

А что, если вам дадут задачу организовать хранение и раздачу статических файлов? Наверняка многие подумают, что тут все просто. А если таких файлов миллиард, несколько сотен терабайт и запросов к ним несколько миллиардов в сутки? Также много разных систем будут отправлять на хранение файлы разных форматов и размеров. Этот квест уже не кажется таким простым. Под катом история о том, как мы решили такую задачу, какие сложности при этом возникли, и как мы их преодолели.
Avito развивался стремительно с первых дней. Например, скорость загрузки новых картинок для объявлений выросла в первые годы в несколько раз. Это требовало от нас на начальном этапе решать вопросы, связанные с архитектурой, максимально оперативно и эффективно, в условиях ограниченных ресурсов. Кроме того, мы всегда отдавали предпочтение простым решениям, требующим мало ресурсов на поддержку. Принцип KISS («Keep it short and simple») — это до сих пор одна из ценностей нашей компании.
Первые решения
Вопрос, как хранить и как отдавать картинки объявлений, возник сразу, так как возможность добавить фото к объявлению, безусловно, является ключевой для пользователей — покупатели хотят видеть то, что они покупают.
В то время Avito умещался менее чем на 10 серверах. Первым и самым быстрым решением было хранение файлов картинок в дереве каталогов на одном сервере и синхронизация по крону на резервный.
Путь до файла определялся исходя из уникального цифрового идентификатора картинок. Поначалу было два уровня вложенности по 100 директорий на каждом.

Со временем место на сервере стало подходить к концу, и с этим нужно было что-то делать. На этот раз мы выбрали использование сетевого хранилища, примонтированного на несколько серверов. Сетевое хранилище нам до этого в тестовом режиме предоставлял сам дата-центр, как услугу, и по нашим тестам-замерам на тот момент оно работало удовлетворительно. Но с ростом нагрузки оно стало тормозить. Оптимизация хранилища силами дата-центра не помогала кардинально и не всегда была оперативной. Наши возможности повлиять на то, как оптимизируют хранилище, были ограничены и мы не могли быть уверены, что возможности таких оптимизаций рано или поздно не исчерпаются. Парк серверов к тому времени у нас заметно увеличился и стал исчисляться десятками. Была предпринята попытка быстро поднять распределенный glusterfs. Однако он работал удовлетворительно только под небольшой нагрузкой. Как только выводили на полную мощность, кластер «разваливался», либо все запросы к нему «зависали». Попытки подстроить его не увенчались успехом
Мы поняли, что нам нужно что-то другое. Были определены требования к новой системе хранения:
- максимально простая
- построенная из простых и проверенных компонентов
- не отнимающая много ресурсов на поддержку
- максимально возможный и простой контроль за тем, что происходит
- хороший потенциал для масштабирования
- очень быстрые сроки реализации и миграции с текущего решения
- допустима недоступность части картинок на время ремонта сервера (серверы нам чинили более-менее оперативно)
- допускается потеря небольшой части картинок в случае полного уничтожения одного из серверов. Надо сказать, что за все время существования Avito такого ни разу не было. 3*Тьфу.
