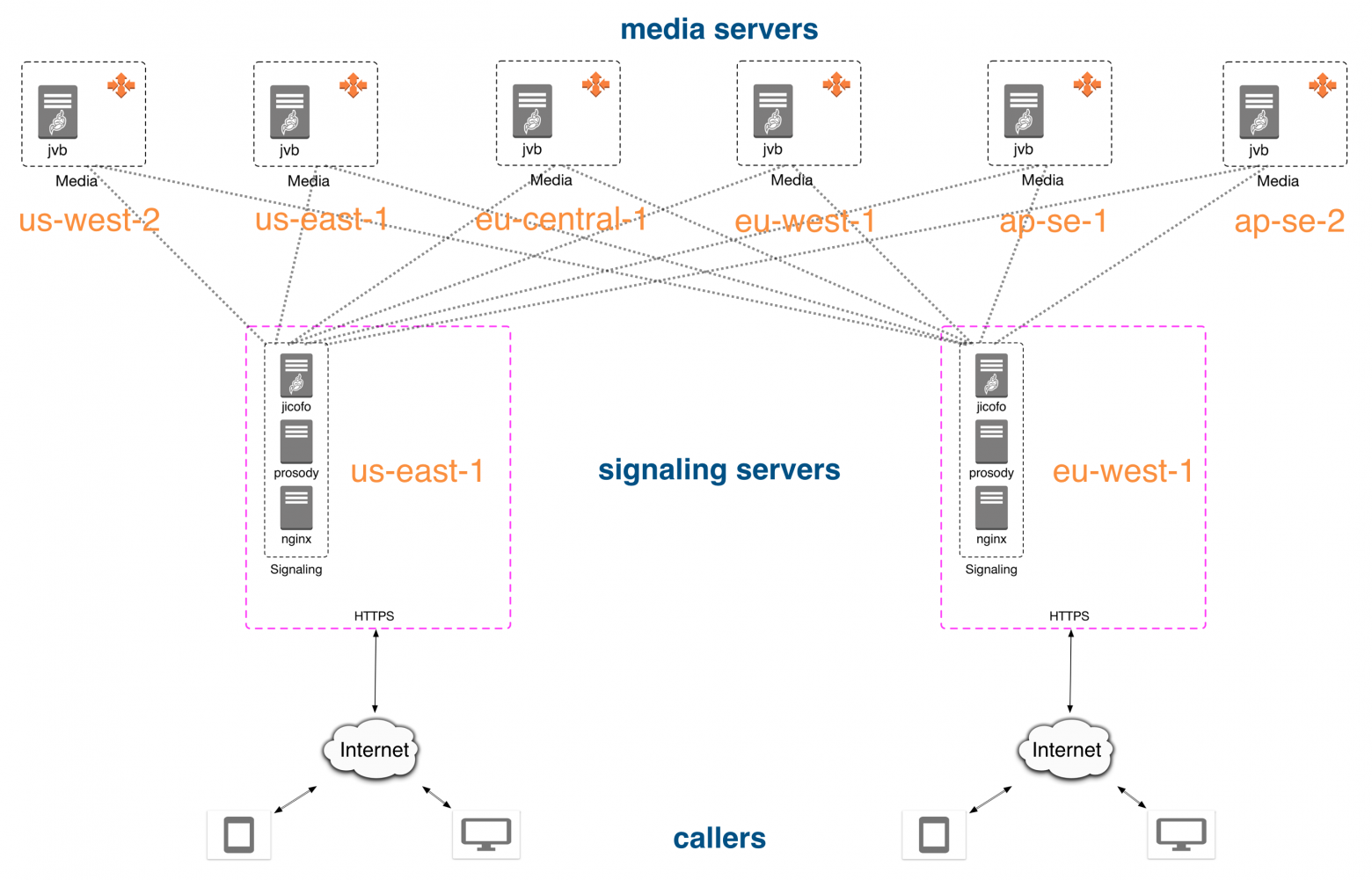
Пример организации серверов на AWS с возможностью каскада между разными дата-центрами.