Новая схема
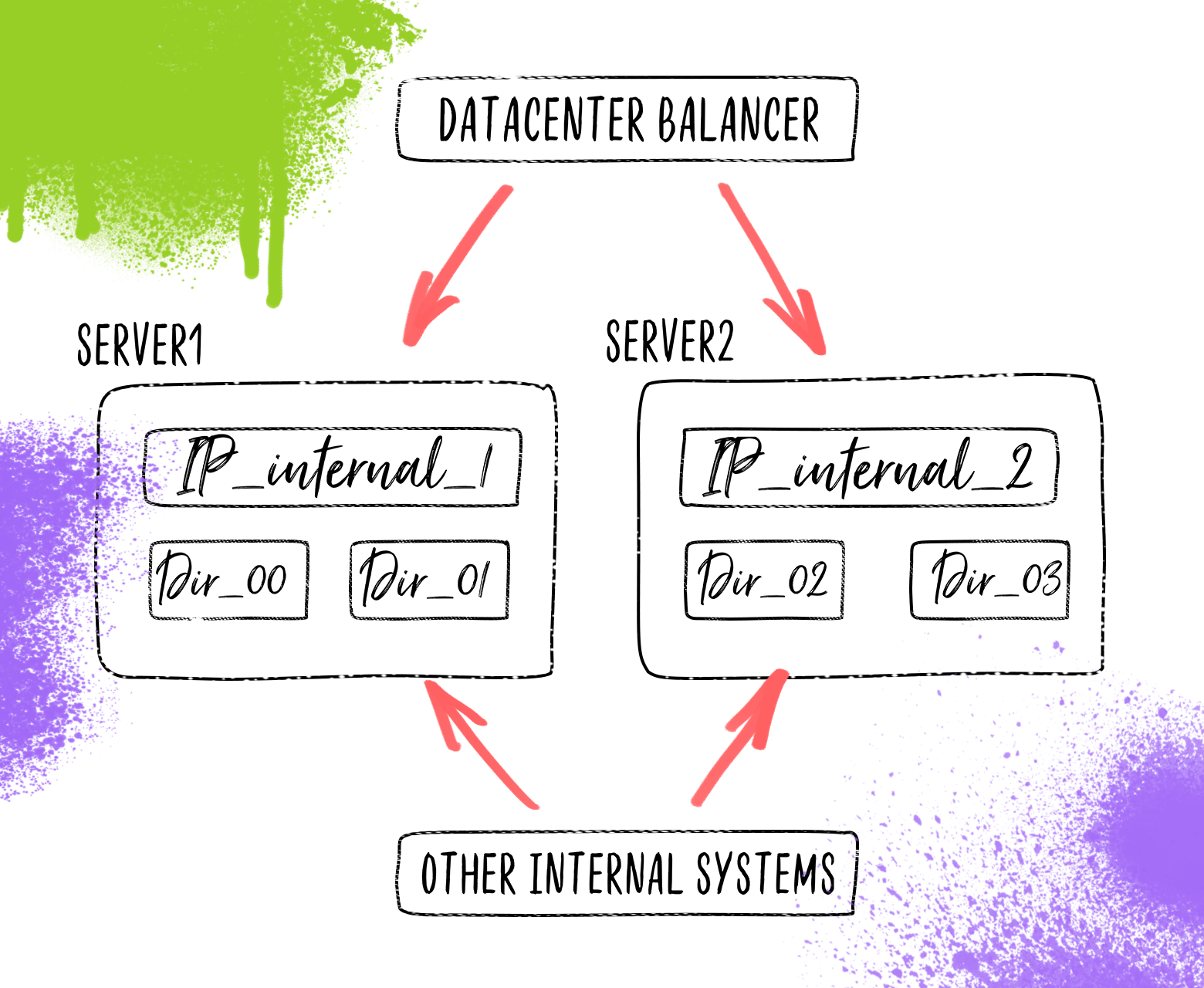
На изображении для упрощения показаны только четыре ноды на двух серверах.
В ходе обсуждения пришли к такой схеме. Файлы будут храниться в таком же дереве каталогов, но каталоги верхнего уровня распределены по группе серверов. Нужно сказать, что к тому времени у нас скопились сервера с одинаковой дисковой конфигурацией, диски на которых «простаивали». Отдаются файлы все тем же nginx. На каждом сервере подняты IP, которые соответствуют определенной директории верхнего уровня, находящейся на сервере. На тот момент мы не задумывались о балансировке трафика, так как за нас это делал дата-центр. Логика балансировки была в том, что в зависимости от домена, на который пришел запрос (всего было 100 доменов) отправлять запрос на внутренний IP, который уже был на нужном сервере.
Возник вопрос, как же код сайта будет загружать картинки в хранилище, если оно к тому же распределено по разным серверам. Логично было использовать тот же http протокол, по которому файл и пришел к нам от пользователя. Начали искать, что мы можем использовать в качестве сервиса, который будет принимать файлы на стороне сервера, который хранит файлы. Взор упал на открытый модуль nginx для аплоада файла. Однако, в ходе его изучения выяснилось, что логика его работы не укладывается в нашу схему. Но ведь это open source, а у нас есть опыт программирования на С. В течение недолгого времени, в перерывах между другими задачами, модуль был доработан и теперь, работая в составе nginx, принимал файлы и сохранял их в нужную директорию. Забегая вперед, скажу, что в процессе работы в production выявилась утечка памяти, которую на первых порах лечили перезапуском по ночам, а после, когда было время, нашли причину и исправили.
Нагрузки растут
Со временем мы стали использовать это хранилище не только для картинок, но и для других статических файлов, гибко настраивая с помощью nginx параметры, влияющие на производительность и доступ к файлам.
По мере роста количества запросов и объема данных мы сталкивались (а иногда и предвидели заранее) с рядом проблем, которые в условиях высоких нагрузок требовали принятия быстрых и эффективных решений.
Одной из таких проблем стала балансировка, которую нам предоставлял дата-центр, на F5 Viprion load balancer. Мы решили убрать его из пути обработки трафика с помощью выделения 100 внешних IP (по одному на каждую ноду). Так мы убрали узкое место, ускорили доставку данных и повысили надежность.
Количество файлов в одной директории все возрастало, что влекло за собой замедление компонентов из-за увеличившегося времени чтения содержимого директорий. В ответ мы добавили еще один уровень из 100 директорий. Мы получили 100^3 = 1M директорий на каждую ноду хранения и возросшую общую скорость работы.
Мы очень много экспериментировали с оптимальной настройкой nginx и параметров дискового кэша. По той картине, что мы наблюдали, у нас было впечатление, что дисковый кэш не дает полной отдачи от кеширования, а кеширование с nginx в tmpfs работает лучше, но очистка его кэша заметно нагружает систему в пиковые часы. Первым делом мы включили логирование запросов nginx в файл и написали свой демон, который поздно вечером считывал этот файл, очищал его, выявлял наиболее актуальные файлы, и очищал из кэша остальные. Таким образом мы ограничили очистку кэша ночным периодом, когда нагрузка на систему не велика. Это работало вполне успешно какой-то период, до определенного уровня нагрузки. Построение статистики и очистка кэша перестали укладываться в ночной интервал, к тому же было видно, что место на дисках в скором будущем подойдет к концу.
Решили организовать второй уровень хранения данных, аналогичный первому, но с некоторым отличиями:
- раз в 50 больше размер дисковой подсистемы на каждом сервере; при этом скорость дисков может быть меньше.
- на порядок меньшее количество серверов
- внешний доступ к файлам возможен только посредством проксирования через первый уровень
Это дало нам возможности:
- более гибко настраивать параметры кэширования
- использовать более дешевое оборудование для хранения основной части данных
- еще проще масштабировать систему в будущем
Однако это потребовало некоторого усложнения конфигурации системы и кода по загрузке новых файлов в систему хранения.
На схеме ниже показано, как могут размещаться две ноды хранилища (00 и 01) на двух уровнях хранения, используя один сервер на первом уровне и один на втором. Понятно, что можно размещать разное количество нод на сервере, и кол-во серверов на каждом уровне хранения может быть от одного до ста. Все ноды и серверы на схеме не показаны для упрощения.

На изображении для упрощения показаны только две ноды на двух серверах
Вывод
Что мы получили в итоге? Систему хранения статических файлов, в которой может без труда разобраться специалист среднего уровня, построенную на надежных, проверенных открытых элементах, которые при необходимости можно заменить или доработать небольшой ценой. При этом система может выдавать пользователям десятки PB данных в сутки и хранить сотни терабайт данных.
Минусы тоже есть. Например, отсутствие репликации данных, полной защищенности от отказа оборудования. И хотя первоначально, при проектировании системы, это было сразу определено и согласовано в соответствии с оценкой рисков, мы имеем набор дополнительных средств, которые позволяют нивелировать эти минусы (система бэкапов, скрипты для тестирования, восстановления, синхронизации, перемещения и т.п.)
В дальнейших планах добавить возможность гибко настраивать репликацию для части файлов, скорее всего через некую отложенную очередь.
Я сознательно не углублялся в детали реализации, логики работы (о кое-чем совсем не сказано), нюансы настройки, чтобы не затягивать статью и донести главную мысль: если хотите построить хорошую крепкую систему, то одним из правильных путей может быть использование открытых проверенных продуктов, связанных в относительно простую и надежную схему. Нормально делай, нормально будет!