Вторая часть системы – связь bridge-to-bridge. Мы хотели сделать эту часть максимально простой, поэтому между мостами нет сложной сигнализации. Вся сигнализация идет между jicofo и jitsi-videobridge; соединение между мостами используется только для аудио/видео и сообщений канала передачи данных.
Чтобы управлять этим взаимодействием, мы взяли протокол Octo, который оборачивает RTP-пакеты в простые заголовки фиксированной длины, а также позволяет передать текстовые сообщение. В текущей реализации, мосты связаны по полносвязной топологии (full mesh), однако возможны и другие топологи. Например, использовать центральный сервер (звезда для мостов) или древовидную структуру для каждого моста.
Пояснение: вместо оборачивания в Octo-заголовок можно использовать расширение RTP-заголовков, которое сделает потоки между мостами на чистом (S)RTP. Будущие версии Octo могу использовать этот подход.
Второе пояснение: Octo не означает ничего. Вначале мы хотели использовать центральный сервер, и это напомнило нам осьминога. Так появилось имя для проекта.
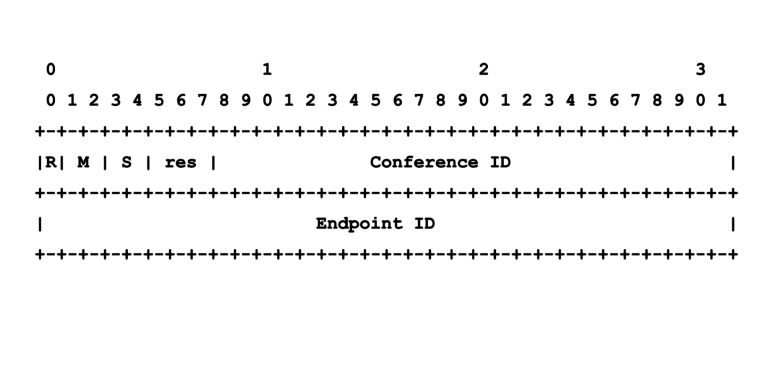 Формат Octo-заголовка
Формат Octo-заголовка
В терминологии Jitsi, когда мост – это часть конференции с множественными мостами, то у него есть дополнительный Octo-канал (на самом деле, один канал на аудио и один на видео). Этот канал отвечает за отправку/получение медиа в/из других мостов. Каждому мосту назначается свободный порт для Octo (4096 по умолчанию), поэтому нам нужно поле Conference ID, чтобы обрабатывать множественные конференции.
На данный момент у протокола нет встроенных механизмов безопасности и мы делегируем эту ответственность нижним уровням. Это ближайшее, чем мы займемся в ближайшее время, но пока что мосты должны быть в безопасной сети (например, отдельный инстанс AWS VPC).
Simulcast позволяет каждому участнику отправлять несколько медиапотоков с разными битрейтами, в то время как мост помогает определить, какие из них нужны. Чтобы это правильно работало, мы передаем все simulcast-потоки между мостами. Благодаря этому можно быстро переключаться между потоками, потому что локальный мост не должен запрашивать новый поток. Однако это не оптимально с точки зрения bridge-to-bridge трафика, т.к. некоторые потоки редко используются и лишь нагружают полосу пропускания без всякой цели.
Еще мы хотели возможность подписаться на активного участника/спикера конференции. Это оказалось несложно – мы научили каждый мост независимо определять главного участника, а затем уведомлять своих локальных клиентов. Это означает, что определение происходит несколько раз, но оно не затратно и позволяет упростить некоторые момент (например, не нужно решать, какой мост должен отвечать за DSI и беспокоиться за роутинг сообщений).
В текущей реализации этот алгоритм прост. Когда новый участник подключается к конференции, Jicofo должен определить, какой мост ему назначить. Это делается на основании региона участника и загруженности мостов. Если в том же регионе есть свободный мост, то назначается он. В противном случае, используется какой-либо другой мост.
Подробности про Octo см. в документации.
Для деплоя мы использовали машины в Amazon AWS. У нас были серверы (сигнализации и медиа) в 6 регионах:
Мы использовали инстансы HAProxy с геопривязкой, чтобы определять регион участника. Домен meet.jit.si управляется Route53 и резолвится в инстанс HAProxy, который добавляет регион в HTTP-заголовки отправляемого запроса. Заголовок позже используется в качестве значения переменной
Интерфейс jitsi показывает, сколько мостов используется и к каким привязаны конкретные пользователи – в целях диагностики и демонстрации. При наведении курсора на верхний левый угол локального видео покажет общее количество серверов и сервер, к которому подключены вы. Аналогично можно увидеть и параметры второго участника. Также вы увидите время обмена между вашим браузером и браузером собеседника (параметр E2E RTT).

Посмотрев, кто к какому серверу подключен, вы можете понять, используется ли каскадирование.
Изначально Octo появился в качестве A/B теста. Первые результаты были хороши, поэтому сейчас Octo доступен всем. Предстоит пропустить еще много трафика через него и подробнее изучить производительность; также планируется использовать эти наработки для поддержки еще более крупных конференций (когда одного SFU уже недостаточно).
Мышиные нейроны. Изображение NIHD (CC-BY-2.0)
Коммуникации в реальном времени очень чувствительны к сети: пропускная способность, задержки и потери пакетов. Снижение битрейта ведет к снижению качества видео, длительная сетевая задержка ведет к длительной задержке у конечных пользователей. Потеря пакетов может сделать звук прерывистым и привести к фризам на видео (из-за пропуска кадров).
Поэтому для конференции очень важно выбрать оптимальный маршрут между конечными устройствами/пользователями. Когда есть только два пользователя, то это просто – WebRTC использует протокол ICE чтобы установить соединение между участниками. Если возможно, то участники соединяются напрямую, в ином случае используется TURN-сервер. WebRTC умеет резолвить доменное имя, чтобы получать адрес TURN-сервера, благодаря чему можно легко выбирать локальный TURN на основе DNS, например, используя свойства AWS Route53.
Тем не менее, когда роутинг множества участников происходит через один центральный медиасервер, ситуация становится сложной. Многие WebRTC-сервисы используют Selective Forwarding Units (SFU), чтобы более эффективно передавать аудио и видео между 3 и более участниками.
Проблема со звездой
В топологии «звезда» все участники соединяются с одним сервером, через которые они обмениваются медиа потоками. Очевидно, что выбор расположения сервера имеет огромное значение: если все участники расположены в США, использовать сервер в Сиднее – это не лучшая идея.
Многие сервисы используют простой подход, который неплохо работает в большинстве случаев: они выбирают сервер поближе к первому участнику конференции. Однако бывают случаи, когда это решение неоптимально. Представим, что у нас есть три участника с картинки выше. Если австралиец (Caller C) первым подключится к конференции, то алгоритм выберет сервер в Австралии, однако Server 1 в США будет лучшим выбором, т.к. он ближе к большинству участников.
Описанный сценарий – не очень частый, но имеет место. Если считать, что пользователя подключаются в случайном порядке, то описанная ситуация происходит с ⅓ всех конференций с 3 участниками, один из которых сильно удален.
Другой и более частый сценарий: у нас есть две группы участников в разных локациях. В этом случае порядок подключения неважен, у нас всегда будет группа близко расположенных участников, которые вынуждены обмениваться медиа с удаленным сервером. Например, 2 участника из Австралии (C&D) и 2 из США (A&B).
Переключиться на Server 1 будет неоптимально для участников C&D. Server 2 неоптимален для A&B. То есть какой бы сервер ни использовался, всегда будут участники, подключенные к удаленному (= неоптимальному) серверу.
Но если бы у нас не было ограничения в один сервер? Мы бы могли подключать каждого участника к ближайшему серверу, осталось бы только соединить эти серверы.
Решение: каскадирование
Отложим вопрос, как именно соединять серверы; давайте сперва взглянем, какой будет эффект.
SFU-соединение между C и D не изменилось – по-прежнему используется Server 2. Для участников A и B используется Server 1, и это очевидно лучше. Самое интересное – связь между, например, A и C: вместо A<=>Server 2<=>C используется маршрут A<=>Server 1<=>Server 2<=>C.
Неявное влияние на скорость обмена
В соединении SFU есть свои плюсы и минусы. С одной стороны, в описанной ситуации время обмена между участниками становится больше при добавлении новых прыжков по сети. С другой стороны, имеет место уменьшение этого времени, когда мы говорим про связь «клиент» – «первый сервер», потому что мы можем восстанавливать медиапоток с меньшей задержкой по принципу hop-by-hop.
Как это работает? WebRTC использует RTP (обычно поверх UDP), чтобы передавать медиа. Это означает, что транспорт ненадежен. Когда теряется UDP-пакет, то можно игнорировать потерю или запросить повторную отправку (ретрансмиссию), используя пакет RTCP NACK – выбор уже на совести приложения. Например, приложение может проигнорировать потерю аудиопакетов и запросить ретрансмиссию некоторых (но не всех) видеопакетов, в зависимости от того, нужны ли они для декодирования последующих кадров или нет.
Ретрансмиссия RTP-пакета, один сервер
Когда есть каскадирование, ретрансмиссия может быть ограничена локальным сервером, то есть выполняться на каждом отдельном участке. К примеру, в маршруте A-S1-S2-C, если пакет потерян между A и S1, то S1 это заметит и запросит ретрансмиссию; аналогично с потерей между S2 и C. И даже если пакет потерян между серверами, принимающая сторона также может запросить ретрансмиссию.
Ретрансмиссия RTP-пакета, два сервера. Обратите внимание, что Server 2 не запрашивает пакет 2, потому что NACK пришел вскоре после отправки пакета.
На клиенте используется джиттер буфер, чтобы задержать воспроизведение видео и успеть получить отложенные/ретрансмитные пакеты. Размер буфера динамически меняется в зависимости от времени обмена между сторонами. Когда происходят hop-by-hop ретрансмиссии, задержка уменьшается, и как следствие, буфер может быть меньше – в итоге общая задержка тоже уменьшается.
Коротко: даже если время обмена между участниками выше, это может привести к снижению задержки при передаче медиа между участниками. Нам еще предстоит изучить этот эффект на практике.
Внедряем каскадные SFU: кейс Jitsi Meet
Сигнализация vs. Медиа
Давайте взглянем на сигнализацию. С самого начала Jitsi Meet разделил концепцию сервера сигнализации (Jicofo) и медиасервера/SFU. Это позволило внедрить поддержку каскадирования относительно просто. Во-первых, мы могли обрабатывать всю логику сигнализации в одном месте; во-вторых, у нас уже был протокол сигнализации между Jicofo и медиасервером. Нам нужно было только немного расширить функциональность: у нас уже поддерживались множественные SFU, подключенные к одному серверу сигнализации, надо было добавить возможность одному SFU подключаться ко множеству серверов сигнализации.
В итоге появилось два независимых пула серверов: один для инстансов jicofo, другой для инстансов медиасервера, см. схему:
Пример организации серверов на AWS с возможностью каскада между разными дата-центрами.
Вторая часть системы – связь bridge-to-bridge. Мы хотели сделать эту часть максимально простой, поэтому между мостами нет сложной сигнализации. Вся сигнализация идет между jicofo и jitsi-videobridge; соединение между мостами используется только для аудио/видео и сообщений канала передачи данных.
Протокол Octo
Чтобы управлять этим взаимодействием, мы взяли протокол Octo, который оборачивает RTP-пакеты в простые заголовки фиксированной длины, а также позволяет передать текстовые сообщение. В текущей реализации, мосты связаны по полносвязной топологии (full mesh), однако возможны и другие топологи. Например, использовать центральный сервер (звезда для мостов) или древовидную структуру для каждого моста.
Пояснение: вместо оборачивания в Octo-заголовок можно использовать расширение RTP-заголовков, которое сделает потоки между мостами на чистом (S)RTP. Будущие версии Octo могу использовать этот подход.
Второе пояснение: Octo не означает ничего. Вначале мы хотели использовать центральный сервер, и это напомнило нам осьминога. Так появилось имя для проекта.
В терминологии Jitsi, когда мост – это часть конференции с множественными мостами, то у него есть дополнительный Octo-канал (на самом деле, один канал на аудио и один на видео). Этот канал отвечает за отправку/получение медиа в/из других мостов. Каждому мосту назначается свободный порт для Octo (4096 по умолчанию), поэтому нам нужно поле Conference ID, чтобы обрабатывать множественные конференции.
На данный момент у протокола нет встроенных механизмов безопасности и мы делегируем эту ответственность нижним уровням. Это ближайшее, чем мы займемся в ближайшее время, но пока что мосты должны быть в безопасной сети (например, отдельный инстанс AWS VPC).
Simulcast
Simulcast позволяет каждому участнику отправлять несколько медиапотоков с разными битрейтами, в то время как мост помогает определить, какие из них нужны. Чтобы это правильно работало, мы передаем все simulcast-потоки между мостами. Благодаря этому можно быстро переключаться между потоками, потому что локальный мост не должен запрашивать новый поток. Однако это не оптимально с точки зрения bridge-to-bridge трафика, т.к. некоторые потоки редко используются и лишь нагружают полосу пропускания без всякой цели.
Выбор активного участника
Еще мы хотели возможность подписаться на активного участника/спикера конференции. Это оказалось несложно – мы научили каждый мост независимо определять главного участника, а затем уведомлять своих локальных клиентов. Это означает, что определение происходит несколько раз, но оно не затратно и позволяет упростить некоторые момент (например, не нужно решать, какой мост должен отвечать за DSI и беспокоиться за роутинг сообщений).
Выбор моста
В текущей реализации этот алгоритм прост. Когда новый участник подключается к конференции, Jicofo должен определить, какой мост ему назначить. Это делается на основании региона участника и загруженности мостов. Если в том же регионе есть свободный мост, то назначается он. В противном случае, используется какой-либо другой мост.
Подробности про Octo см. в документации.
Разворачиваем каскадные SFU
Для деплоя мы использовали машины в Amazon AWS. У нас были серверы (сигнализации и медиа) в 6 регионах:
- us-east-1 (Северная Вирджиния);
- us-west-2 (Орегон);
- eu-west-1 (Ирландия);
- eu-central-1 (Франкфурт);
- ap-se-1 (Сингапур);
- ap-se-2 (Сидней).
Мы использовали инстансы HAProxy с геопривязкой, чтобы определять регион участника. Домен meet.jit.si управляется Route53 и резолвится в инстанс HAProxy, который добавляет регион в HTTP-заголовки отправляемого запроса. Заголовок позже используется в качестве значения переменной
config.deploymentInfo.userRegion, которая доступна на клиенте благодаря файлу /config.js.Интерфейс jitsi показывает, сколько мостов используется и к каким привязаны конкретные пользователи – в целях диагностики и демонстрации. При наведении курсора на верхний левый угол локального видео покажет общее количество серверов и сервер, к которому подключены вы. Аналогично можно увидеть и параметры второго участника. Также вы увидите время обмена между вашим браузером и браузером собеседника (параметр E2E RTT).
Посмотрев, кто к какому серверу подключен, вы можете понять, используется ли каскадирование.
Заключение
Изначально Octo появился в качестве A/B теста. Первые результаты были хороши, поэтому сейчас Octo доступен всем. Предстоит пропустить еще много трафика через него и подробнее изучить производительность; также планируется использовать эти наработки для поддержки еще более крупных конференций (когда одного SFU уже недостаточно).
